[Paper Review]TALLRec: An Effective and Efficient Tuning Framework to Align Large Language Model with Recommendation
Recommender System

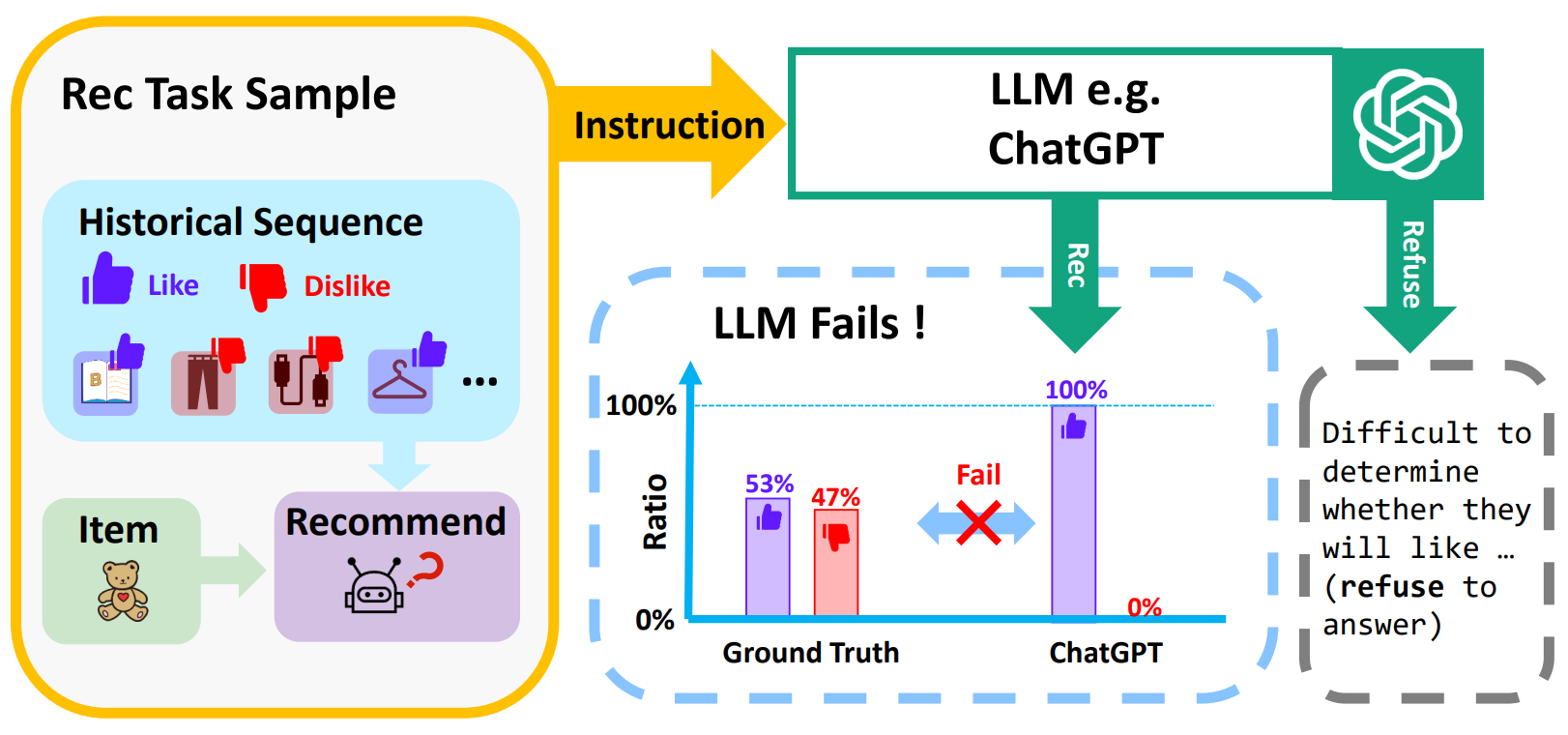
Introduction
-
LLM의 능력은 추천 시스템에서 요구되는 일반화 능력과 풍부한 지식을 요하는 문제를 해결하기에 적합함.
