유사 화장품 추천 프로젝트
유사도 측정 2 🗂📊🧑🏻💻
📝 목차
- 유사도 측정
1-1. Using Faiss
1-2. vs Count-Based- 평가 및 결론
2-1. 평가 기준
2-2. 평가 방법
2-3. 평가 결과
2-4. 결론
1. 유사도 측정
1-1. Using Faiss
📌 Faiss
Faiss는 Facebook에서 고차원 벡터의 유사도 측정, 클러스터링을 위해 고안한 라이브러리다.
자세한 설명은 Faiss를 활용한 고차원 벡터 유사도 구하기에 적어놨다.
import pandas as pd
import numpy as np
import faiss
from tqdm import tqdm_notebook
import warnings
warnings.filterwarnings('ignore')먼저, 모듈부터 불러오고
def get_vector(idx):
return pd.Series(test.iloc[idx].to_numpy())[0], pd.Series((test.iloc[idx].to_numpy())[1:]) # Product Nxme, Vec벡터 데이터프레임에서 제품명과 벡터값을 return 하는 함수를 만들었다.
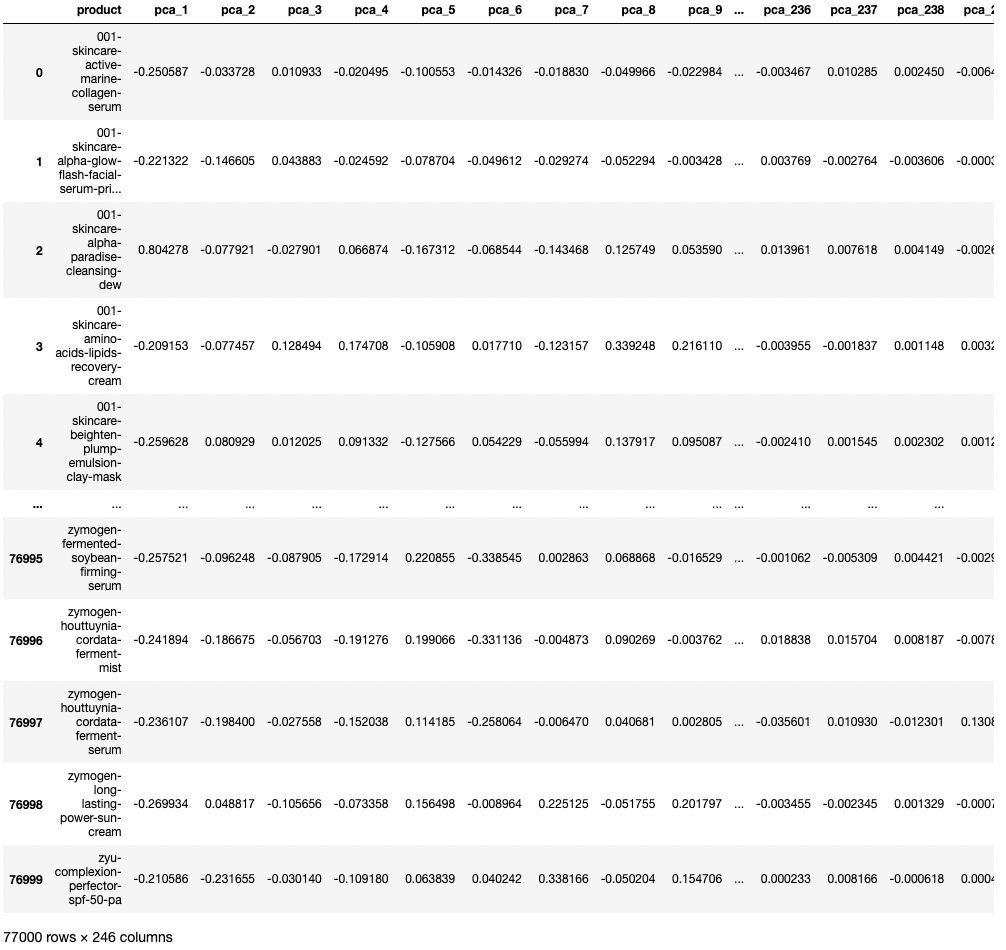
벡터값은 지난 번에 만들었던 77,000 X PCA245 차원의 데이터프레임에서 추출
vector = []
for i in tqdm_notebook(range(77000)):
_, vec = get_vector(i)
vector.append(np.array(vec))
vector = np.array(vector)
vector = vector.astype('float32')77,000개의 제품에 대해 벡터값을 받아와 vector 리스트에 임시 저장
이후 vector 리스트를 numpy의 array로 바꾸고 데이터 타입을 float32로 변환
index = faiss.IndexFlatIP(vector.shape[1]) # index 차원 15186
faiss.normalize_L2(vector) # 기존의 vecotr normalize_L2 (for cosine)
index.add(vector) # 15186 dim index에 vecotr add -> 이 index로 비교할거
distances, indices = index.search(vector, 6) # index로 vector(7000X15186) 돌면서 가장 가까운 6개만..(본인도 포함이라서 Top5를 뽑고 싶으면 5+1)Cosine Similarity를 위해 Faiss의 Index 중 IndexFlatIP를 선택했다.
