arXiv:2506.10943v2 [cs.LG] 2025년 9월 18일
Self-Adapting Language Models (자기 적응형 언어 모델)
Adam Zweiger Jyothish Pari Han Guo Ekin Akyürek Yoon Kim Pulkit Agrawal
Massachusetts Institute of Technology
{adamz, jyop, hanguo, akyurek, yoonkim, pulkitag}@mit.edu
초록 (Abstract)
대형 언어 모델(LLM)은 강력하지만 정적입니다. 즉, 새로운 작업, 지식 또는 예시에 대응하여 가중치를 조정하는 메커니즘이 부족합니다. 우리는 LLM이 자체적으로 미세조정 데이터와 업데이트 지시문을 생성함으로써 스스로 적응할 수 있게 하는 프레임워크인 SEAL (Self-Adapting LLMS)을 소개합니다. 새로운 입력이 주어지면, 모델은 '자기 편집(self-edit)'을 생성합니다. 이 생성물은 정보를 다른 방식으로 재구성하거나, 최적화 하이퍼파라미터를 지정하거나, 데이터 증강 및 그래디언트 기반 업데이트를 위한 도구를 호출할 수 있습니다. 지도식 미세조정(SFT)을 통해 이러한 '자기 편집'은 영구적인 가중치 업데이트로 이어져 지속적인 적응을 가능하게 합니다. 모델이 효과적인 '자기 편집'을 생성하도록 훈련시키기 위해, 우리는 업데이트된 모델의 다운스트림 성능을 보상 신호로 사용하는 강화 학습 루프를 사용합니다. 별도의 적응 모듈이나 보조 네트워크에 의존하는 이전 접근 방식과 달리, SEAL은 모델 자신의 생성을 직접 사용하여 자체 적응 과정을 파라미터화하고 제어합니다. 지식 통합 및 퓨샷(few-shot) 일반화에 대한 실험은 SEAL이 새로운 데이터에 반응하여 자기 주도적으로 적응할 수 있는 언어 모델을 향한 유망한 단계임을 보여줍니다. 저희 웹사이트와 코드는 https://jyopari.github.io/posts/seal 에서 확인할 수 있습니다.
*동일 기여.
Improbable AI Lab, CSAIL MIT
제39회 신경정보처리시스템학회 (NeurIPS 2025).
1. 서론 (Introduction)
방대한 텍스트 코퍼스에 대해 사전 훈련된 대형 언어 모델(LLM)은 언어 이해 및 생성에서 놀라운 능력을 보여줍니다 [1, 2, 3, 4, 5]. 그러나 특정 작업 [6]에 맞게 이러한 강력한 모델을 조정하거나, 새로운 정보 [7]를 통합하거나, 새로운 추론 기술 [8]을 습득하는 것은 작업별 데이터의 가용성이 제한되어 있어 여전히 어려운 과제로 남아있습니다. 본 논문에서 우리는 흥미로운 가설을 탐구합니다: LLM이 스스로 훈련 데이터와 학습 절차를 변형하거나 생성함으로써 자기 적응(self-adapt)할 수 있을까?
비유를 들자면, 기계 학습 수업의 기말고사를 준비하는 학생을 생각해 보십시오. 많은 학생이 시험을 준비하기 위해 자신의 노트에 의존합니다. 이러한 노트는 종종 강의 내용, 교과서 또는 인터넷에서 얻을 수 있는 정보에서 파생됩니다. 원시 콘텐츠에 의존하는 대신, 정보를 노트 형태로 동화하고 재작성하는 것은 학생들이 내용을 이해하고 시험 문제에 답하는 능력을 향상시키는 경우가 많습니다. 외부 지식을 더 이해하기 쉬운 방식으로 재해석하고 증강하는 이러한 현상은 시험을 치르는 것에만 국한되지 않고, 여러 작업에 걸쳐 인간 학습에서 보편적으로 나타나는 현상인 것 같습니다. 더욱이, 사람마다 정보를 동화하는 방식이 다릅니다. 어떤 사람은 정보를 시각적 다이어그램으로 압축할 수도 있고, 어떤 사람은 텍스트로, 또 어떤 사람은 구체적인 수학적 설명에 더 의존할 수도 있습니다.
학습 과정의 일부로서 데이터를 이처럼 동화, 재구성 또는 재작성하는 것은 대형 언어 모델(LLM)이 일반적으로 훈련되고 배포되는 방식과는 대조적입니다. 새로운 작업이 주어지면, 현재의 LLM은 미세조정 또는 인-컨텍스트 학습(in-context learning)을 통해 작업 데이터를 "있는 그대로" 소비하고 학습합니다 [9, 10, 11, 12]. 그러나 이러한 데이터는 학습에 최적의 형식(또는 양)이 아닐 수 있으며, 현재의 접근 방식은 모델이 훈련 데이터로부터 최상의 변형 및 학습 방법을 위한 맞춤형 전략을 개발할 수 있도록 지원하지 않습니다.
더 나은 언어 모델 적응을 향한 단계로서, 우리는 LLM이 새로운 입력에 대응하여 자체 훈련 데이터와 미세조정 지시문을 생성하는 능력을 갖추도록 제안합니다. 특히, 우리는 (그림 1 참조) 모델의 가중치를 업데이트하기 위한 데이터 및 선택적으로 최적화 하이퍼파라미터를 지정하는 자연어 지시라인 '자기 편집(self-edits)'을 생성하도록 LLM을 훈련시키는 강화 학습 알고리즘을 소개합니다. 우리는 이러한 모델을 Self-Adapting LLMS (SEAL)이라고 부릅니다.
