abstract
이 논문은 앞으로 gpu 메모리 한계와 긴 training 학습의 한계점이 올 것이라고 예측을 하고, 이러한 문제를 해결하기 위한 두가지의 파라미터 축소 방법을 제공을 한다. 이를 통해 적은 메모리 사용과 학습 시간을 빠르게 가져갈 수 있는 이점을 가진다.
introduction
제시할 두 가지 테크닉 중 하나는 행렬 특잇값 분해와 레이어 간 파라미터 공유이다. 또한 버트의 NSP를 개선한 SOP를 제시해서 문장 간의 결합성을 판단하는 것을 학습하도록 한다.
related work
인공지능 자연어 연구가 메모리 문제로 hidden size를 1024에서 키우지 못하고 있다.
그래서 cross-layer parameter sharing이라는 weight를 어텐션만 공유하는 방법, 전체 레이어를 공유하는 방법, 그룹으로 지정해서 공유하는 방법 등을 실험해서 결과를 내보았다.
sentence orering objectives라는 SOP 기법을 제시해서, 문장의 순서가 적합한 지 판단하는 학습 목적을 제시했다.
Elements of ALBERT
transformer encoder를 사용했고, 활성함수를 GELU를 이용했다.
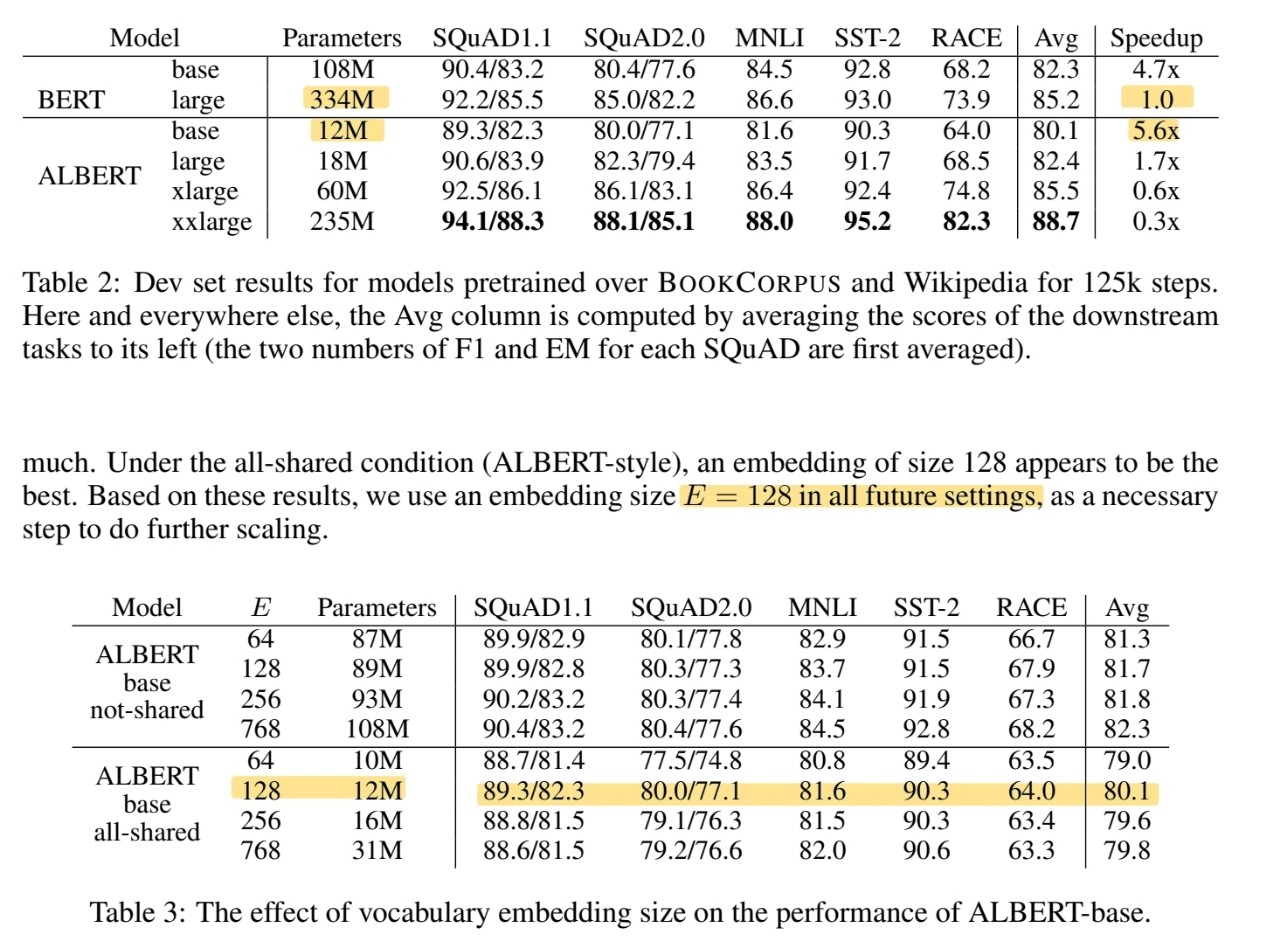
embedding 레이어를 factorization을 통해 두 가지로 분류했다. 그러한 이유는 임베딩 레이어는 context-independent하게 배우도록 학습하고, hidden 임베딩 렝이어는 context-dependent하게 배우도록 학습해야하는데, 원래 임베딩 벡터는 두 개를 달성하기 힘들기 때문이다.
