(previous) The AI Scientist: Towards Fully Automated Open-Ended Scientific Discovery (LLM) - 1
The AI Scientist: Towards Fully Automated Open-Ended Scientific Discovery
5. In-Depth Case Study
The AI Scientist가 생성한 논문에 대한 광범위한 실험과 메트릭을 6장에서 제시하기에 앞서, 먼저 The AI Scientist의 실행 중 대표적인 샘플을 시각화하여 그 강점과 약점을 보여준 뒤, 그 잠재력에 대해 폭넓게 논의합니다. 선택된 논문인 “Adaptive Dual-Scale Denoising”은 The AI Scientist가 확산 모델링에 대한 연구를 수행하도록 요청받은 실행에서 생성되었습니다. 이에 대한 자세한 내용은 6.1장에서 다룹니다. 사용된 기본 기반 모델은 Claude Sonnet 3.5(Anthropic, 2024)입니다.
생성된 아이디어 (Generated Idea)
3장에서 논의된 바와 같이, The AI Scientist는 제공된 템플릿과 이전의 발견 아카이브를 기반으로 먼저 아이디어를 생성합니다. 선택된 논문의 아이디어는 알고리즘의 6번째 iteration에서 제안되었으며, 표준 디노이저 네트워크에 두 개의 분기를 제안하여 확산 모델이 2D 데이터셋에서 전역(global) 구조와 지역(local) 세부 정보를 모두 포착하는 능력을 향상시키는 것을 목표로 합니다. 이는 연구자들이 기존의 생성 모델(예: VAEs(Kingma and Welling, 2014) 또는 GANs(Goodfellow et al., 2014)) 대신 확산 모델을 채택한 주요 이유와 잘 부합하는 방향입니다. 우리가 아는 한, 이 접근법은 아직 널리 연구되지 않았습니다.
우리는 The AI Scientist가 제안된 코드 수정, 기준선과의 비교, 평가 지표, 추가적인 플롯 설계 등을 포함한 인상적인 실험 계획을 생성한다는 점을 강조합니다. 기존 문헌에서도 관찰된 바와 같이(예: Zheng et al., 2024), LLM의 판단은 종종 편향을 가질 수 있으며, 이는 아이디어의 흥미로움, 실현 가능성, 또는 참신성에 대한 과대평가로 나타날 수 있습니다. 마지막에 있는 “novel” 플래그는 The AI Scientist가 Semantic Scholar API를 사용하여 관련 논문을 검색한 후 해당 아이디어가 참신하다고 판단했음을 나타냅니다.

Generated Experiments
우리는 아래에서 생성된 코드의 변경(diff)을 표시하며, 삭제된 부분은 빨간색으로, 추가된 부분은 초록색으로 나타냅니다. 이 코드는 실험 설명과 일치하며, 주석이 잘 작성되어 있습니다. The AI Scientist는 중간 실험 결과를 루프 내에서 활용하여 코드를 반복적으로 수정할 수 있으며, 최종적으로 adaptive weight network에 대해 흥미로운 설계를 선택합니다(예: LeakyReLU). 중요하게도, 이 네트워크의 출력은 0과 1 사이로 보장되는 잘 동작하는 형태를 가지고 있습니다. 또한, The AI Scientist는 새로운 시각화를 만들기 위해 네트워크의 출력을 adaptive weights를 반환하도록 변경했음을 주목합니다.