우리는 SEAL을 두 가지 응용 분야에서 평가합니다. 먼저 LLM에 새로운 사실적 지식을 통합하는 작업을 고려합니다. 구절 텍스트에 대해 직접 미세조정하는 대신, 우리는 SEAL 모델에 의해 생성된 합성 데이터에 대해 미세조정합니다. 우리의 결과는 강화 학습(RL) 훈련 후, 자체 생성된 합성 데이터에 대한 미세조정이 SQUAD [13]의 '문맥 내 구절 없음(no-passage-in-context)' 변형에서 질문-답변 성능을 33.5%에서 47.0%로 향상시킨다는 것을 보여줍니다. 주목할 점은, SEAL에서 자체 생성된 데이터가 GPT-4.1에 의해 생성된 합성 데이터보다 성능이 뛰어나다는 것입니다.
나아가, 우리는 ARC-AGI 벤치마크 [14]의 단순화된 하위 집합에서 퓨샷 학습에 대해 SEAL을 평가합니다. 여기서 모델은 합성 데이터 증강과 최적화 하이퍼파라미터(예: 학습률, 훈련 에포크, 토큰 유형에 따른 선택적 손실 계산)를 자율적으로 선택하기 위해 일련의 도구를 활용합니다. 우리의 실험은 SEAL을 사용하여 이러한 도구들을 자동으로 선택하고 구성하는 것이 표준 인-컨텍스트 학습(ICL) 및 도구를 효과적으로 사용하기 위한 RL 훈련 없는 '자기 편집'과 비교하여 성능을 향상시킨다는 것을 보여줍니다. 이러한 결과는 종합적으로 SEAL이 언어 모델이 스스로 적응할 수 있도록 하는 다재다능한 프레임워크임을 보여줍니다.

그림 1: SEAL의 개요. 각 RL 외부 루프 반복에서, 모델은 가중치 업데이트 방법에 대한 지시문인 후보 '자기 편집'(SE)을 생성하고, 업데이트를 적용하며, 다운스트림 작업에서의 성능을 평가하고, 결과로 얻은 보상을 사용하여 '자기 편집' 생성 정책을 개선합니다.
2. 관련 연구 (Related Work)
합성 데이터 생성 (Synthetic Data Generation)
LLM 훈련을 위한 합성 데이터 생성은 대규모 사전 훈련 데이터셋 [15, 16, 17, 18, 19]에서부터 작업별 데이터 증강 [20, 21, 22] 및 명령어 튜닝 세트 [23, 24]에 이르기까지 점점 더 보편화되고 있습니다. 더 작은 코퍼스의 통합을 위해, Yang 등 [25]은 그래프 기반 프롬프팅을 통한 합성 데이터 생성을 사용합니다. SEAL은 이러한 연구 흐름을 기반으로, 수동으로 조정되는 정적 또는 휴리스틱 생성 전략에 의존하는 대신, 그래디언트 기반 '자기 업데이트'에 적용될 때 합성 데이터의 다운스트림 유용성을 직접적으로 최대화하는 생성 정책을 훈련시키기 위해 강화 학습을 사용합니다.
지식 업데이트 (Knowledge Updating)
최근의 여러 연구는 가중치 업데이트를 통해 언어 모델에 사실적 지식을 수정하거나 주입하는 것을 목표로 합니다. 일부 방법은 개별 사실에 해당하는 특정 파라미터를 직접 찾아내려고 시도합니다 [26, 27, 28]. 다른 방법들은 문맥 속의 정보를 사용하여 추가적인 미세조정 데이터를 생성할 것을 제안합니다 [29, 30, 25, 31, 32]. 우리는 후자의 전략을 채택하며, Akyürek 등 [30]이 제안한 사실의 논리적 함의를 생성하고 이를 미세조정하는 방식과, Lampinen 등 [31]이 보여준 함의 기반 미세조정이 인-컨텍스트 학습을 능가할 수 있다는 연구를 따릅니다. 우리는 이러한 접근 방식들을 기반으로 RL을 통해 모델을 훈련시켜 더 최적의 미세조정 데이터를 생성합니다. Park 등 [32]은 언어 모델에게 질문-답변(QA) 쌍을 직접 생성하도록 프롬프팅하는 것이 함의 스타일 프롬프팅보다 성능이 뛰어날 수 있음을 보여주었습니다. SEAL 프레임워크는 '자기 편집' 데이터의 프롬프트나 형식에 구애받지 않기 때문에, §B.11에서 탐구한 바와 같이 QA 쌍이나 다른 출력 형식을 생성하도록 훈련될 수도 있습니다.
테스트 시점 훈련 (Test-Time Training)
테스트 시점 훈련(TTT)은 모델이 받는 입력에 기반하여 모델 가중치를 일시적으로 조정합니다 [33, 34, 35, 36]. Akyürek 등 [36]은 TTT와 ICL을 결합하면 퓨샷 설정에서 그래디언트 업데이트가 표준 ICL을 능가할 수 있음을 보여주었습니다. SEAL은 내부 루프 최적화에 TTT 라운드를 통합한 것으로 볼 수 있으며, TTT가 전체 규모 훈련 대비 갖는 효율성을 활용하여 여러 업데이트를 수행하고 가장 큰 성능 향상을 가져오는 생성된 데이터에 보상을 줍니다. 비록 우리 방법이 단일 예시 TTT 에피소드를 사용하여 훈련되지만, 우리는 지식 통합 설정에서 이것이 지속적 사전훈련(CPT) 체제—데이터를 문맥에 직접 배치하는 것이 더 이상 불가능한 경우—로 일반화됨을 보여줍니다.
LLM을 위한 강화 학습 (Reinforcement Learning for LLMs)
강화 학습은 원래 RLHF [37, 38]를 통해 LLM 행동을 개선하는 데 중심적인 역할을 해왔습니다. 더 최근에는, 검증 가능한 보상을 사용한 RL이 작업 성공을 위해 모델을 직접 최적화함으로써 추론 성능을 향상시키는 데 적용되었습니다 [39, 40, 41]. SEAL은 RL을 최종 답변이나 추론 과정을 최적화하는 데 적용하는 것이 아니라, 가중치 업데이트에 사용될 '자기 편집' 데이터의 생성을 최적화하는 데 적용합니다.