레이어간 파라미터 공유는 버트보다 파라미터 수를 획기적으로 줄이고 더 높은 안정성을 확보할 수 있게 했다.
SOP는 inter-sentence coherence를 배우기 위한 loss이고, NSP의 비효율성을 개선하기 위해 고안했다.
Experiment results
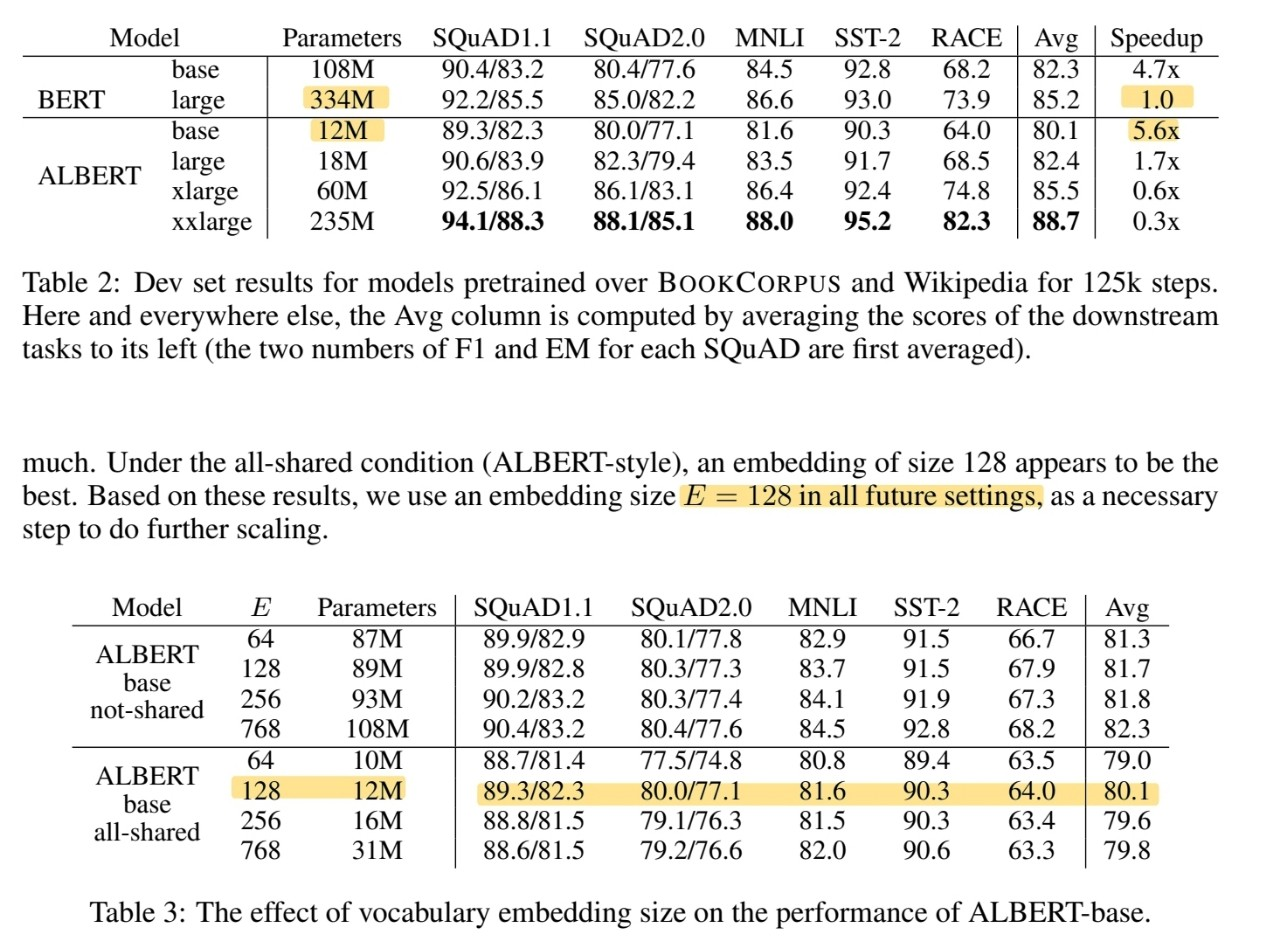
히든 사이즈를 버트와 똑같이 했을 때, 버트는 334M이라면 albert는 18M으로 대폭 파라미터를 감소했다.
흠.. training 시간은 좀 길지만 비슷한 성능대비 파라미터수는 확실히 많이 감소했다.
파라미터 레이어 공유를 할 때, fc는 공유를 했을 때 성능이 대폭 감소하였으며, attention layer를 공유하는 것은 큰 차이가 없었다. 또한 그룹 공유를 했을 때, 그룹내에 속해있는 레이어의 수가 적을 수록 성능이 좋았다.
SOP를 했을 경우 성능이 특히 RACE에서 더 좋아졌다.
데이터를 더 넣어 줄 경우, dropout을 제거해야 성능이 개선되었다. 기존 연구에서 batch normalization과 dropout을 같이 쓰면 성능이 오히려 감소한다는 것을 밝혔었는데, 그러한 것이 albert에도 적용되는지 실험 중이다.
Discussion
앞으로 sparse attention, block attention과 같은 기법을 통해 albert의 추론과 학습의 시간을 개선해볼 것이다.