Index에 vector를 넣기 전에 L2로 normalize 해주고 vector를 add
search로 탐색을 시작하면,
- distances에는 유사한 결과값들의 코사인 유사도
- indices에는 해당 결과값들의 인덱스 번호
가 추출될 것이다.
from collections import defaultdict
result = defaultdict(int)
for num in tqdm_notebook(range(77000)):
pname = test.iloc[num,:]['product']
similar = []
for idx, loc in enumerate(indices[num][1:]):
similar.append((test.iloc[loc,:]['product'], distances[num][idx+1]))
result[pname] = similar결과값을 확인하기 위해 result라는 defaultdict을 만들었다.
Key는 제품명, Value는 (결과값 제품명, 코사인 유사도) Pair
pca245_top5 = pd.DataFrame(columns=['product','prediction','cos'])
# pca245
for k, v in tqdm_notebook(result.items()):
for p in v:
tmp = [k]
tmp.extend(list(p))
df_len = len(pca245_top5)
pca245_top5.loc[df_len] = tmp
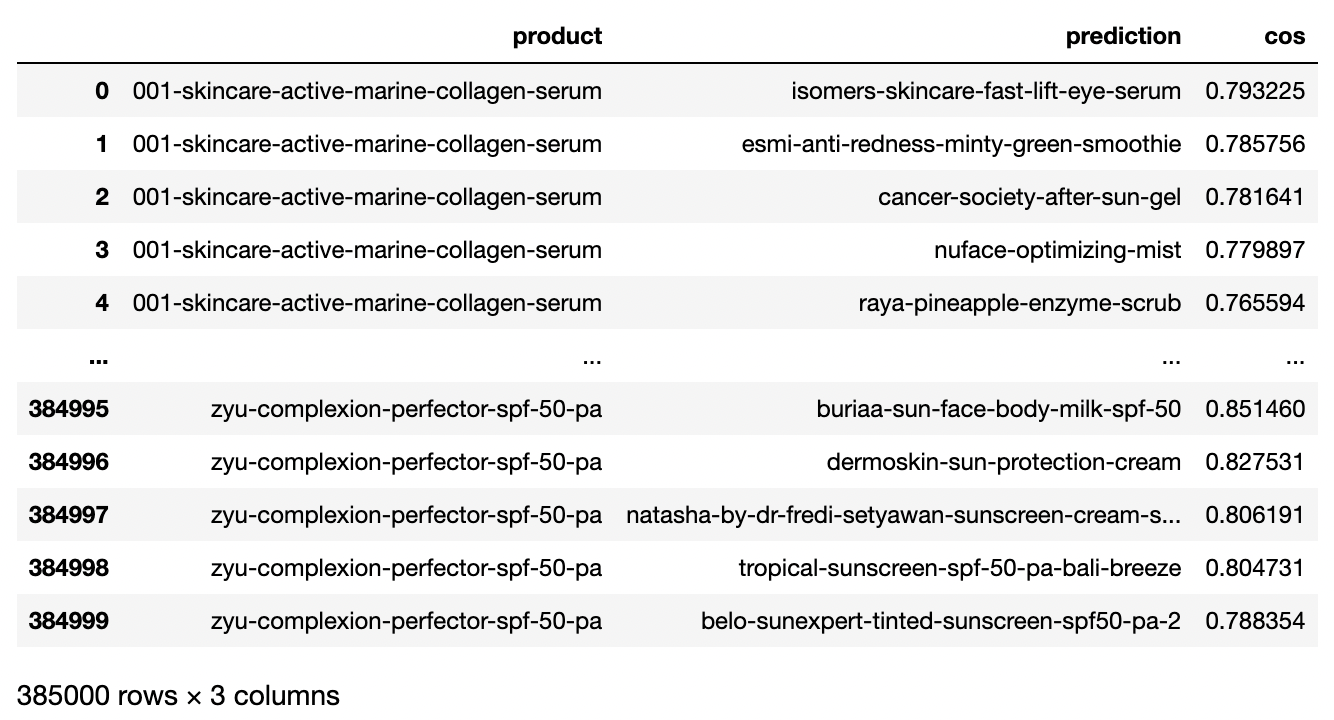
pca245_top5각 제품별로 가장 유사한 제품 5개씩을 추출한 데이터프레임으로 완성해서
결과를 살펴보면 아래와 같다.
1-2. vs Count-Based
Count-Based Matrix에서 테스트했던 joah-skin사의 peel-off mask를 동일하게 사용했다.
Inverse Matrix에서의 결과값과 비교해보자.
pca245_top5[pca245_top5['product'] == 'joah-skin-polish-gold-peel-off-mask']코드로 확인한 결과값부터 보자.
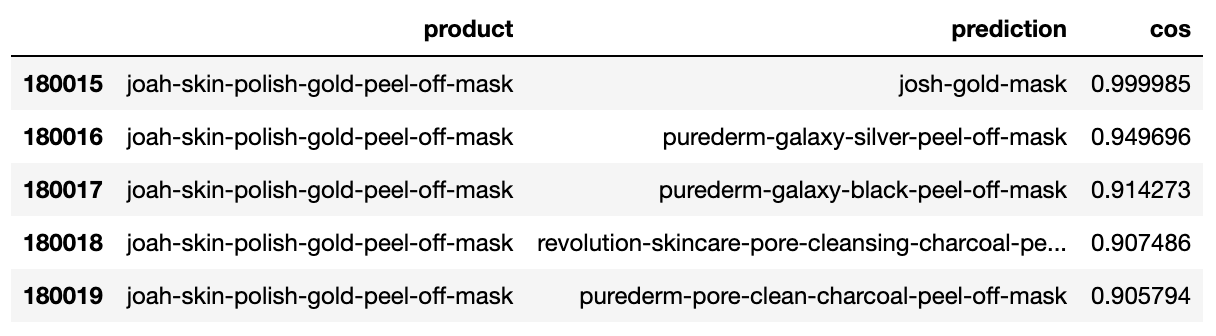
가장 높은 유사도를 보인 josh사의 gold-mask를 Count-Based Matrix 결과값과 비교했다.
