seq2seq 구조
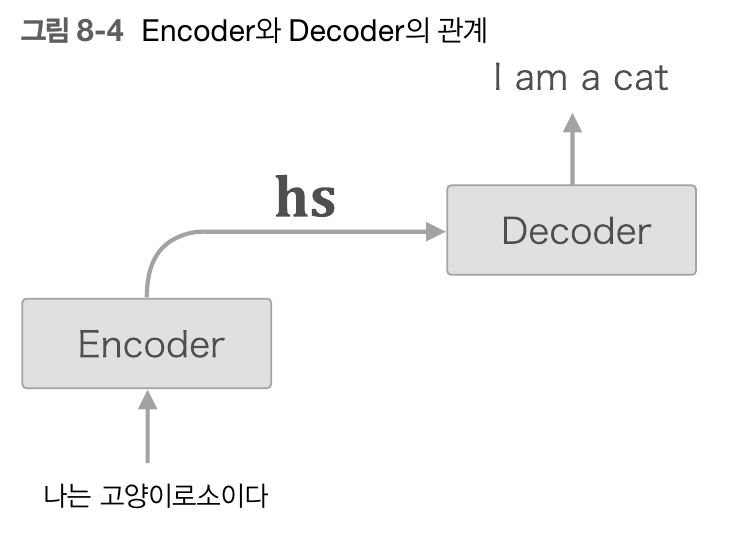
seq2seq 구조는 간단히 말해 어떤 문장이 입력으로 주어졌을 때 이를 번역해주는 모델이다. 구조에 대해 간단히 설명하면, encoder와 decoder를 연결시킨 구조라고 생각할 수 있다.
encoder와 decoder의 구조는 RNN(LSTM)을 T개만큼 쭉 늘어선 구조이다.
다만 Encoder에서 해독하고 싶은 문장 Word1, Word2..... WordT가 입력으로 들어오면 각각의 LSTM의 출력값 H1,H2,H3.... 는 버려지고 마지막 Ht값만 Decoder로 전달된다.
Decoder에서는 정답문장(해독된 문장) Word1, Word2... WordT가 입력으로 들어오고 첫번째 LSTM에서 이전의 Hprev는 Encoder의 마지막 출력값 Ht가 된다. 이때 각각의 출력값H1,H2..Ht를 Affine, Softmax로 출력해 문장을 출력하게 된다. 이것이 전체적인 seq2seq 구조이다.
Attention 구조
이때 이 seq2seq 구조에서 Ht는 고정길이 벡터이다. 이 고정길이 벡터를 사용할 때 문제점은, Encoder 파트의 문장의 길이가 길어지면 발생한다. 만약 매우 긴 문장이 Encoder에 들어왔을 경우, 이 긴 문장의 모든 정보를 고정길이 벡터에 축약 할 수 없게 된다. 따라서 이를 보완하기위해 이전의 seq2seq 구조의 encoder에서 버려졌던 h1,h2...ht-1들을 decoder에서 사용되도록 만드는것이 Attention 이라고 볼 수 있다. 그럼 이 Attention은 h1,h2,ht-1을 어떻게 사용할까
먼저 h1,h2,ht-1들을 한데 모아 hs 행렬을 만든다.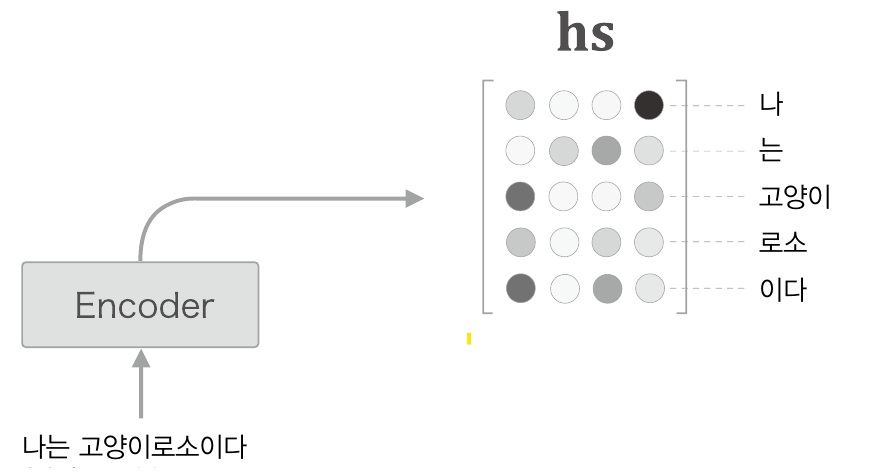
이때 이 hs 행렬에서 각 행은 해당 단어에 대한 벡터정보를 의미할 것이다. 엄밀히 따지면 LSTM 구조의 출력 결과이므로 해당 단어 이전 단어까지의 정보도 포함하고 있을 것이다. 즉 hs의 각행은 각각 나, 나는, 나는 고양이, 나는 고양이 로소, 나는 고양이 로소이다. 라는 정보를 함축하고 있을 것이다.