-
추천 시스템은 사용자와 항목 간의 상호작용을 통해 사용자에게 관련성 높은 항목을 추천하는 것이 목표임. 전통적으로 content-based filtering, collaborative filering, hybrid 접근법 등 다양한 기법이 있어왔다. -> 그러나 data sparsity, cold-start problem, domain generalization이 잘 되지않는 한계점이 있었음.
-
그래서 추천시스템에 LLM을 도입하여 LLM의 언어적 지식, 추론 능력, 높은 작업 정응력을 활용하고자 함.
-
본 논문에서는 아래 두 가지 문제를 해결하는 데 초점을 맞춤.
- LLM이 추천 시스템의 본질적인 구성 요소를 효과적으로 학습할 수 있도록 설계하는 법
- 다양한 시나리오에 맞는 유연한 추천 능력을 LLM이 수행할 수 있도록 하는 학습전략.
- 따라서 본 논문에서는 아래와 같은 접근을 취함.
- 사용자-항목 이중 정보에 기반한 다중 입력 프롬프트 생성
- 사용자 피드백 시뮬레이션을 통한 학습 데이터 확장
- 멀티 태스크 학습과 지식 주입 기반의 LLM fine tuning
- 결과적으로 LLM이 추천에서 기존 모델보다 우위에 있음을 실험적으로 입증하였고, LLM 중심의 추천 시스템 설계에 있어 중요한 인사이트를 제공함.
Methodology
Preliminary
Instruction Tuning
흔히 아는 내용이므로 생략하겠다.
Rec-tuning Task Formulation
-
본 논문에서는 LLM을 이라 정의하고, 사용자가 새로운 아이템을 좋아할지 여부를 예측하는 추천 특화 언어모델인 (LRLM )을 구축하고자 함.
-
추천 데이터를 활용하여 LLM에 recommendation tuning (rec-tuning)을 수행함. -> 추천 데이터를 instruction tuning 패턴에 맞춰 포맷을 구성함. 이때 모델에게 사용자의 interaction history를 기반으로 대상 아이템을 좋아할지를 판단하도록 지시하여 Yes, No로 이진 응답을 유도하도록 Task Instructoin을 작성함.
-
또한 Task Input을 구성함. -> 사용자의 interaction history items를 평점 기준으로 나눠서 liked items, disliked items 두 그룹으로 분류함. 항목들은 상호작용 시간 순서에 따라 정렬되고, 텍스트 설명(예를들어 제목 및 간략한 소개)로 표현 됨.
-
마지막으로 Task Instruction과 Task Input을 결합하여 Instruction Input을 생성하여 Instruction Output을 Yes, No로 나오게 설정해서 rec-tuning 학습을 진행한다.
TALLRec Framework
-
TALLRec Framework는 추천 작업에 대해 LLM을 효과적이고, 효율적으로 alignment(정렬)시키는 것을 목표로 함. 특히 낮은 GPU 메모리 환경에서도 적용 가능하도록 설계됨. -> light한 구현이 가능한 두개의 TALLRec 튜닝 단계와 backbone 선택 전략을 제시함.
-
TallRec은 두 개의 튜닝 단계로 구성됨. -> alpaca tuning, rec-tuning인데, alpaca tuning은 LLM의 일반화 능력을 향상시키는 일반적인 학습 과정이고, 두 번째 단계는 Instruction Tuning 패턴을 모사하고 추천 작업에 LLM을 맞춤 튜닝 하는 것.
TALLRec Tuning Stages
-
Alpaca Tuning에서는 Alpaca project에서 제공하는 self-instruct 데이터를 사용해서 LLM을 훈련함.
-
Conditional Language Modeling Objective를 학습 목표로 사용함.
-> -
x, y는 각각 self-instruct 데이터의 Instruction Input이랑 Instructoin Output임
-
는 y의 t번째 토큰
-
는 t번째 이전까지의 모든 토큰
-
는 LLM 의 기존 파라미터
-
는 학습 데이터 셋
-
Rec-tuning 단계에서는 rec-tuning 샘플을 사용하여 LLM을 튜닝함. alpaca tuning이랑 유사하게 진행됨.
Lightweight Tuning
-
LLM 전체를 직접 튜닝하면 계산 비용이 크고 시간이 오래 걸리므로(최신 언어 모델은 과도하게 많은 파라미터를 가지고 있고, 정보가 low intrinsic dimension에 집중되어 있다) alpaca tuning, rec-tuning 모두 lightweight Tuning을 채택함. -> 모델 전체 튜닝하지 않고, 일부 파라미터만 조정하여 유사한 성능을 내겠다.