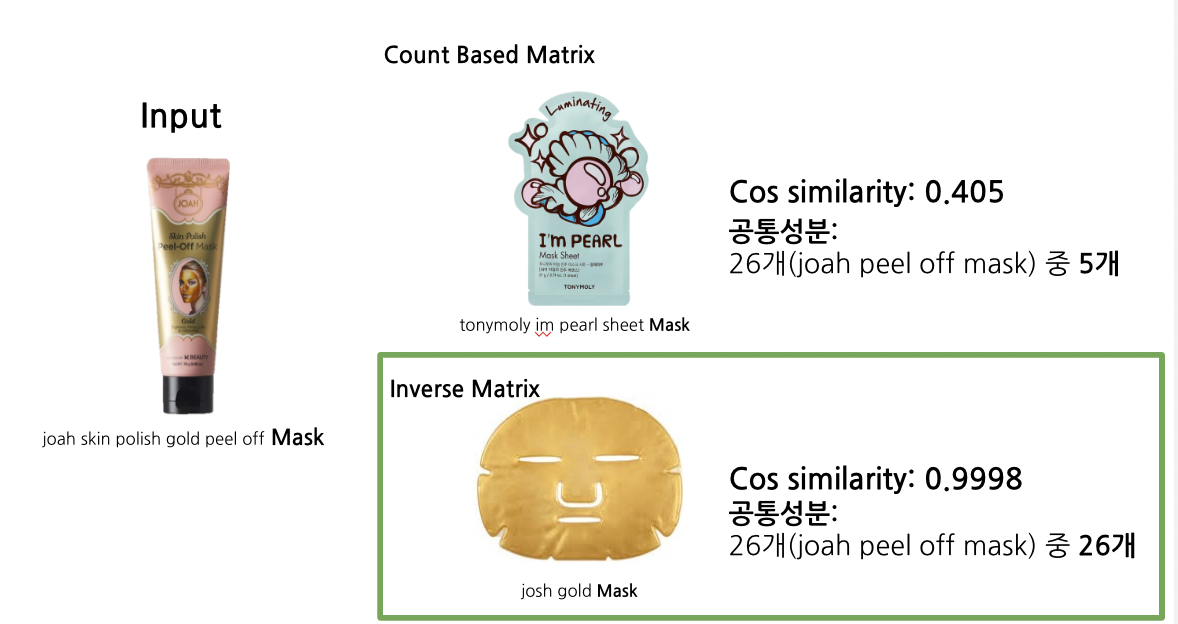
자카드 계수에서 도출한 결과값과 동일한 제품이다.
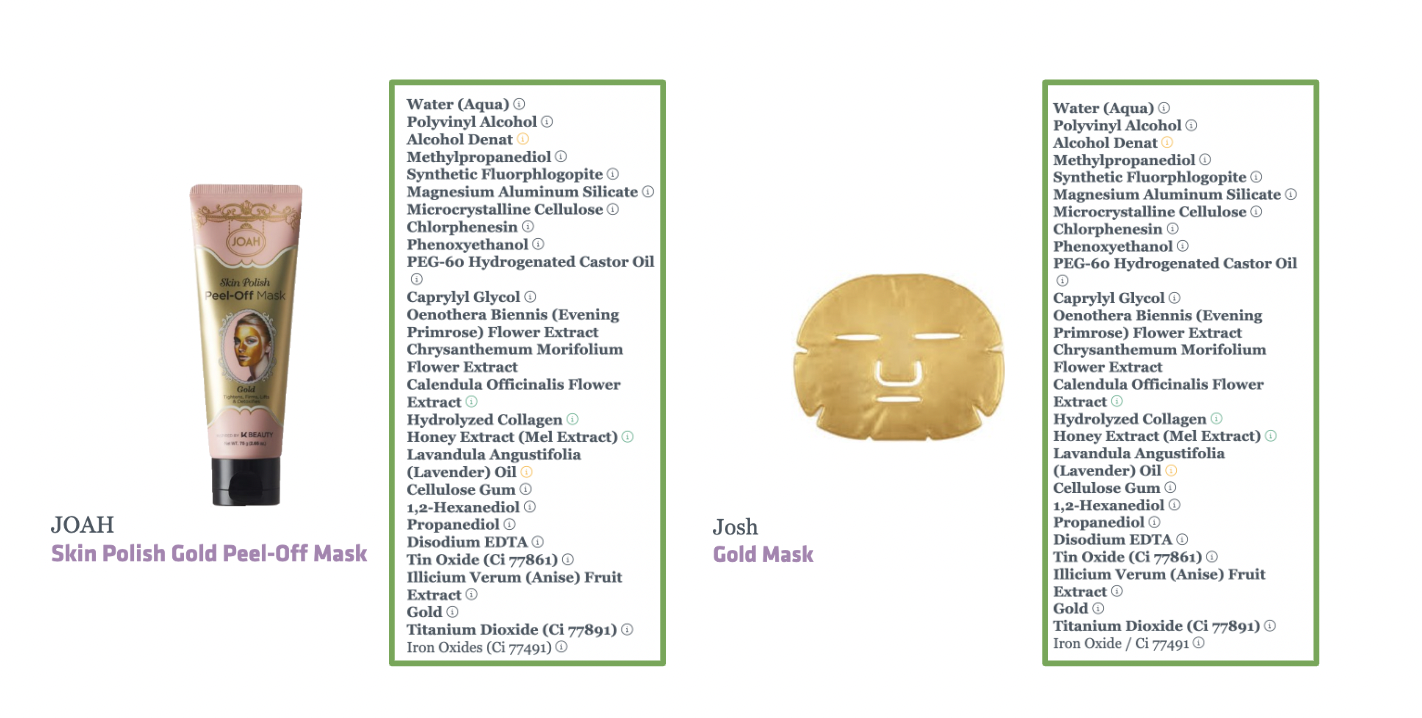
같은 유형의 peel-off 제품은 아니지만 성분 면에서 모두 일치한다.
2. 평가 및 결론
2-1. 평가 기준
Cosine Similarity로 결과는 나왔는데, 결과값이 정말 유사한지 아닌지를 판별할 필요가 있었다.
본인 포함하여 프로젝트를 진행한 인원들이 화장품 전문가가 아니었으므로 정확한 평가 기준은 세우지 못했다.
다만 서로 머리를 맞대고 고민하여 다음과 같은 결정트리 모형의 평가기준표를 만들었다.
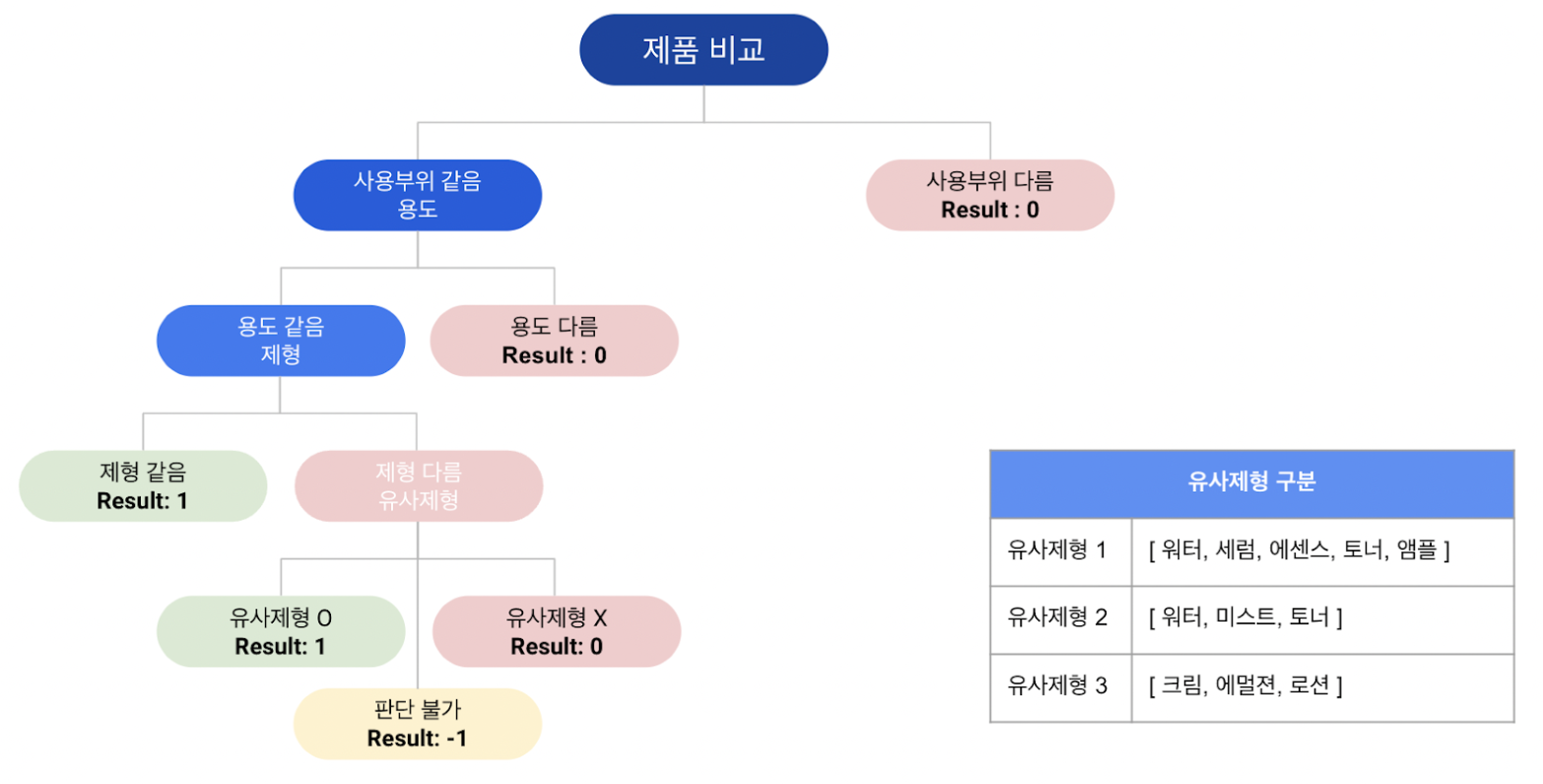