메타 학습 및 자기 수정 시스템 (Meta-Learning and Self-Modifying Systems)
SEAL은 외부 최적화 루프를 통해 효과적인 '자기 편집' 생성 방법이라는 적응 전략을 학습함으로써 메타 학습 원칙 [42, 43, 44]을 구현합니다. 목표는 작업 컨텍스트로부터 효율적으로 학습하는 방법을 배우는 것입니다. 강화 학습에서 메타 학습은 새로운 작업을 신속하게 학습하는 에이전트를 훈련시키는 데 사용되어 왔습니다 [45, 46, 47, 48]. Sun 등 [49]도 마찬가지로 RL을 적용하여 작업별 가중치 변조를 학습하며, 이는 우리 접근 방식과 직교하는 LoRA 미세조정의 대안을 제공합니다. 메타 학습의 자연스러운 확장은 모델이 자신의 파라미터를 수정하는 자기 참조 네트워크(self-referential networks)입니다 [50, 51]. 대형 언어 모델 분야에서 최근 연구는 LLM 적응을 개선하기 위해 메타 학습을 적용했습니다 [52, 53, 54, 55, 49]. 특히, Hu 등 [53]은 미세조정 중 토큰별 가중치를 출력하는 더 작은 모델을 훈련시켜 우리와 유사한 지식 통합 작업을 다루었으며, Chen 등 [54]은 입력을 조건으로 LoRA 어댑터를 생성하는 하이퍼네트워크를 제안하여 동적이고 작업별 파라미터화를 가능하게 했습니다. 그러나 SEAL은 모델의 기존 생성 능력을 활용하여 업데이트를 파라미터화함으로써 더 큰 일반성을 제공합니다.
자기 개선 (Self-Improvement)
최근의 여러 연구가 자기 개선(self-improvement) 또는 자기 훈련(self-training)의 범주에 속합니다. RLAIF [56, 57] 및 자기 보상 언어 모델 [58, 59]과 같은 방법들은 모델 자체가 보상 신호를 제공하도록 하며, 이는 출력을 생성하는 것보다 평가하는 것이 종종 더 쉽다는 관찰 [60]을 활용합니다. 다른 최근 연구들은 다수결 투표나 모델 신뢰도를 강화 학습 보상으로 사용하여, 정답 레이블 없이도 성능 향상을 가능하게 함으로써 수학적 작업의 성능을 향상시킵니다 [61, 62, 63, 64, 65]. 그러나 이러한 모든 방법은 근본적으로 모델의 현재 평가 능력과 자기 일관성(self-consistency)에 의해 제한됩니다. 반면, 우리는 외부 데이터와의 상호작용을 통한 자기 개선을 더 강력하고 확장 가능한 경로로 봅니다. SEAL은 자기 개선을 위해 이 외부 데이터를 가장 잘 활용하는 방법을 학습합니다.
3. 방법론 (Methods)
우리는 언어 모델이 새로운 데이터에 대응하여 자체적인 합성 데이터와 최적화 파라미터("자기 편집")를 생성함으로써 스스로를 개선할 수 있게 하는 프레임워크인 Self-Adapting LLMS (SEAL)을 제안합니다. 모델은 모델의 컨텍스트에 제공된 데이터를 사용하여 토큰 생성을 통해 직접 이러한 '자기 편집'을 생성하도록 훈련됩니다. '자기 편집' 생성은 강화 학습(RL)을 통해 학습되며, 모델은 적용되었을 때 목표 작업에서 모델의 성능을 향상시키는 '자기 편집'(SE)을 생성한 것에 대해 보상을 받습니다. 따라서 SEAL은 두 개의 중첩된 루프를 가진 알고리즘으로 해석될 수 있습니다: '자기 편집' 생성을 최적화하는 외부 RL 루프와, 생성된 '자기 편집'을 사용하여 그래디언트 하강(gradient descent)을 통해 모델을 업데이트하는 내부 업데이트 루프입니다. 우리 방법은 효과적인 '자기 편집'을 생성하는 방법을 메타 학습하는 메타 학습의 한 사례로 볼 수 있습니다.
3.1 일반 프레임워크 (General Framework)
를 언어 모델 의 파라미터를 나타낸다고 합시다. SEAL은 개별 작업 인스턴스 (C, )에 대해 작동합니다. 여기서 C는 작업과 관련된 정보를 포함하는 컨텍스트이고, 는 모델의 적응을 평가하는 데 사용되는 다운스트림 평가를 정의합니다. 예를 들어, 지식 통합에서 C는 모델의 내부 지식으로 통합되어야 할 구절이며, 는 해당 구절에 대한 질문과 관련 답변의 집합입니다. 퓨샷 학습에서 C는 새로운 작업에 대한 퓨샷 시연(demonstrations)을 포함하며, 는 쿼리 입력과 정답 출력입니다.
C가 주어지면, 모델은 '자기 편집' SE를 생성하며 (그 형태는 도메인에 따라 다름, §3.2 참조), 지도식 미세조정을 통해 파라미터를 업데이트합니다: . 우리는 강화 학습을 사용하여 '자기 편집' 생성 과정을 최적화합니다: 모델은 (SE 생성이라는) 행동을 취하고, 에 대한 의 성능에 기반한 보상 을 받으며, 기대 보상을 최대화하기 위해 정책을 업데이트합니다:
표준 RL 설정과 달리, 우리 설정에서는 주어진 행동에 할당되는 보상이 해당 행동이 취해진 시점의 모델 파라미터 에 의존합니다 (가 로 업데이트된 후 평가되기 때문입니다). 결과적으로, 기본 RL 상태는 정책의 파라미터를 포함해야 하며 (C, )로 주어집니다. 비록 정책의 관찰(observation)은 C로 제한되지만 말입니다 (를 문맥에 직접 배치하는 것은 불가능합니다). 이것이 의미하는 바는, 이전 버전의 모델 로 수집된 (상태, 행동, 보상) 트리플이 현재 모델 에 대해서는 유효하지 않게 되거나(stale) 잘못 정렬될 수 있다는 것입니다. 이러한 이유로, 우리는 온-폴리시(on-policy) 접근 방식을 채택하며, '자기 편집'은 현재 모델에서 샘플링되고, 결정적으로 보상도 현재 모델을 사용하여 계산됩니다.