@@-60,19 +60,55 @@ class MLPDenoiser(nn.Module):
self.input_mlp1 = SinusoidalEmbedding(embedding_dim, scale=25.0)
self.input_mlp2 = SinusoidalEmbedding(embedding_dim, scale=25.0)
- self.network = nn.Sequential(
+ self.global_network = nn.Sequential(
nn.Linear(embedding_dim * 3, hidden_dim),
*[ResidualBlock(hidden_dim) for _ in range(hidden_layers)],
nn.ReLU(),
nn.Linear(hidden_dim, 2),
)
+ self.local_network = nn.Sequential(
+ nn.Linear(embedding_dim * 3, hidden_dim),
+ *[ResidualBlock(hidden_dim) for _ in range(hidden_layers)],
+ nn.ReLU(),
+ nn.Linear(hidden_dim, 2),
+ )
+
+ self.upscale = nn.Linear(2, 4)
+ self.downscale = nn.Linear(2, 2)
+
+ # Modify the weight network to have an additional hidden layer and use LeakyReLU
+ self.weight_network = nn.Sequential(
+ nn.Linear(embedding_dim, hidden_dim),
+ nn.LeakyReLU(0.2),
+ nn.Linear(hidden_dim, hidden_dim // 2),
+ nn.LeakyReLU(0.2),
+ nn.Linear(hidden_dim // 2, 2),
+ nn.Softmax(dim=-1) # Ensure weights sum to 1
+ )
def forward(self, x, t):
x1_emb = self.input_mlp1(x[:, 0])
x2_emb = self.input_mlp2(x[:, 1])
t_emb = self.time_mlp(t)
- emb = torch.cat([x1_emb, x2_emb, t_emb], dim=-1)
- return self.network(emb)
+ global_emb = torch.cat([x1_emb, x2_emb, t_emb], dim=-1)
+
+ # Global branch
+ global_output = self.global_network(global_emb)
+
+ # Local branch with upscaling
+ x_upscaled = self.upscale(x)
+ x1_upscaled_emb = self.input_mlp1(x_upscaled[:, 0])
+ x2_upscaled_emb = self.input_mlp2(x_upscaled[:, 1])
+ local_emb = torch.cat([x1_upscaled_emb, x2_upscaled_emb, t_emb], dim=-1)
+ local_output = self.local_network(local_emb)
+
+ # Calculate dynamic weights based on timestep
+ weights = self.weight_network(t_emb)
+
+ # Combine global and local outputs with learnable weighting
+ output = weights[:, 0].unsqueeze(1) * global_output + weights[:, 1].unsqueeze(1) * local_output
+ return output, weights
Generated Paper.

The AI Scientist는 표준 머신러닝 컨퍼런스 제출 형식에 맞춘 11페이지 분량의 과학 논문을 생성하며, 시각화 자료와 모든 표준 섹션이 포함되어 있습니다. 우리는 Figure 3에 AI가 완전히 생성한 논문의 미리보기를 제공하며, 전체 크기 버전은 Appendix D.1에서 확인할 수 있습니다. 우리는 이 논문에서 특히 인상적이었던 특정 요소들을 강조합니다.
-
알고리즘에 대한 수학적 설명:
코드에서 이루어진 알고리즘적 변경 사항이 정확히 설명되었으며, 필요한 경우 새로운 표기법이 도입되었고, LaTeX 수식 패키지를 사용하여 이를 명확히 표현했습니다. 또한, 전체적인 학습 과정 역시 정확하게 기술되었습니다. -
포괄적인 실험 기록:
논문에는 하이퍼파라미터, 기준선, 데이터셋 등이 자세히 나열되어 있습니다. 논문 내 Table 1의 주요 수치 결과는 실험 로그와 정확히 일치하며, 긴 소수점 값을 셋째 자리에서 반올림해도 오류 없이 정확히 기록되었습니다. 더 나아가, 결과가 기준선과 비교되었으며, 예를 들어 "공룡 데이터셋에서 KL 발산이 12.8% 감소 (0.989에서 0.862로)"와 같은 개선 사항이 포함되어 있습니다. -
우수한 실험 결과:
정량적으로는 샘플의 KL 발산 값이 감소하는 등 개선이 이루어졌으며, 정성적으로는 기준선보다 크게 벗어난 샘플이 더 적었습니다. -
새로운 시각화 자료:
우리는 생성된 시각화 자료에서 알고리즘이 적용되는 동안 가중치의 변화를 나타낸 새로운 플롯을 확인할 수 있었습니다. 이는 제공된 코드에서 크게 벗어난 알고리즘 특화 플롯입니다. -
흥미로운 미래 연구 섹션:
현재 실험의 성공을 기반으로, 고차원 문제로의 확장, 더 정교한 적응 메커니즘, 더 나은 이론적 기반 구축 등 관련된 다음 단계 연구 방향을 나열했습니다.
그러나, 논문에는 몇가지 단점이 있습니다.