이 정보가 Decoder 파트로 넘어가면 Decoder에서 각각의 출력마다 이 hs를 참조한다. 이때 그냥 참조하는 것이 아니라 각 LSTM의 출력때마다 이 정보를 참조하는 것이다. 이전에는 h1~ht에서 ht만을 참고했다면, Attention구조에서는 h1~ht 모두를 참조하는 것이다. 이를 그림으로 표현하면 다음과 같다.

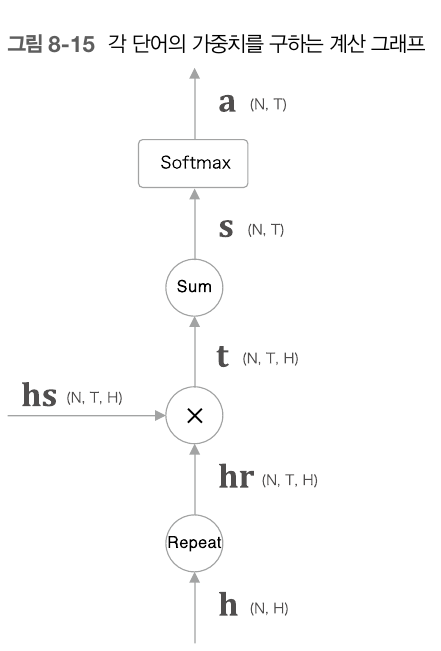
이 그림에서 어떤 계산에 주목해볼 필요가 있다. 어떤 계산이라함은 간단히 말해서 해당 출력결과가 hs의 어떤 행을 가장 중요하게 다뤄야 하는지가 계산되는 것이다. 이 어떤 계산이 바로 Attention 메커니즘이다.

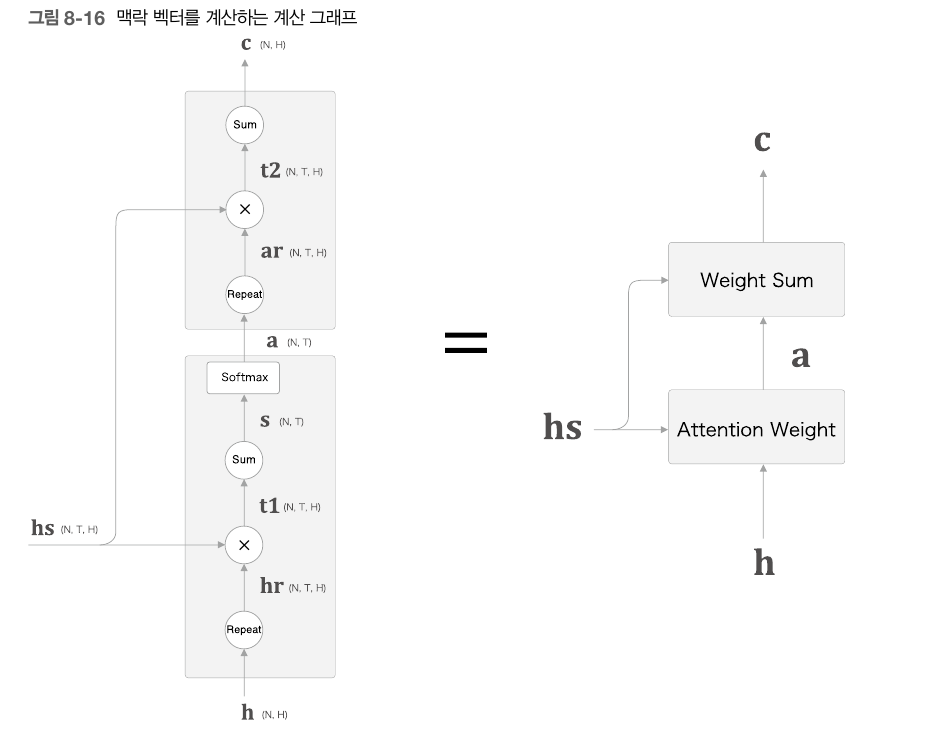
이는 hs에 가중치를 곱함으로써 구해준다. 그냥 곱하고 끝나는 것이아니라 여기에 가중합을 계산해 맥락벡터라는 것을 얻어낸다.
