[Paper Review]GPT4Rec: A Generative Framework for Personalized Recommendation and User Interests Interpretation
Recommender System
Introduction
-
NLP의 발전과 함께 NLP기반 추천 모델이 발전함.
-
그러나 기존의 NLP 기반 모델은 일반적으로 아이템을 단순한 ID로 취급하며 discriminative 모델링을 채택 함.
-> 아이템의 콘텐츠 정보, nlp모델의 LM 능력을 충분히 활용 못함.
-> 지속적인 변화를 보이는 아이템 인벤토리에 적용하지 못함.
-> discriminative model은 사용자의 관심사 해석이 어려움 (해석가능성이 떨어져서, 추천의 다양성과 품질을 향상시키지 못함) -
GPT4Rec을 제안하여, 사용자 관심사의 해석을 동시에 제공할 수 있게 함. (검색 엔진에서 영감을 받음)
-
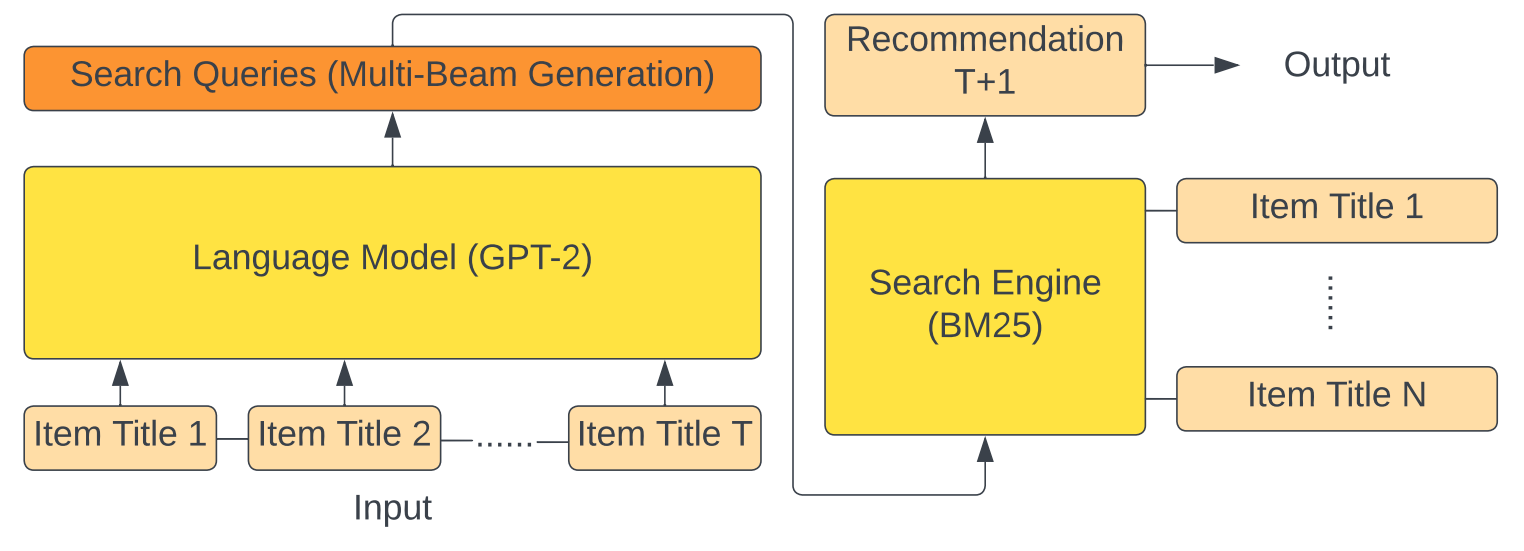
사용자의 히스토리에 포함된 아이템 제목들과 생성 프롬프트를 결합하여 생성형 언어 모델을 통해 가상의 검색 쿼리를 생성.
-
GPT4Rec은 생성된 쿼리를 검색 엔진에 입력하여 추천할 아이템 검색
-> 사용자와 아이템 임베딩을 언어 공간에서 학습하는 모델.
-> 아이템 제목에 담긴 의미 정보를 활용해서 사용자의 다양한 관심사를 포착할 수 있도록 함. -
사용자의 다중 관심사 해석 및 추천의 다양성을 높이기 위해, 쿼리 생성 과정에서 multi-query beam search를 채택함.