Algorithm 1 Self-Adapting LLMS (SEAL): 자기 편집 강화 학습 루프

우리는 GRPO(Group Relative Policy Optimization) [66] 및 PPO(Proximal Policy Optimization) [67]와 같은 다양한 온-폴리시 방법을 실험했지만, 훈련이 불안정하다는 것을 발견했습니다. 대신, 우리는 "rejection sampling + SFT" [68, 69, 38, 39, 70]로도 알려진 필터링된 행동 복제(filtered behavior cloning)에 기반한 더 간단한 접근 방식인 ReSTEM [40]을 채택합니다. ReSTEM은 EM(기대-최대화) 절차로 볼 수 있습니다: E-단계는 현재 모델 정책에서 후보 출력을 샘플링하고, M-단계는 지도식 미세조정을 통해 긍정적인 보상을 받은 샘플들만 강화합니다. 이 접근 방식은 이진(binary) 보상 하에서 우리의 목적 함수 (1)의 근사치를 최적화합니다:
더 정확하게는, (1)을 최적화할 때 우리는 그래디언트 를 계산해야 합니다. 그러나 우리가 주목했듯이, 보상 항 은 우리 설정에서 에 의존하지만 미분 가능하지 않습니다. 우리는 보상을 에 대해 고정된 것으로 처리함으로써 이 문제를 해결합니다. 이 근사치를 사용하면, N개의 컨텍스트와 컨텍스트당 M개의 샘플링된 '자기 편집'으로 구성된 미니배치에 대한 몬테카를로 추정량은 다음과 같습니다:
여기서 는 모델의 자기회귀 분포를 나타내고 는 컨텍스트 에 대한 번째 샘플인 '자기 편집' 의 번째 토큰입니다. 인 시퀀스는 (4)에서 무시될 수 있으므로, 우리는 단순한 "좋은 '자기 편집'에 대한 SFT"를 사용하는 ReSTEM이 실제로 이진 보상 (2) 하에서 (보상 항에 stop-gradient를 적용하여) (1)을 최적화한다는 것을 보였습니다. SEAL 훈련 루프는 알고리즘 1에 요약되어 있습니다.
마지막으로, 본 연구의 구현은 '자기 편집' 생성과 이 '자기 편집'으로부터의 학습 모두에 단일 모델을 사용하지만, 이러한 역할을 분리하는 것도 가능합니다. 이러한 "교사-학생" 공식 [71]에서는, 별도의 교사 모델에 의해 제안된 편집을 사용하여 학생 모델이 업데이트됩니다. 그러면 교사는 학생의 개선을 최대화하는 편집을 생성하도록 RL을 통해 훈련될 것입니다. 보상은 또한 샘플링된 후보 중에서 가장 큰 향상을 가져오는 단일 '자기 편집'에 할당될 수 있으며, 우리는 지식 통합에서 이 방식을 사용합니다(긍정적인 향상을 가져오는 모든 편집 대신).
3.2 도메인별 구현 (Domain Instantiations)
우리는 SEAL 프레임워크를 두 가지 مdistinct한 도메인에서 구현합니다: 지식 통합과 퓨샷 학습. 이러한 도메인은 모델 적응의 두 가지 상호 보완적인 형태를 강조하기 위해 선택되었습니다: (1) 문맥에 의존하지 않고 회상할 수 있도록 새로운 정보를 모델의 가중치에 통합하는 능력 (SQUAD의 '문맥 없음' 변형을 사용하여 평가) 그리고 (2) 적은 수의 예시만 보고 새로운 작업을 일반화하는 능력 (ARC를 사용하여 평가).
지식 통합 (Knowledge Incorporation)
우리의 목표는 구절에 제공된 정보를 모델의 가중치에 효율적으로 통합하는 것입니다. 최근 유망한 접근 방식은 언어 모델을 사용하여 구절에서 파생된 콘텐츠를 생성한 다음, 원본 구절과 생성된 콘텐츠 모두에 대해 미세조정하는 것을 포함합니다 [29, 30, 25, 31, 32]. 생성된 콘텐츠의 형태는 다양할 수 있지만, 우리는 가장 표준적인 형식이라고 생각하는 것, 즉 구절에서 파생된 함의(implications)를 채택합니다. 연역적 폐쇄 훈련(deductive closure training) [30]에서 소개된 이 접근 방식은, 모델에게 "내용에서 파생된 여러 함의를 나열하세요"라고 프롬프팅함으로써 주어진 컨텍스트 C를 함의의 집합 로 변환합니다. 출력에는 추론, 논리적 귀결 또는 원본 구절의 재진술이 포함될 수 있습니다. §B.11에서는 "구절을 다른 방식으로 재작성하세요" 또는 "질문-답변 형식으로 재작성하세요"와 같은 대안적인 프롬프트를 탐색하고, 우리 방법이 기본 프롬프트에 관계없이 비슷하거나 더 큰 폭으로 성능을 향상시킨다는 것을 보여줍니다.

