Attention
https://velog.io/@khko99/%EB%94%A5%EB%9F%AC%EB%8B%9D-9-Attention
앞절에서 설명했지만 간단하게 설명 해보면, Attention은 말그대로 특정정보에 주목하는 메커니즘이라고 생각하면 된다. 두개의 입력(전체 데이터, 정보)이 주어졌을 때, 이 정보가 전체 데이터 값들 중에서 어떤 값과 가장 연관성이 깊은지, 어떤 값에 주목해야하는지 체크한다음 이를 바탕으로 출력하는 메커니즘이라는 것이다.
이 Attention 구조를 가장 잘 활용한 구조가 Transformer 모델이다. 기존에 언어모델과 다르게 Transformer는 오직 Attention만을 사용한다.
Transformer
Transformer 모델의 전체구조를 보면 간단하다.
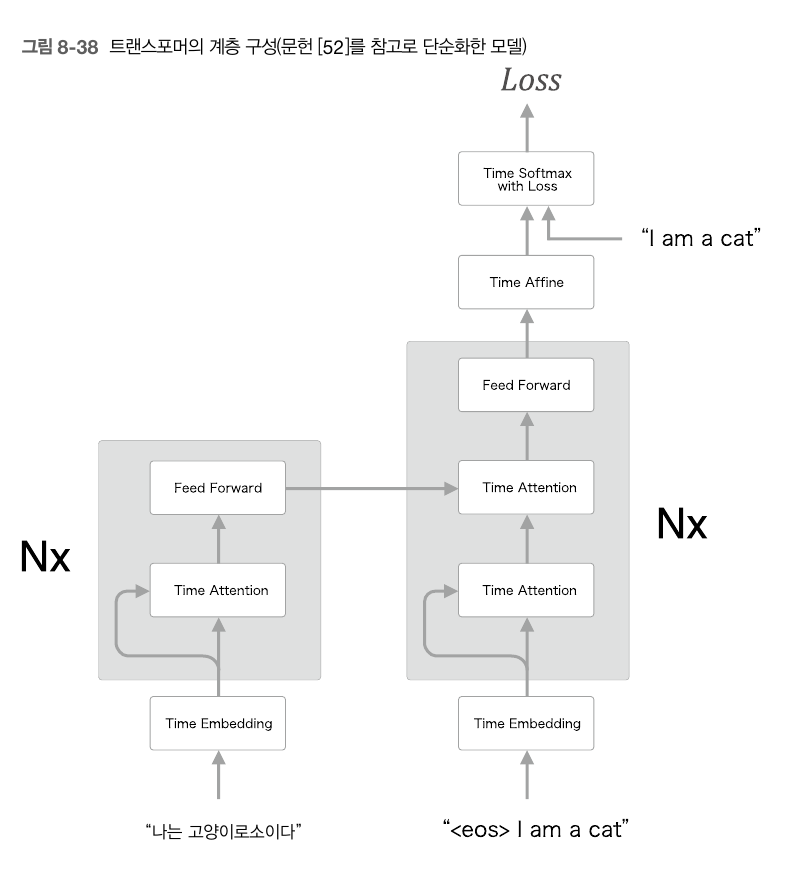
물론 이것보다 조금더 복잡한 구조(Positional encoding, Residual Learning... 등) 지만 핵심적인 구성은 다음과 같다. 우선 기존에 보지 못했던 self-attention 구조가 왼쪽 encoder와 decoder에 있는 것을 알 수 있다.
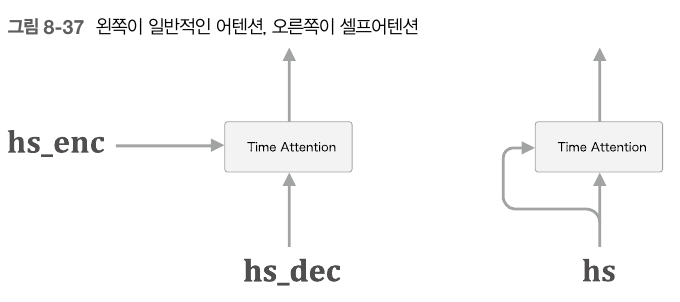
앞절의 Attention은 decoder로부터 나오는 시계열 데이터들의 각 원소들이, encoder로부터나오는 전체 시계열 데이터중 어떤 데이터와 연관성을 가지는지 출력하는 형태였다면, 이 self-attention 구조는 하나의 시계열 데이터만을 사용한다. 즉, 시계열 데이터의 각 원소들이 전체 시계열 데이터 들 중 어떤 시계열 데이터들과 연관성을 가지는지 출력해 주는 구조라고 보면 된다. 이렇게 해서 encoder와 decoder에서는 각각의 입력 문장의 각 단어들간의 대응 관계가 출력으로 나오게 되는 셈이다.
Feed Forward 계층은 앞절에서 봤던 완결연결 신경망의 한 종류이며, 구체적으로는 은닉층 1개와 ReLU 계층을 이용한 완결연결계층 신경망이다. 이렇게 나간 출력값들을 다시 오른쪽 decoder 파트의 Attention을 거쳐 출력한다.
트랜스포머를 사용하면, 계산량을 줄이고 GPU를 이용한 병렬 계산의 혜택을 더 많이 누릴수 있다. 기존의 RNN, LSTM을 활용한 언어모델에서는 시계열 데이터를 처리할 때, 이전의 출력값을 항상 참조해야하기 때문에, 병렬 계산이 불가능했지만, Attention 구조만을 이용한 Transformer에서는 병렬 계산의 활용도가 더욱 높아지기 때문에 높은 성능을 기대할 수 있다.