-
쿼리가 사람이 이해할 수 있는 형태로 표현되며, 사용자 관심사를 해석하는 데에도 사용함.
사용자 관심사를 표현하는 쿼리를 검색에서 사용해서 item cold start problem 및 아이템 인벤토리 변화 문제를 자연스럽게 해결함. -
GPT4Rec은 고도화된 LLM 또는 검색 엔진을 유연하게 통합할 수 있어, 성능 향상을 위해 실용적 이점도 가짐
Method
-
user item interaction sequence가 주어지면, GPT4Rec은 해당 item을 프롬프트와 함께 포맷팅하고, generative language model을 사용해서 언어의 차원에서 아이템과 사용자 임베딩을 학습함.
-> 이때 포매팅은 사용자의 구매 아이템 히스토리(item title)로 자연어 프롬프트를 구성하는 것임.Previously, the customer has bought:
<ITEM TITLE 1>. <ITEM TITLE 2>. ...
In the future, the customer wants to buy
->사용자 history 도입부
->item title: 사용자가 과거에 구매한 아이템들을 자연어 문장처럼 나열.
->다음 구매할 아이템을 생성하도록 하는 프롬프트
-포매팅 방식을 사용하여 기존의 ID 기반 시퀀스를 문장형태로 자연스럽게 만들어 GPT를 활용할 수 있게 한다.
-아이템의 semantic information를 보존.
-사용자 히스토리를 사람이 읽을 수 있는 형식으로 바꿔줘서 interpretable하게 함. -
이후 모델은 사용자의 관심사를 표현하는 query를 생성하고, 이 query를 BM25에 입력하여 추천할 아이템을 찾음.
-
본 논문에서는 GPT-2와 BM25를 채택하였음. -> 유연하게 발전된 모델을 갈아끼울 수 있게 함.
Query Generation with the Language Model
GPT4Rec은 여러 파트로 이루어져있는데, Language Model로 생성하는 것과 관련된 섹션이다.
- GPT-2(117M)를 사용하여 user interaction sequence로부터 사용자 표현을 언어 공간에서 학습하고, 사용자의 관심사를 나타내는 많은 쿼리를 생성한다.
- 위에서 설명한대로 모델 입력을 위해 포매팅을 하여 프롬프트 형식으로 입력한다. 프롬프트는 아이템 제목의 semantic information을 내포하고, 사용자별로 로 표현됨. -> GPT-2가 이 프롬프트를 입력으로 받아서 에 따라 쿼리를 생성함.
Multi Queries Beam Search
- multi Queries의 생성을 Beam Search로 수행하여 사용자의 다양한 관심사를 더 잘 표현하게 하고, 추천 결과의 다양성을 높임. -> 생성 점수 을 기반으로 길이 의 후보쿼리 를 다음과 같이 확장한다. 이때 m은 beam size
이렇게 해서 세부 수준(granularity)의 사용자 관심사 표현을 생성할 수 있게 함.
Item Retrieval with the Search Engine
두 번째 구성요소는 검색 엔진임.
- 검색 엔진은 각 쿼리를 입력받아, 가장 관련성 높은 아이템을 리턴하는 역할을 함. -> 벡터 기반 모델의 dot product similrarity와 비슷하게 언어 공간상의 similarity를 계산 함.
- 본 논문에서 BM25를 score function으로 채택함.
검색 결과 병합 방법
- 생성된 m개의 쿼리에 대해 각 쿼리에서 상위 K/m개의 아이템을 받음
- 첫 쿼리 에서 가장 높은 점수를 가진 아이템부터 받음.
- 이후 쿼리들에서는 중복을 피한 상위 아이템들을 순차적으로 추가하여 최종 Top-k 추천 리스트 구성
-> 이 방시그로 정확도(관련성)과 다양성 간의 균형을 유지하도록 설계 함.
Training Strategy
GPt4Rec은 언어 모델과 검색 엔진을 분리해서 2단계로 핛급함.
- GPT-2 fine tuning
* 사용자의 interaction sequence 에 대해, 앞의 T-1개의 아이템 title을 프롬프트로 사용하고 마지막 아이템 의 제목을 타깃으로 구성
-> Contrastive Learning에서 착안한 아이디어로, 가장 정확학 쿼리가 실제 타깃 아이템의 title이다라는 가정이 깔려있다. - BM25 Parameter Tuning
* 언어 모델 학습 후, 검색 성능 향상을 위해 BM25의 하이퍼파라미터 과 를 grid search로 최적화 함.
