자연어처리
1.Review(리뷰) - A survey of PLM based Text Generation
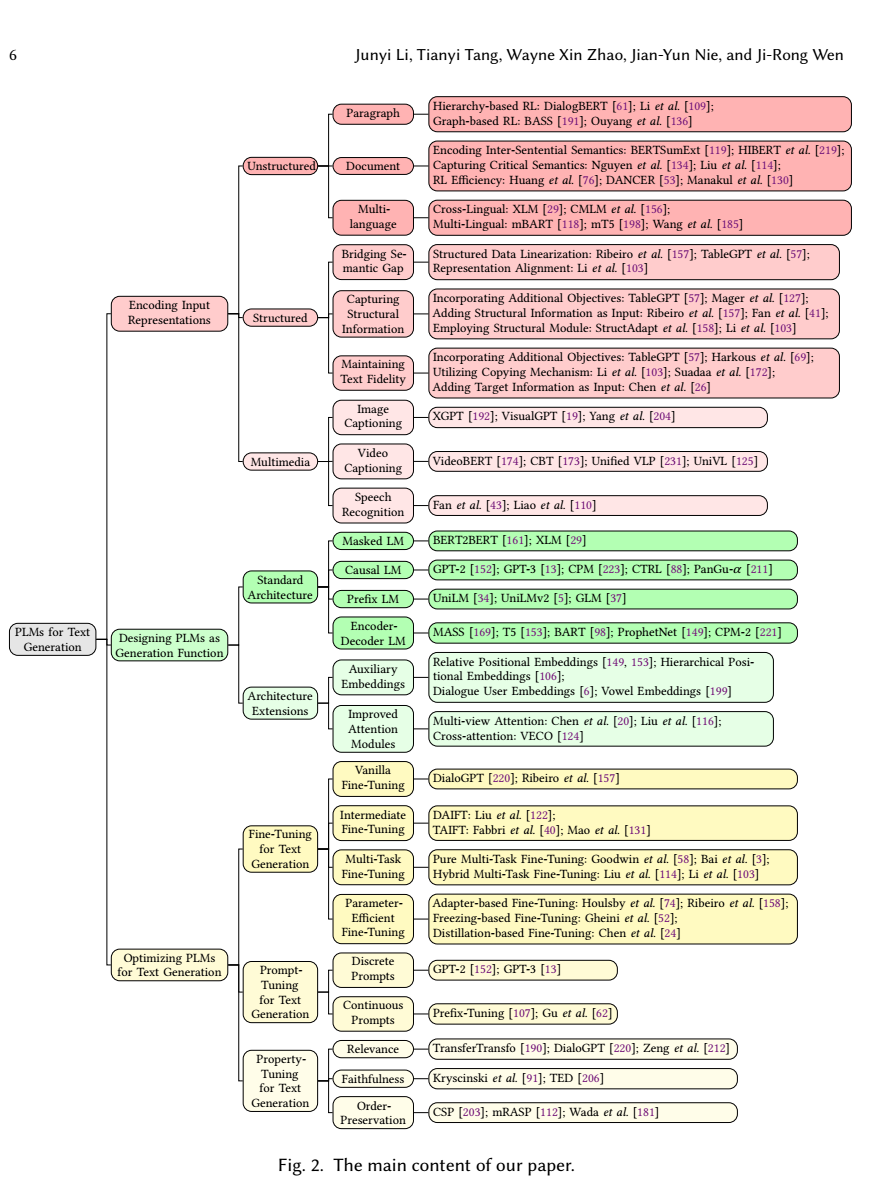
이 페이퍼는 text-generation에 관한 내용을 pretrained-language model 중심으로 다룬 내용 - 여러가지 연구 흐름을 파악하기 용이함필자의 기존 지식과 논문의 내용을 기반해서 요약을 해봄서두1\. 텍스트 생성이란 데이터로부터 자연스러운 말을
2022년 1월 21일
2.리뷰-albert: A lite BERT
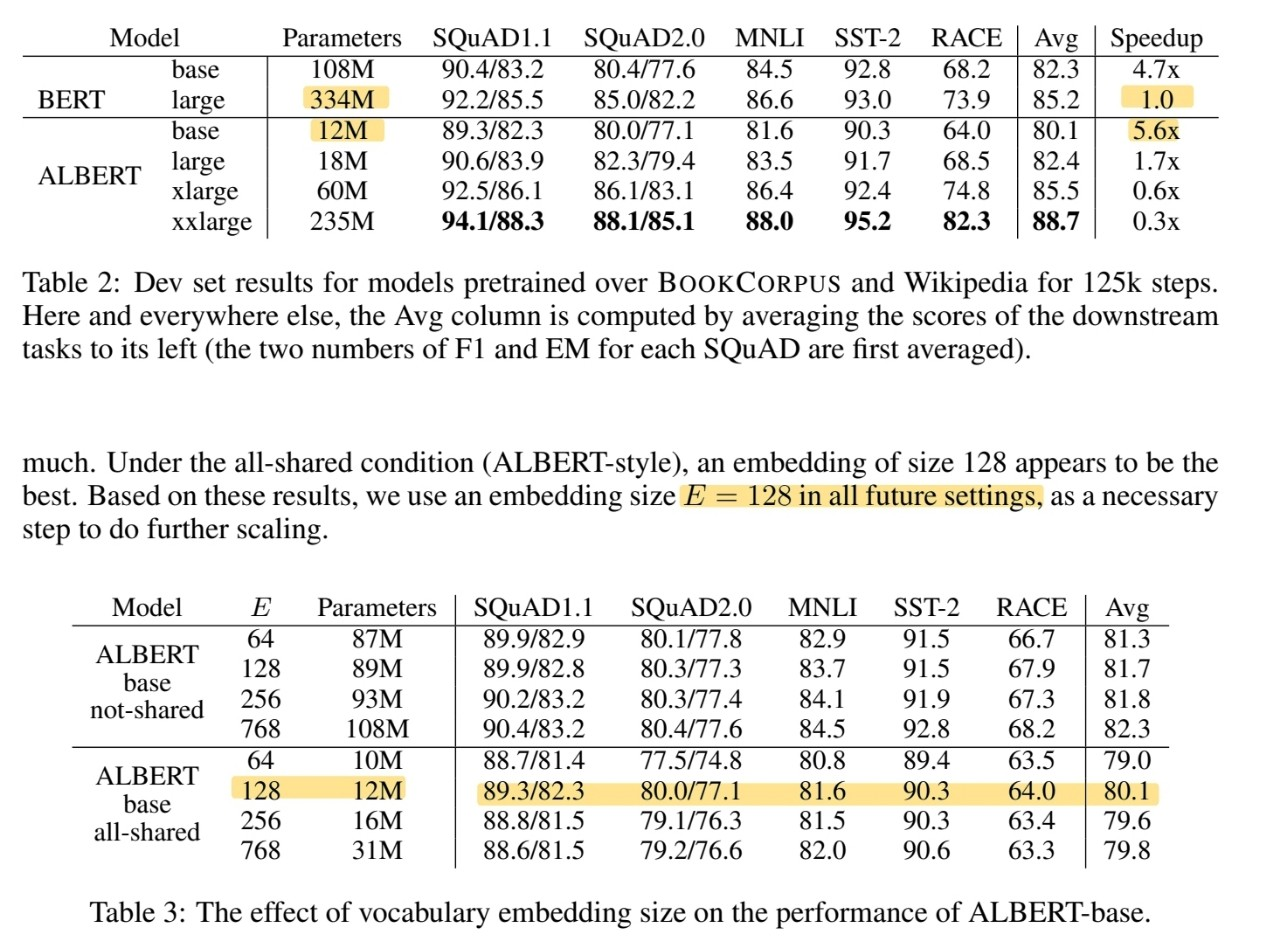
이 논문은 앞으로 gpu 메모리 한계와 긴 training 학습의 한계점이 올 것이라고 예측을 하고, 이러한 문제를 해결하기 위한 두가지의 파라미터 축소 방법을 제공을 한다. 이를 통해 적은 메모리 사용과 학습 시간을 빠르게 가져갈 수 있는 이점을 가진다.제시할 두 가