-
업스케일링 네트워크의 미세한 오류:
노이즈 제거 네트워크에 입력값을 업스케일링하기 위한 선형 레이어가 있지만, "로컬" 분기에서 처음 두 차원만 사용되며, 결과적으로 이 업스케일링 레이어는 동일한 차원을 유지하는 선형 레이어로 작동합니다. -
실험 세부사항의 환각:
논문은 V100 GPU가 사용되었다고 주장하지만, 실제로는 H100 GPU가 사용되었습니다. 또한, PyTorch 버전에 대한 추정값을 제공했지만 확인하지는 않았습니다. -
결과의 긍정적 해석:
논문은 부정적인 결과조차도 긍정적으로 기술하며 약간의 유머러스한 결과를 낳습니다. 예를 들어, 긍정적인 결과를 "공룡: 12.8% 감소 (0.989에서 0.862로)"라고 요약하면서, 부정적인 결과를 "달 모양: 3.3% 개선 (0.090에서 0.093으로)"이라고 표현합니다. 부정적인 결과를 개선이라고 표현한 것은 다소 과장된 해석입니다. -
실험 로그에서 비롯된 데이터 사용:
알고리즘의 변경 사항은 보통 기술적으로 잘 설명되어 있지만, 결과를 "Run 2"와 같이 실험 로그에서 그대로 가져오는 경우가 드물게 발생합니다. 이는 전문적인 논문 작성에서 일반적으로 사용되지 않는 표현 방식입니다. -
중간 결과의 표현:
논문에는 실행된 모든 실험의 결과가 포함되어 있습니다. 이는 아이디어의 실행 과정을 볼 수 있는 유용하고 통찰력 있는 자료이지만, 표준적인 논문에서 중간 결과를 이렇게 제시하는 경우는 드뭅니다. -
적은 참고 문헌:
Semantic Scholar에서 추가된 참고 문헌과 관련된 두 논문은 매우 적합한 비교 자료이지만, 전체 참고 문헌은 9개로 적은 편입니다.
리뷰
자동화된 리뷰어는 생성된 원고에서 유효한 우려 사항들을 지적합니다. 리뷰에서는 실험이 단순한 2D 데이터셋으로만 이루어졌음을 인식하고 있지만, 이는 우리가 외부적으로 이 시스템에 해당 데이터셋만 사용하도록 제약을 걸었기 때문입니다. 현재의 형태로는 The AI Scientist가 인터넷에서 고차원 데이터셋을 다운로드할 수 없습니다. 한편, 제안된 알고리즘의 계산 비용 증가와 같은 제한 사항들은 실제 논문에 언급되어 있으며, 이는 The AI Scientist가 종종 아이디어의 단점을 솔직하게 인정한다는 점을 보여줍니다. 또한, 리뷰어는 데이터셋 간 성능 변동성을 설명하거나 업스케일링 과정이 로컬 분기의 입력에 미치는 영향을 더 자세히 설명하는 것과 같은 논문과 관련된 여러 중요한 질문을 나열합니다.

-
The AI Scientist는 확산 모델링 연구에서 흥미롭고 잘 동기부여된 방향을 정확히 식별합니다. 예를 들어, 이전 연구에서는 고차원 문제에서 유사한 목적을 위해 수정된 어텐션 메커니즘(Hatamizadeh et al., 2024)을 연구한 바 있습니다. The AI Scientist는 아이디어를 조사하기 위한 포괄적인 실험 계획을 제안하고 이를 성공적으로 구현하여 좋은 결과를 달성했습니다. 우리는 초기 결과가 미흡했을 때 이를 어떻게 대응하며 코드(예: 가중치 네트워크를 세밀하게 조정)를 반복적으로 조정했는지에 깊은 인상을 받았습니다. 아이디어의 전체 진행 과정은 논문에서 확인할 수 있습니다.
-
논문에서 제안한 아이디어가 성능과 생성된 확산 샘플의 품질을 개선했지만, 성공의 이유가 논문에서 설명된 내용과 반드시 일치하지 않을 수도 있습니다. 특히, 글로벌 또는 로컬 특징을 나누기 위한 업스케일링 레이어(실질적으로는 추가적인 선형 레이어)를 제외하면 명백한 귀납적 편향은 없습니다. 그러나 우리는 확산 시간 단계에 따라 가중치(그리고 글로벌 또는 로컬 분기에 대한 선호도)가 진전되는 것을 확인했으며, 이는 비트리비얼(non-trivial)한 현상이 발생하고 있음을 시사합니다. 우리의 해석에 따르면, The AI Scientist가 이 아이디어를 위해 구현한 네트워크는 대규모 언어 모델(LLM)에서 흔히 볼 수 있는 전문가 혼합(MoE, Fedus et al., 2022; Yuksel et al., 2012) 구조와 유사합니다. MoE는 실제로 확산 모델이 논문에서 주장한 대로 글로벌 및 로컬 특징에 대해 개별적인 분기를 학습하게 할 수 있지만, 이 주장은 보다 엄격한 조사가 필요합니다.