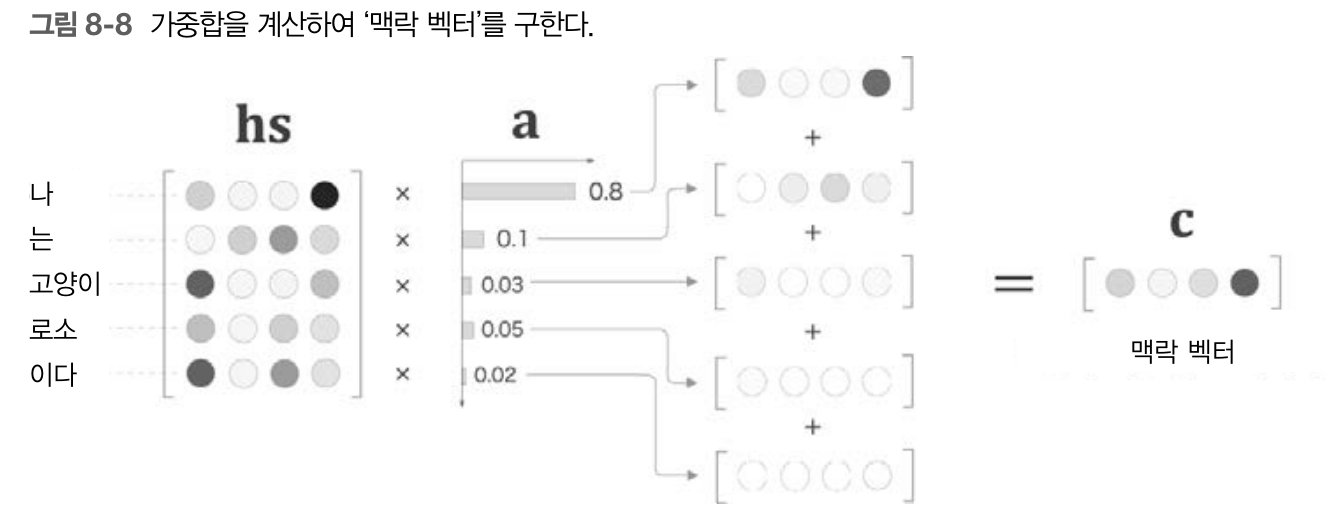
이렇게되면 위의 예시에서는 '나'라는 단어가 0.8의 가중치를 가졌으므로 '나'라는 단어를 0.8의 비율로 해석을 하게 될 것이다.
이때 이 a라는 것은 random으로 정해지는 것이 아니다. a는 해당 decoder에서의 출력벡터인 h를 바탕으로 만들어 진다. 이 출력 벡터 h가 hs와 얼마나 연관성이 있는지를 나타내는 지표가 가중치 a라는 것이다. (어떤 벡터가 중요하다 = 어떤 벡터가 h와 가장 연관성이 깊다)
이는 두 벡터의 내적을 통해 구할 수 있다. 어떤 벡터 a,b가 있을 때 a dot b 는 a 벡터와 b 벡터가 얼마나 같은 방향을 바라보고 있는지를 스칼라 값으로 나타내준다. 즉 , a b의 연관성을 수치로 나타낼 수 있음을 의미한다.