그림 2: 지식 통합 설정. 새로운 구절이 주어지면, 모델은 해당 구절의 "함의" 형태로 합성 데이터('자기 편집')를 생성합니다. 그런 다음 이 출력물에 대해 LORA를 사용하여 미세조정을 수행합니다. 업데이트된 모델은 원본 텍스트에 접근하지 않고 구절에 대한 질문으로 평가되며, 그 결과의 정확도가 강화 학습을 위한 보상 신호로 사용됩니다.
이러한 자체 생성된 문장들은 지도식 미세조정(SFT) 업데이트를 위한 훈련 데이터를 형성합니다: 우리는 각 시퀀스 에 대해 표준 인과적 언어 모델링 손실(causal language-modeling loss)을 계산하고 모델 파라미터를 업데이트하여 를 얻습니다. 업데이트당 데이터 양이 적고 우리가 수행하는 총 업데이트 횟수가 많기 때문에, 효율적이고 가벼운 튜닝을 위해 저계급 어댑터(LoRA [72])를 사용합니다. 마지막으로, 적응된 모델 은 작업 에 대해 평가됩니다. 이 과정은 그림 2에 나와 있습니다. RL 훈련 동안, 적응된 모델의 에 대한 정확도가 외부 RL 최적화를 구동하는 보상 을 정의합니다. 이는 모델이 미세조정을 통한 동화에 가장 효과적인 방식으로 구절을 재구성하도록 훈련시킵니다.
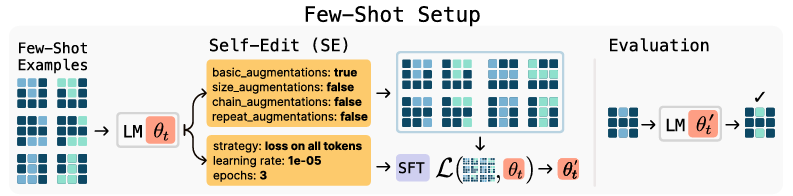
그림 3: SEAL을 이용한 퓨샷 학습. 왼쪽: ARC 시연 예시. 중앙: 모델이 증강 및 훈련 하이퍼파라미터를 지정하는 '자기 편집'을 생성합니다. 오른쪽: 적응된 모델이 홀드아웃(held-out) 테스트 입력에 대해 평가됩니다.
퓨샷 학습 (Few-Shot Learning)
추상화 및 추론 코퍼스(ARC) [8]는 매우 제한된 예시로부터의 추상적 추론과 일반화를 테스트하기 위해 고안된 벤치마크입니다. 각 작업에는 소수의 입력-출력 시연과, 정답 출력을 예측해야 하는 홀드아웃 테스트 입력이 포함됩니다. 우리는 Akyürek 등 [36]의 테스트 시점 훈련(TTT) 프로토콜을 채택하며, 여기서 퓨샷 예시의 증강(augmentations)이 그래디언트 기반 적응을 수행하는 데 사용됩니다. 증강 및 최적화 설정을 선택하기 위해 수동으로 조정된 휴리스틱에 의존하는 대신, 우리는 SEAL이 이러한 결정을 학습하도록 훈련시킵니다. 이 설정은 SEAL이 적응 파이프라인—어떤 증강을 적용하고 어떤 최적화 파라미터를 사용할지 결정하는 것—을 자율적으로 구성할 수 있는지를 테스트합니다.
이를 구현하기 위해, 우리는 각각 데이터를 변형하거나 훈련 파라미터를 지정하는 Akyürek 등 [36]의 사전 정의된 함수인 도구(tools) 집합을 정의합니다. 여기에는 다음이 포함됩니다:
- 데이터 증강: 회전, 뒤집기, 반사, 전치, 크기 조정 연산 (예: 그리드 해상도 변경), 그리고 연쇄적 또는 반복적 변환.
- 최적화 파라미터: 학습률, 훈련 에포크 수, 그리고 손실이 모든 토큰에 대해 계산되는지 또는 출력 토큰에 대해서만 계산되는지 여부.
모델은 작업의 퓨샷 시연과 함께 프롬프트되어 '자기 편집'을 생성합니다. 이 경우 '자기 편집'은 그림 3과 같이 어떤 도구를 호출하고 어떻게 구성할지에 대한 명세입니다. 그런 다음 '자기 편집'이 LoRA 미세조정을 통해 모델을 적응시키는 데 적용됩니다. 적응된 모델은 홀드아웃 테스트 입력에 대해 평가되며, 그 결과가 '자기 편집' 생성에 대한 보상을 결정합니다.
4. 결과 (Results)
이 섹션에서는 우리의 두 가지 적응 도메인인 퓨샷 학습과 지식 통합에 걸쳐 SEAL을 실증적으로 평가합니다. 전체 훈련, 하이퍼파라미터 및 평가 세부 정보는 §A와 §B에 제공됩니다.
4.1 퓨샷 학습 (Few-Shot Learning)
우리는 ARC 관련 사전 훈련이 없는 소형 오픈소스 모델인 Llama-3.2-1B-Instruct를 사용하여 실험을 수행합니다. 대부분의 ARC 작업은 ARC에 대해 사전 훈련되지 않은 모델에게는 어렵기 때문에, 우리는 ARC 훈련 세트에서 11개, 평가 세트에서 8개의 작업으로 구성된 하위 집합을 선별했습니다. 이들은 기본 Llama-3.2-1B-Instruct에 대한 최적의 TTT 구성 하에서 풀 수 있음을 보장하도록 필터링되었습니다. 이는 적은 수의 예시이지만, Akyürek 등 [36]이 모든 작업에 동일한 TTT 구성을 사용했기 때문에 고정된 '자기 편집'을 학습하는 데 큰 훈련 세트가 필요하지 않다는 점에 유의하십시오. 자세한 내용은 §A에 포함되어 있습니다.