Experiements
Quantitative Analysis
- BERT4Rec은 language modeling을 이용하여 뛰어난 성능을 보였으나, 아이템을 ID로만 처리하는 한계가 있어서 콘텐츠 정보를 충분히 활용하지 못하였음
- ContentRec은 아이템 콘텐츠 정보를 bag-of-words 임베딩과 mean-pooling을 통해 사용했지만, 복잡한 표현력부족으로 성능을 내지못함.
- GPT4Rec은 모든 기준 모델보다 높은 Recall@k 성능을 달성함.
- 소규모일수록 성능 개선 폭이 큼 -> LLM의 표현력 이점이 부각됨.
- 성능 향상의 핵심은 콘텐츠 정보 활용 + 언어모델 구조 결합
Qualitative Analysis
이 섹션에서는 생성된 쿼리가 사용자의 관심사를 얼마나 잘 포착하고, 해석에 도움을 주는지를 case study를 통해 확인한다.
예시1: 다양한 관심사를 가진 사용자
테스트 사용자는 뷰티 제품에 대해 다양한 카테고리 및 브랜드에 관심있었는데, 이전에 나타난 적 없는 관련 아이템을 포함하는 다야한 쿼리를 생성하여 단순히 과거를 복제하는 것이 아니라 잠재적 관심사 확장도 모델이 수행했음을 볼 수 있음.
- 정성 분석을 통해 생성 쿼리가 해석 가능한 사용자 관심사 표현이라는 점이 드러남
- 히스토리에 없던 아이템가지 생성되어 잠재적 관심사도 포착 가능
- 모델은 브랜드, 제품군을 기반으로 사용자 맞춤형 쿼리 생성에 성공함

Conclusion 및 의견
Conclusoin
- GPT4Rec 프레임워크 제안
- 성능 향상
- 다중 쿼리 생성 기법 -> 사용자의 다양한 관심사와 세부 표현을 반영하여 정확성 + 다양성 측면에서 추천 품질을 높임
- 확장성 -> 최신화된 언어모델, 검색 엔진, 다양한 쿼리 전략과 유연하게 확장 가능
의견
장점
- 추천을 llm으로 생성 하는 부분에서 검색 하는 문제로 재해석 하여 새로운 시각을 보여준듯
- 아이템 제목에도 의미가 충분히 담겨 있을 수 있는데, 이전에는 그 내용을 사용하지 않았다면 이 논문에서는 아이템 제목의 의미 정보를 활용하여 language model이 알아들을 수 있게 활용함. -> cold-start, long-tail problem에 유리한듯
- Beam Search로 추출된 문구로 해석가능성
- 단순한 구성으로 당시 SOTA달성
단점
- BM25는 keywork 매칭 기반-> semantic recall 한계가 있을 수 있고, 동음이의, 문맥이 부적절한 케이스도 가능할듯
- 실시간 서비스를 한다면 응답 지연이 될수도 있을 듯함. Beam size X BM25
- End-to-End가 아니고 쿼리 생성과 검색이 독립적으로 학습되어서 최종 recall에 대해서 최적화 되었는지도 파악이 안됨
- 프롬프트 템플릿이 종류가 하나밖에 없는 것 같음 -> 도메인이나 언어가 바뀌면 어떻게 될지 모르겠음
의문
- 예시로 든 makeup palette와 같이 히스토리에 없는 토픽을 확장했을 때 과대 일반화로 인하여 관련성이 떨어지는 아이템을 늘릴수 있을 위험이 있지 않을까?
아이디어
- 검색 엔진으로 사용한 BM25 -> DPR, Reranker로 재정렬
- End-to-End 학습
- 고정된 프롬프트 -> Soft Prompt/Prefix-tuning 로 변경했을 때 도메인과 언어가 급변하였을 때 프롬프트 민감성을 낮추고, computing source를 줄일 수 있음
- multi modal 확장 -> 평소에도 관심 있던 부분인데, 아이템의 이미지+텍스트를 활용하여 혼합한 검색을 할 수 있으면 좋을 것 같음