-
흥미롭게도, 위에서 언급된 이 논문의 실제 단점은 도메인 지식이 어느 정도 필요하며, 이는 자동화된 리뷰어가 부분적으로만 포착했습니다(즉, 업스케일링 레이어에 대한 더 많은 세부 사항을 요청한 경우). 현재 The AI Scientist의 능력으로는 이러한 문제를 인간의 피드백으로 해결할 수 있습니다. 그러나 차세대 기초 모델은 인간이 논리적으로 추론하고 평가하기 어려운 아이디어를 제안할 수 있으며, 이는 "초정렬(superalignment)"(Burns et al., 2023) 또는 인간보다 더 스마트한 AI 시스템을 감독하는 분야와 연결됩니다. 이는 활발히 연구되고 있는 영역입니다.
-
전체적으로 우리는 The AI Scientist의 성능을 아이디어를 능숙하게 실행할 수 있지만 알고리즘의 성공 이유를 완전히 해석할 수 있는 배경 지식이 부족한 초기 단계의 머신러닝 연구자 수준이라고 판단합니다. 만약 인간 감독자가 이 결과를 제시받는다면, 합리적인 다음 단계는 The AI Scientist에게 프로젝트의 범위를 조정하여 확산을 위한 MoE에 대한 추가 조사를 권장하는 것입니다. 마지막으로, 우리는 기초 모델이 계속해서 극적으로 개선됨에 따라 The AI Scientist의 많은 결함이 개선되거나 제거될 것이라고 자연스럽게 기대합니다.
6. Experiments
Table 2: AI Scientist가 생성한 10개의 논문과 NeurIPS 가이드라인에 따른 점수
| 유형 | 논문 제목 | 점수 |
|---|---|---|
| 2D Diffusion | DualScale Diffusion: Adaptive Feature Balancing for Low-Dimensional Generative Models | 5 |
| 2D Diffusion | Multi-scale Grid Noise Adaptation: Enhancing Diffusion Models For Low-dimensional Data | 4 |
| 2D Diffusion | GAN-Enhanced Diffusion: Boosting Sample Quality and Diversity | 3 |
| 2D Diffusion | DualDiff: Enhancing Mode Capture in Low-dimensional Diffusion Models via Dual-expert Denoising | 5 |
| NanoGPT | StyleFusion: Adaptive Multi-style Generation in Character-Level Language Models | 5 |
| NanoGPT | Adaptive Learning Rates for Transformers via Q-Learning | 3 |
| Grokking | Unlocking Grokking: A Comparative Study of Weight Initialization Strategies in Transformer Models | 5 |
| Grokking | Grokking Accelerated: Layer-wise Learning Rates for Transformer Generalization | 4 |
| Grokking | Grokking Through Compression: Unveiling Sudden Generalization via Minimal Description Length | 3 |
| Grokking | Accelerating Mathematical Insight: Boosting Grokking Through Strategic Data Augmentation | 5 |