모델은 훈련 작업당 15개의 '자기 편집'을 샘플링하여 ReSTEM을 사용해 훈련됩니다. 각 '자기 편집'은 15개의 업데이트된 모델을 생성하기 위해 개별적으로 적용되며, 그런 다음 해당 홀드아웃 테스트 예제에 대해 평가됩니다. 우리는 적응 후 테스트 입력에 대해 정답을 생성하는 모델, 즉 올바르게 적응된 모델로 이어지는 '자기 편집'만 강화합니다.
훈련 후, 우리는 홀드아웃 평가 작업당 5개의 '자기 편집'을 생성하고 각각을 독립적으로 적용하여 모델을 평가합니다. 그런 다음 정답으로 이어지는 '자기 편집'의 비율을 보고하며, 이는 학습된 '자기 편집' 생성 정책의 품질을 반영하는 성공률을 산출합니다.
우리는 다음 베이스라인과 비교합니다:
- ICL (In-Context Learning): Llama-3.2-1B-Instruct에 Akyürek 등의 [36] 프로토콜을 사용하여 주어진 퓨샷 예시를 프롬프트로 제공하고, 테스트 입력에 대해 직접 질의합니다.
- TTT + Self-Edit (w/o prior RL): Llama-3.2-1B-Instruct가 퓨샷 예시와 합성 증강을 사용하여 테스트 시점 훈련(TTT)을 수행하지만, 어떤 증강이나 훈련 구성을 사용할지 최적화하기 위한 사전 RL 훈련은 없습니다.
- Oracle TTT: 모델이 Akyürek 등의 [36]에서 사용한 최적의 인간 제작 구성을 사용하여 테스트 시점 훈련(TTT)을 수행합니다. 이는 우리 방법의 상한선을 제공합니다.
결과는 표 4.1에 기록되어 있습니다. SEAL은 베이스라인에 비해 적응 성공률을 상당히 향상시켰습니다: 72.5% vs. 20% (RL 훈련 없는 기본 모델의 '자기 편집') 및 0% (적응 없음). 하지만 성능은 Oracle TTT보다는 낮아 추가 개선의 여지가 있음을 시사합니다.
표 1: 퓨샷 추상적 추론
| Method | Success Rate (%) |
|---|---|
| ICL | 0 |
| TTT + Self-Edit (w/o prior RL) | 20 |
| SEAL | 72.5 |
| Oracle TTT | 100 |
4.2 지식 통합 (Knowledge Incorporation)
우리는 Qwen2.5-7B를 사용하여 SQUAD 구절 [13]의 새로운 사실적 콘텐츠를 통합하는 실험을 합니다. 우리는 상대적으로 간단한 SQUAD 데이터셋을 사용하는데, 이는 그 구절들이 기본 모델에 의해 문맥 내에서는 완전히 "이해"될 수 있지만, 문맥 없이는 모델이 질문에 안정적으로 답할 수 없기 때문입니다. 우리는 50개 컨텍스트 배치로 ReSTEM을 2라운드 수행합니다 (자세한 내용은 §B 참조). 우리는 지식 통합에 대해 SEAL을 다음 베이스라인 접근 방식과 비교합니다:
- Base Model: 사전 훈련된 모델을 어떠한 적응이나 구절 접근 없이 다운스트림 QA 작업에 대해 평가합니다.
- Train on Passage Only: 합성 데이터 없이, 표준 언어 모델링 손실을 사용하여 구절에 대해서만 모델을 직접 미세조정합니다.
- Train on Passage + Synthetic Data: 모델을 구절 및 자체 생성된 함의와 함께 훈련합니다. 이는 사전 RL 훈련이 없다는 점만 제외하면 SEAL과 동일한 설정입니다.
- Train on Passage + GPT-4.1 Synthetic Data: OpenAI API를 통해 GPT-4.1에서 수집한 모델 생성 함의와 함께 구절에 대해 모델을 훈련합니다.
표 4.2는 두 가지 체제 하에서의 평균 '문맥 없음' SQUAD 정확도를 보고합니다: 단일 구절 업데이트(LoRA 사용) 및 소규모 지속적 사전훈련(전체 미세조정 사용). 우리는 문서, 그리고 전체 SQUAD 검증 세트인 문서로 지속적 사전훈련(CPT) 실험을 실행합니다. 단일 구절 설정에서, 구절에 직접 미세조정하는 것은 동결된 기본 모델에 비해 미미한 이득(33.5% vs. 32.7%)을 산출하며, 이는 원시 데이터만으로는 불충분함을 확인시켜 줍니다. GPT-4.1에 의해 생성된 합성 함의로 보강하면 정확도가 46.3%로 향상되어, 구절 전용 베이스라인보다 12.8% 포인트 향상됩니다. 기본 Qwen-2.5-7B 모델에 의해 생성된 합성 데이터를 사용하면 39.7%로, 6.2% 포인트 증가합니다. 강화 학습 후, SEAL은 정확도를 47.0%로 더욱 향상시켰으며, 특히 훨씬 작은 모델임에도 불구하고 GPT-4.1의 합성 데이터를 사용하는 것보다 성능이 뛰어났습니다.
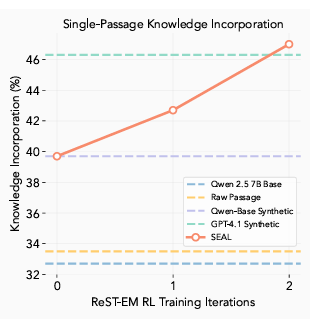
그림 4: RL 반복에 따른 정확도. 각 반복은 50개의 컨텍스트 미니배치로 구성되며, 각 컨텍스트마다 5개의 샘플링된 '자기 편집'이 있습니다. SEAL은 '문맥 없음' SQUAD 세트에서 ReSTEM 2회 반복 후 GPT-4.1 합성 데이터를 능가합니다.