그리고 Cosine Similarity를 기준으로 세 가지 구간을 설정하여, 구간별 정확도를 확인하고자 했다.
pca245_top5[pca245_top5['cos'] < 0.6]
pca245_top5[(pca245_top5['cos'] >= 0.6) & (pca245_top5['cos'] < 0.9)]
pca245_top5[pca245_top5['cos'] >= 0.9]Cosine Similarity가 가장 낮은 결과값을 확인했을 때 0.5 근처였다.
그래서 임의로
- 0.6 미만 (0.03%)
- 0.6 이상 0.9 미만 (61%)
- 0.9 이상 (38%)
의 세가지 구간을 설정하여 그 비율을 확인했다.
임의로 설정한 구간이었지만 비율이 나쁘지 않아 이대로 진행했다.
2-2. 평가 방법
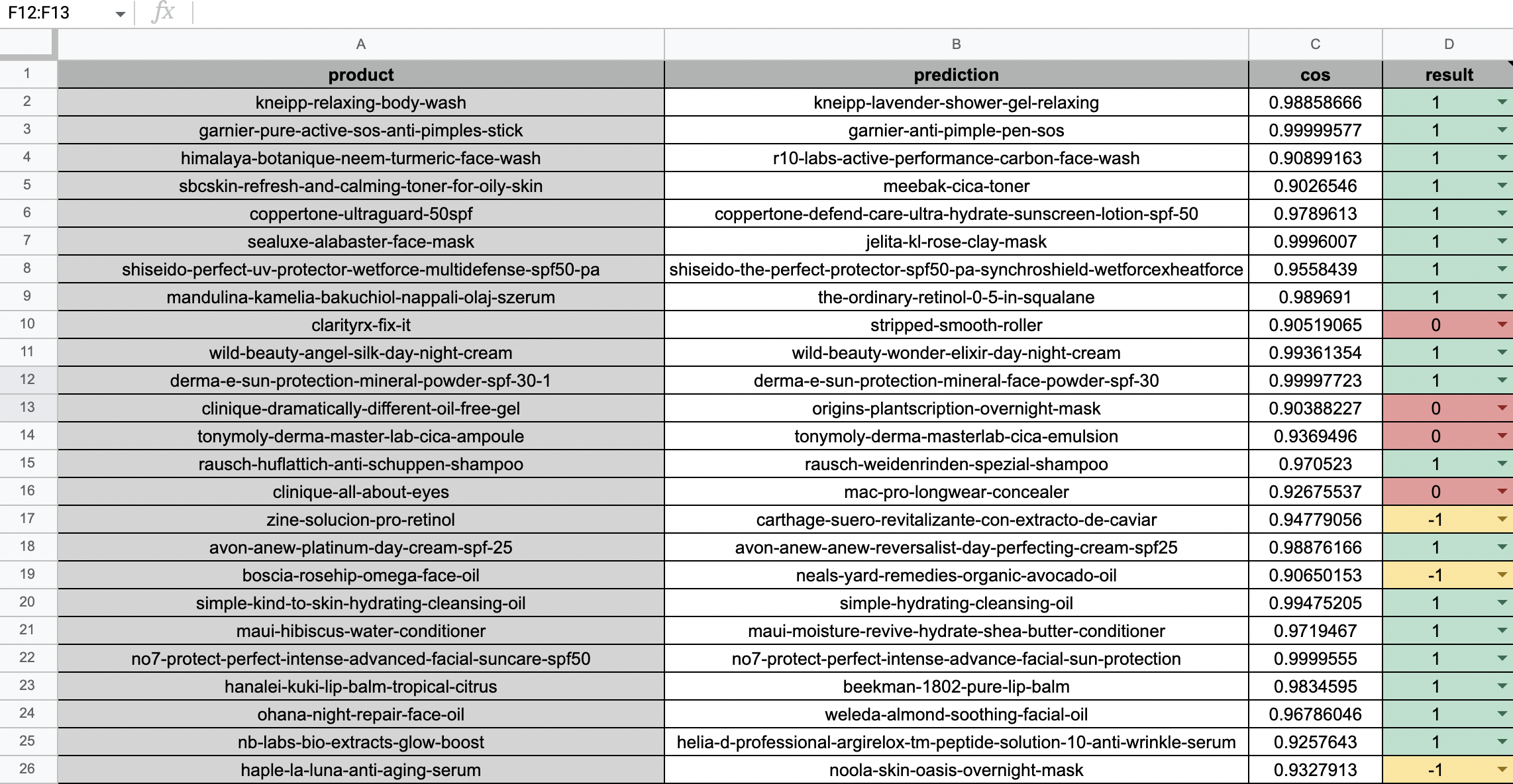
평가는 구간 별로 데이터를 100개씩 샘플링하여 직접 비교했다.
https://incidecoder.com/
데이터를 수집해온 incidecoder 웹페이지를 이용했다.
incidecoder에 compare-products 기능이 있어, 이를 활용했다.
위에서 선정한 평가기준에 맞추어
- 유사하다 1
- 유사하지 않다 0
- 판단 불가 -1
로 레이블링하였다.
정확도는 판단불가를 제외한 전체 대비 유사하다의 비율로 책정했다. ( 1 / (0 + 1) )
2-3. 평가 결과

전체 구간 기준으로 54%의 정확도를 보였다.
이 때, 구간 별 편차가 있음을 확인했는데
특히 Cosine Similarity 0.9 이상인 경우에 정확도가 64%까지 증가했다.
전체적으로 Cosine Similarity와 정확도는 정비례하는 양상을 보였다.
2-4. 결론
💡 전성분만으로 유사한 화장품을 추출하기 💡 라는 목표의 이번 프로젝트는 현재 단계에서 마무리 하기로 했다. 분명 괜찮은 결과를 보인 케이스도 존재했지만, 그렇지 못한 케이스가 대다수였다.
특히 웹상에서 구해온 무료의(?)의 데이터에서 한계를 느꼈다.
또한, 화장품 분야의 Domain Knowledge가 없기 때문에 정확도가 떨어지는 이유를 추측하기가 어려웠다.
하지만 본 프로젝트의 목표는 텍스트 데이터를 벡터화하여 그 유사도를 측정하는 것이었다. 이 작업을 수행해보고 결과까지 도출해본 것에 의의를 두며 이번 프로젝트는 여기서 마무리!