2022년 1월 11일
3.Few-Shot Learning
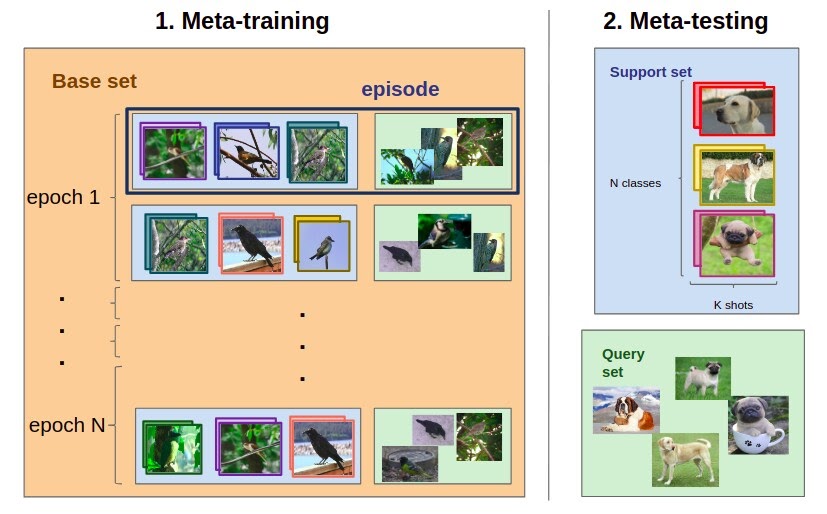
인간은 사진 몇 장만 가지고 대충 감을 잡아서 예측을 한다. 그러면 인공지능도 수백장을 사용한 fine-tuning없이도 그러한 것을 할 수 있지 않을까? 이러한 철학에서 연구되는 분야가 few-shot learning이다. Training set, Support se
2022년 1월 4일
4.2021 자연어처리 트렌드

언어를 의사소통수단으로 보는 관점과 internal though로 보는 관점 두 개가 존재한다. EMNLP2021 콘퍼런스에서 Fedorenko’의 FMRI에 기반한 연구에 따르면, 언어는 일종의 predictive한 것으로써, 추론 시스템과 언어 시스템은 분리가 되어
2021년 12월 31일