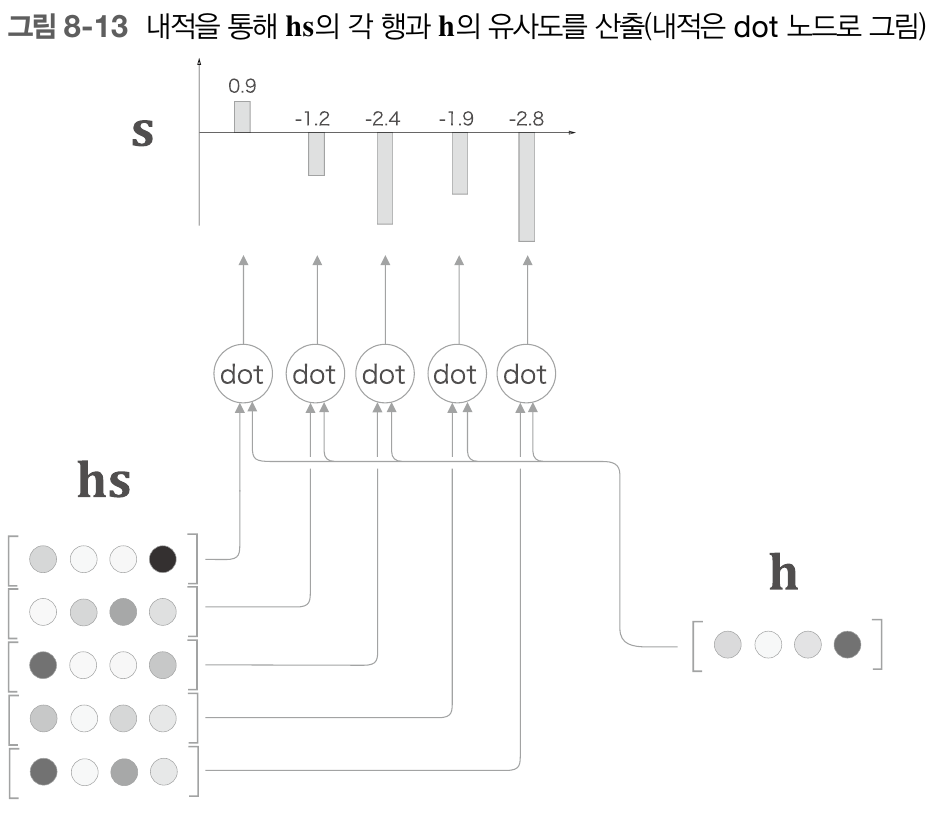
이렇게 hs의 각행에 해당하는 벡터와 h를 곱해줘 score값을 얻어낸다. 이 score 벡터에 softmax 함수를 적용한 것이 곧 아까전까지 말한 a가 되는 것이다. 이를 python으로 구현하면 다음과 같다.
class AttentionWeight:
def __init__(self):
self.params, self.grads = [], []
self.softmax = Softmax #Softmax 계층
self.cache = None
def forward(self,hs,h):
N,T,H = hs.shape #hs의 형상은 (T,H)이지만 미니배치를위해 (N,T,H)로
hr = h.reshape(N,H).reapeat(T,axis=1)
t = hs * hr #h,hs의 dot product
s = np.sum(t,axis=2)
a= self.softmax.forward(s)
self.cache(hs,hr) #역전파를 위한 cache
return a
def backward(self,da):
hs, hr = self.cache
N,T,H = hs.shape
ds = self.softamx.backward(da)
dt = ds.reshape(N,T,H).repeat(H,axis=2) #sum의 역전파 = repeat
dhs = dt * hr
dhr = dt * hs
dh = np.sum(dhr, axis=1) #repeat의 역전파 = sum
return dhs, dh해당 계층은 가중치 a만을 구하는 계층이다.