CPT 설정에서는, 모델이 단일 지속적 사전훈련 실행에서 많은 구절로부터 정보를 동화합니다. 그런 다음 모든 해당 질문의 합집합에 대해 평가됩니다. 이 설정에서, 우리는 각 구절에 대해 5개의 '자기 편집' 생성을 샘플링하고, 지속적 사전훈련을 위해 집계된 합성 데이터셋을 취합니다. 표 4.2에서 볼 수 있듯이, 단일 구절 사례와 유사한 방법 순위를 관찰하지만, GPT-4.1의 합성 데이터가 SEAL을 약간 능가합니다. 설정에서, SEAL은 58.2%의 정확도를 달성하여 단일 구절 성능을 초과합니다. 우리는 이 이득이 여러 '자기 편집' 생성의 집계 덕분이라고 봅니다. 전반적으로, SEAL의 강력한 지속적 사전훈련 결과는 '자기 편집' 정책이 단일 구절을 위해 단일 생성으로 합성 데이터를 생성하는 원래의 RL 설정을 넘어 일반화됨을 시사합니다.
그림 4는 각 외부 RL 반복 후의 정확도를 추적합니다. SEAL이 GPT-4.1 데이터를 능가하는 데는 두 번의 반복으로 충분했으며, 후속 반복은 수익 체감(diminishing returns)을 나타냈습니다. 이는 정책이 구절을 쉽게 학습 가능한 원자적 사실(atomic facts)로 추출하는 편집 스타일로 빠르게 수렴함을 시사합니다 (그림 5의 정성적 예시 참조). 모든 결과는 조정된 하이퍼파라미터를 사용합니다 ( §B 참조).
표 2: 여러 구절 설정에 걸친 지식 통합 성능
| Method | Single Passage (; LORA) | Continued Pretraining (; full-FT) | Continued Pretraining (; full-FT) |
|---|---|---|---|
| Base model | 32.7 | 32.7 | 29.0 |
| Train on Passage | 33.5 | 36.0 | 31.2 |
| Train on Passage + Synthetic | 39.7 | 50.6 | 43.4 |
| Train on Passage + GPT-4.1 Synthetic | 46.3. | 59.4 | 49.2 |
| SEAL | 47.0 | 58.2 | 46.4 |

그림 5: RL 반복에 따른 지식 통합 '자기 편집' 예시. 이 예시에서, RL이 어떻게 더 상세한 '자기 편집'의 생성으로 이어지는지, 그리고 이것이 결과적으로 더 나은 성능을 가져오는지 볼 수 있습니다. 이 경우 진행 과정이 명확하지만, 다른 예시에서는 반복 간의 차이가 더 미묘할 때도 있습니다. §B.11에서는 더 긴 '자기 편집'을 요청하는 프롬프트가 효과적이며, RL 훈련이 비슷한 마진으로 성능을 더욱 향상시킨다는 것을 보여줍니다.
5. 한계점 (Limitations)
파국적 망각 (Catastrophic forgetting)
우리가 언어 모델에 '자기 편집' 기능을 부여하고자 했던 한 가지 핵심 동기는 지속적인 학습(continual learning)이라는 궁극적인 목표, 즉 모델이 환경과의 주체적 상호작용을 통해서든 표준 훈련을 통해서든 시간이 지남에 따라 새로운 정보를 통합할 수 있게 하는 것이었습니다. 우리의 이전 실험들은 SEAL이 개별 편집에 고립되어 얼마나 잘 적응하는지를 평가하지만, 더 야심 찬 목표는 편집의 시퀀스를 지원하는 것입니다: 모델이 이전 지식을 보존하면서 새로운 정보에 반복적으로 적응할 수 있는가? 이 질문은 새로운 업데이트가 과거의 학습을 파괴적으로 방해하는 파국적 망각 [73, 74]의 문제와 직접적으로 관련됩니다. 우리는 현재 훈련 설정에서 보존(retention)을 명시적으로 최적화하지는 않지만, 파국적 망각을 처리하기 위한 전용 메커니즘 없이 SEAL이 순차적인 '자기 편집'을 얼마나 잘 처리하는지에 대한 베이스라인을 확립하고자 합니다.
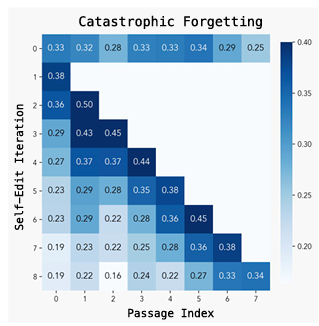
그림 6: 지속적인 '자기 편집'으로 인한 파국적 망각. 모델을 순차적으로 새로운 구절에 대해 업데이트하고 이전 작업에서의 성능 저하를 추적합니다. 항목별 표준 오차는 §B.6에 보고되어 있습니다.
이를 테스트하기 위해, 우리는 지식 통합 도메인에서 지속적인 학습 설정을 시뮬레이션합니다. 모델은 테스트 구절의 스트림을 받으며, 각 구절은 새로운 '자기 편집'을 유발합니다. 각 업데이트 후, 우리는 보존을 측정하기 위해 이전에 본 모든 작업에 대해 모델을 재평가합니다. 이 설정은 모델이 이전 편집을 잊지 않고 새로운 편집을 통합하는 능력을 테스트합니다.
그림 6에서 볼 수 있듯이, '편집' 횟수가 증가함에 따라 이전 작업에 대한 성능이 점진적으로 감소하며, 이는 SEAL이 여전히 파국적 망각에 취약함을 시사합니다. 그럼에도 불구하고, 완전한 붕괴 없이 여러 업데이트를 수행할 수 있으며, 이는 개선의 가능성을 나타냅니다. 향후 연구는 이전 작업에서의 회귀에 페널티를 부과하는 보상 쉐이핑(reward shaping) [75, 76, 77]을 통하거나, 널스페이스(null-space) 제약 편집 [78] 또는 표현 중첩(representational superposition) [79]과 같은 지속적인 학습 전략을 통합함으로써 이 능력을 향상시킬 수 있습니다. 또한, RL이 SFT보다 덜 잊는다는 것이 보여졌기 때문에, SEAL의 내부 루프도 SFT 대신 RL을 사용할 수 있습니다 [80].