-
걍 LoRA 사용함 -> 사전 학습된 모델 파라미터 freeze, 각 트랜스포머 layer에 learnable한 low rank matrix 삽입
--> 원래 파라미터 유지, 추가 정보는 low rank matrix를 통해 효율적으로 모델에 흡수됨. -
최종 train obejective function
->
여기서
- : LoRA 파라미터
- : 고정된(pretrained) LLM의 기존 파라미터
- : LoRA로 확장된 확률 분포
- : 학습 데이터셋
- : 출력 시퀀스 의 번째 토큰
- : 이전까지의 모든 토큰
- 학습 중에는 LoRA 파라미터만 업데이트 됨. -> 전체 LLM 파라미터의 1/10^7으로 학습 가능함.
Backbone Selection
- 걍 closed source llm이랑 보안 관련하여 외부 API 사용하는 부분에 있어서 조심스러워서 open source llm을 기반으로 직접 파라미터 업데이트를 하는 방식을 채택함.
- 그래서 LLaMA기반의 LLM을 선택해서 실험을 진행함 -> 성능 우무 및 학습 데이터 공개의 이유
Conclusion & My Opinion
Conclusion
- 기존의 LLM도 추천 작업에서 성능이 낮음을 실험을 통해 확인함
- 이를 해결하기 위해, 두 단계 튜닝 방식 (alpaca tuning +rec-tuning)으로 구성된 TALLRec Framework를 제안함
- 제안된 framework은 기존 모델보다 높은 성능을 보였고, 도메인 간 일반화 능력도 우수함을 실험적으로 이증함.
- 향후 더큰 LLM의 추천 능력을 효율적으로 활성화 하고, 다중 추천 작업을 동시에 처리할 수 있는 튜닝 기법 개발이 목표임
My Opinion
강점
- 3090 1장으로 fine-tuning 가능 (LoRA)
- Alpaca self-instruct + rec-tuning으로 두 단계를 거쳐서 언어와 추천 도메인 간 간극을 축소시킴
- 영화, 도서 분야에서 100개 미만 학습 샘플로도 기존 LLM 대비하여 높은 성능향상을 보임
- 튜닝 후 cross-domain transfer에서도 준수한 성능을 보여줘서 일반화 능력이 좋음을 확인 함
약점 - 평가 범위가 아쉬움 -> 두 도메인, 이진 예측만 다뤘음 (랭킹 지표, 실험 데이터 부족)
- 본 논문이 나왔을 무렵의 최신 llm 기반 추천 모델과 직접 비교가 부족한 듯
- 멀티모달로서의 확장성 부족 -> 본 논문에서는 item title + 아이템 간략 설명 을 문자열로만 프롬프트에 넣어서 시각 및 수치 정보를 아에 폐기 함.
- Cold Start Problem -> 과거의 liked/disliked 히스토리를 사용하는데, 이 때 신규 유저 및 아이템은 정보가 부족하여 프롬프트 자체를 만들 수 없음
-> cold item embedding 생성해서 llm 프롬프트에 삽입 or LLM으로 초기 가짜 히스토리 부여 or 신규 사용자에게 선호 설문 -> 답변 즉시 LLM이 프롬프트화 해서 cold-start gap 축소 - 많은 사용자, 아이템 규모에서 학습 및 실시간 추론 지연에 대해 실험 부족
-> LoRA도 user item interection이 너무 많아지면 병목생김 - 사용자 히스토리를 프롬프트에 직접 노출한 부분이 아쉬움
- Alpaca tuning -> rec-tuning, LoRA에 대해서 ablation 존재X
아이디에이션
- 멀티모달 LoRA 텍스트 + 이미지 AdapterFusion 결합
- 대화형 RecSys RLHF 적용해서 multi turn으로 선호하는 것 탐색 및 설명
- KG 연결 -> item/user entity를 KG 임베딩하여 LoRA input에 넣어줌
- Explainable 한 추천 -> LoRA-tuned LLM으로 자연어 설명 + 근거 하이라이트 생성하여 사용자가 신뢰할 수 있게 함.