우리는 최종적으로 이 a에 hs를 곱한다음, Affine, Softmax 계층을 거쳐 출력결과를 얻어내야 하게 때문에 이 hs와 a를 곱하는 계층역시도 구현을 해줘야 한다.
class WeightSum:
def __init__(self):
self.params, self.grads = [], []
self.cache = None
def forward(self, hs, a):
N, T, H = hs.shape
ar = a.reshape(N, T, 1)#.repeat(T, axis=1)
t = hs * ar
c = np.sum(t, axis=1)
self.cache = (hs, ar)
return c
def backward(self, dc):
hs, ar = self.cache
N, T, H = hs.shape
dt = dc.reshape(N, 1, H).repeat(T, axis=1)
dar = dt * hs
dhs = dt * ar
da = np.sum(dar, axis=2)
return dhs, da
최종적으로 이 두가지 클래스를 합한것이 Attention 계층이다.
class Attention:
def __init__(self):
self.params, self.grads = [], []
self.attention_weight_layer = AttentionWeight()
self.weight_sum_layer = WeightSum()
self.attention_weight = None
def forward(self,hs,h):
a = self.attention_weight_layer.forward(hs,h)
out = self.weight_sum_layer.forward(hs,a)
self.attention_weight = a
return out
def backward(self,dout):
dhs0, da = self.weight_sum_layer.backward(dout)
dhs1, dh = self.attention_weight_layer.backward(da)
dhs = dhs0 + dhs1
return dhs, dh이때 이 Attention을 seq2seq 구조에 삽입해보도록 하자. seq2seq구조는 앞서 말한대로, LSTM을 T개만큼 연결된 TimeLSTM형태를 띄고 있다. 따라서 Attention 역시 T개의 Attention을 연결시킨 구조가 필요하다.
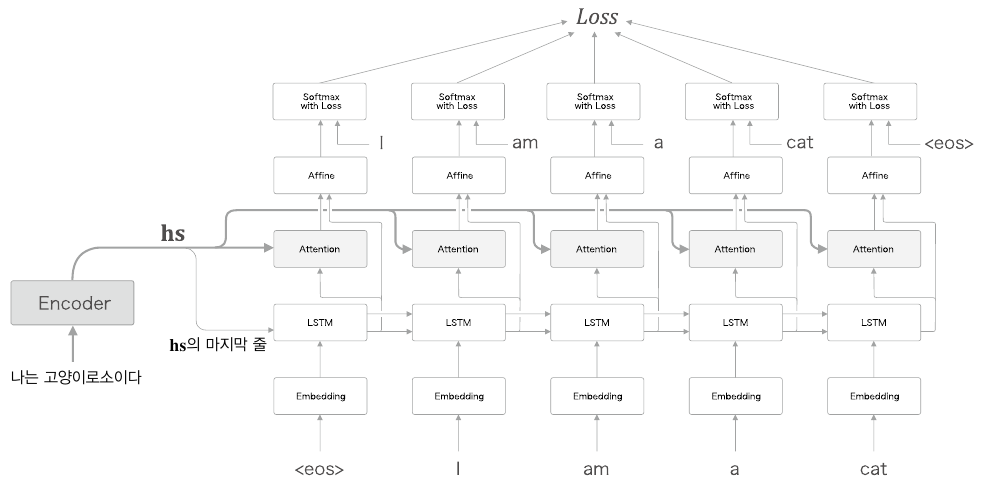
파이썬으로 구현하면 다음과 같다.
class TimeAttention:
def __init__(self):
self.params, self.grads = [], []
self.layers = None
self.attention_weights = None
def forward(self,hs_enc,hs_dec): #hs_enc : encoder에서 나온 h, hs_dec: decoder에서 나온 h
N,T,H = hs_dec.shape
out = np.empty_like(hs_dec)
self.layers = []
self.attention_weights = []
for t in range(T):
layer =Attention()
out[:,t,:] = layer.forward(hs_enc,hs_dec[:,t,:])
self.layers.append(layer)
self.attention_weights.append(layer.attention_weight)
return out
def backward(self,dout):
N,T,H = dout.shape
dhs_enc = 0
dhs_dec = np.empty_like(dout)
for t in range(T):
layer= self.layers[t]
dhs,dh = layer.bacward(dout[:,t,:])
dhs_enc += dhs
dhs_dec[:,t,:] = dh
return dhs_enc,dhs_dec