계산 오버헤드 (Computational overhead)
TTT 보상 루프는 LLM과 함께 사용되는 다른 강화 학습 루프보다 계산 비용이 훨씬 많이 듭니다. 예를 들어, 인간 선호도에 기반한 보상 신호는 일반적으로 단일 모델 순전파(forward pass)를 포함하며, 검증된 솔루션을 사용하는 신호는 간단한 패턴 매칭(예: 정규식)에 의존할 수 있습니다. 대조적으로, 우리 접근 방식은 보상을 계산하기 위해 전체 모델을 미세조정하고 평가해야 합니다. 각 '자기 편집' 평가는 약 30-45초가 소요되며, 상당한 오버헤드를 발생시킵니다 ( §B.5 참조).
문맥 의존적 평가 (Context-dependent evaluation)
우리의 현재 구현은 모든 컨텍스트가 명시적인 다운스트림 작업과 쌍을 이룬다고 가정합니다: 퓨샷 시연은 홀드아웃 쿼리 쌍과 함께 제공되고, 각 구절은 참조 QA와 함께 제공됩니다. 이러한 결합은 보상 계산을 단순화하지만, 레이블이 없는 코퍼스로 SEAL의 RL 훈련을 확장하는 것을 방해합니다. 잠재적인 해결책은 모델이 '자기 편집'뿐만 아니라 자체 평가 질문(예: 원본 콘텐츠가 아직 문맥에 있는 동안 각 구절에 대한 QA 항목 초안 또는 합성 테스트 케이스 작성)도 생성하게 하는 것입니다. 이렇게 모델이 작성한 쿼리는 강화 학습에 필요한 즉각적인 감독을 제공하여, 외부 질문-답변 세트를 사용할 수 없는 일반 훈련 도메인으로의 적용 가능성을 넓힐 수 있습니다.
6. 토론 및 결론 (Discussion and Conclusion)
Villalobos 등 [81]은 선도적인 LLM이 2028년까지 공개적으로 이용 가능한 모든 인간 생성 텍스트에 대해 훈련될 것이라고 예측합니다. 우리는 이러한 임박한 "데이터 장벽"이 합성 데이터 증강의 채택을 필요하게 만들 것이라고 주장합니다. 웹 스케일의 코퍼스가 고갈되면, 발전은 모델 자체의 고효용 훈련 신호 생성 능력에 달려있을 것입니다. 자연스러운 다음 단계는 새로운 사전 훈련 코퍼스를 생성하는 전용 SEAL 합성 데이터 생성기 모델을 메타 훈련시켜, 미래의 모델이 추가적인 인간 텍스트에 의존하지 않고도 확장되고 더 큰 데이터 효율성을 달성할 수 있도록 하는 것입니다.
우리는 LLM이 학술 논문과 같은 새로운 데이터를 수집하고, 기존 지식과 문맥 내 데이터 추론을 사용하여 스스로 대량의 설명과 함의를 생성할 수 있는 미래를 상상할 수 있습니다. 이러한 자기 표현과 자기 개선의 반복적인 루프는 모델이 추가적인 외부 감독이 없는 상황에서도 희귀하거나 잘 다뤄지지 않는 주제에 대해 계속해서 개선될 수 있도록 할 수 있습니다.
또한, 현대의 추론 모델은 종종 연쇄적 사고(CoT) 추론을 생성하도록 RL로 훈련되지만, SEAL은 모델이 언제, 어떻게 자신의 가중치를 업데이트할지 학습할 수 있게 하는 보완적인 메커니즘을 제공할 수 있습니다. 이 두 접근 방식은 시너지를 낼 수 있습니다: 모델은 현재 궤적을 안내하기 위해 추론 중간에 가중치 업데이트를 수행하도록 선택할 수도 있고, 또는 핵심 통찰을 파라미터로 추출하기 위해 추론을 완료한 후에 업데이트를 수행하여 내재화된 학습을 통해 미래의 추론을 개선할 수도 있습니다.
이러한 지속적인 개선 루프는 또한 에이전트 시스템(agentic systems), 즉 확장된 상호작용을 통해 작동하고 진화하는 목표에 동적으로 적응하는 모델을 구축하는 데에도 유망합니다. 에이전트 모델은 행동함에 따라 점진적으로 지식을 습득하고 유지해야 합니다. 우리의 접근 방식은 구조화된 자기 수정을 가능하게 함으로써 이러한 행동을 지원합니다: 상호작용 후, 에이전트는 가중치 업데이트를 유발하는 '자기 편집'을 합성할 수 있습니다. 이는 에이전트가 시간이 지남에 따라 발전하고, 이전 경험과 행동을 일치시키며, 반복적인 감독에 대한 의존도를 줄일 수 있게 할 것입니다.
SEAL은 대형 언어 모델이 사전 훈련 후에 정적으로 머무를 필요가 없음을 보여줍니다: 자체적인 합성 '자기 편집' 데이터를 생성하고 이를 경량의 가중치 업데이트를 통해 적용하는 법을 학습함으로써, 새로운 지식을 자율적으로 통합하고 새로운 작업에 적응할 수 있습니다. 앞으로, 우리는 SEAL 프레임워크를 사전 훈련, 지속적인 학습, 그리고 에이전트 모델로 확장하여, 궁극적으로 언어 모델이 데이터가 제한된 세계에서 스스로 학습하고 확장할 수 있도록 하는 것을 구상합니다.