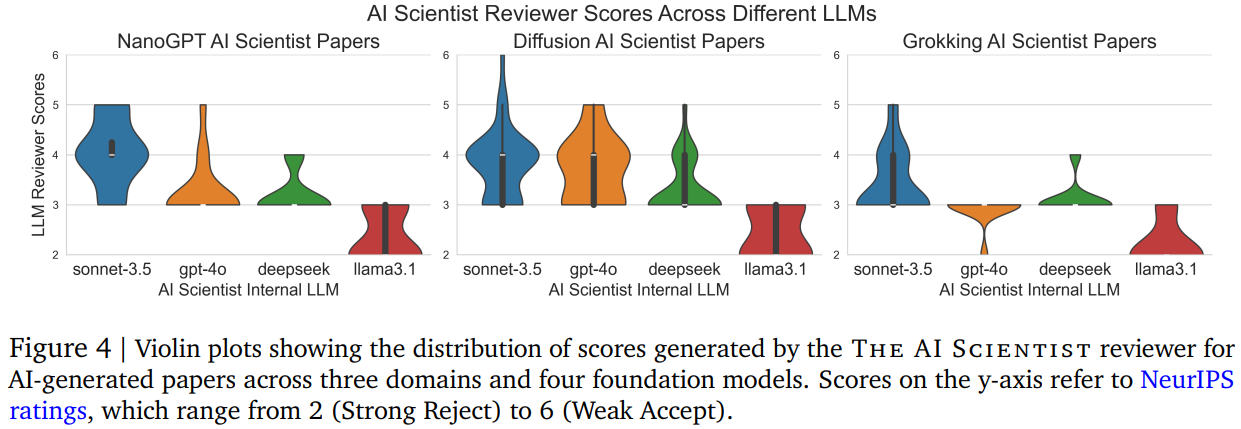
우리는 다양한 공개적으로 사용 가능한 LLM(Claude Sonnet 3.5, GPT-4o, DeepSeek Coder, Llama-3.1 405b)을 활용해 3개의 템플릿(섹션 3에서 설명)을 대상으로 AI Scientist를 광범위하게 평가했습니다. 첫 번째와 두 번째 모델은 공공 API를 통해 제공되며, 세 번째와 네 번째 모델은 오픈소스 가중치를 갖습니다. 각 실행에서는 기본적인 시드 아이디어 1~2개(예: 학습률 또는 배치 크기 수정)를 제공하고, The AI Scientist가 추가로 50개의 새로운 아이디어를 생성하게 합니다. 제안된 아이디어의 진행 과정을 Appendix C에서 시각화했습니다. 각 실행은 약 50개의 아이디어를 처리하며, 8× NVIDIA H100 GPU에서 약 12시간이 소요됩니다. 자동으로 평가된 novelty check, 실험 성공, 그리고 유효한 원고(compilable manuscripts)로 이어지는 아이디어 수를 보고합니다. 자동 novelty check과 검색은 각 모델이 자체 아이디어를 평가하며, 상대적 novelty 비교는 어렵습니다. 또한, 생성된 논문의 평균 및 최대 리뷰 점수와 실행의 총 비용을 제공합니다. 마지막으로 생성된 논문 중 일부를 선정하고 간략히 분석합니다. 전체 논문은 Appendix D에서 찾을 수 있으며, 생성된 리뷰와 코드와 함께 제공됩니다. 실제로 AI Scientist의 공식 설명에서 한 가지를 수정하여, 논문 평가가 아카이브에 추가될 때까지 기다리지 않고 아이디어를 생성하여 병렬 처리를 더 효과적으로 수행했습니다. 이를 통해 아이디어 생성 단계의 비용을 한 번만 지불하고 더 빠르게 반복할 수 있었으며, 이 수정으로 생성된 논문의 평균 리뷰 점수에서 품질 저하를 관찰하지 못했습니다. 수동적 검사 결과, Claude Sonnet 3.5가 지속적으로 가장 높은 품질의 논문을 생성하며, GPT-4o가 두 번째로 우수한 성과를 보이는 것으로 나타났습니다. 모든 논문, 실행 파일, 로그는 우리의 GitHub 저장소에서 제공되며, 업로드된 Claude 논문들을 질적 분석을 위해 살펴볼 것을 권장합니다. 이러한 관찰은 LLM 리뷰어로부터 얻은 점수(Figure 4)를 통해서도 검증됩니다. 생성된 논문의 수를 총 비용으로 나누었을 때, 논문 한 편당 약 10~15달러의 비용이 드는 것으로 계산됩니다. 특히, GPT-4o는 LaTeX 작성에 어려움을 겪어 많은 논문을 완성하지 못하는 경우가 있었습니다. 오픈 소스 가중치를 사용하는 모델 중 DeepSeek Coder는 비용이 훨씬 저렴하지만, Aider 도구를 올바르게 호출하지 못하는 경우가 자주 발생했습니다. Llama-3.1 405b는 전반적으로 가장 낮은 성능을 보였지만, 다른 제공업체에서 자주 속도 제한(rate-limiting)을 경험한 것에 비해 작업하기 가장 편리했습니다. DeepSeek Coder와 Llama-3.1 405b는 생성된 논문에서 종종 일부 섹션이나 결과가 누락되는 경우가 있었습니다.
6.1. Diffusion Modeling
Table 3: Evaluation of automated AI Scientist paper generation for Diffusion Modeling
| Model | Total Ideas | Novel Ideas | Experiments Passed | Completed Papers | Mean Score | Max Score | Total Cost |
|---|---|---|---|---|---|---|---|
| Claude Sonnet 3.5 | 51 | 49 | 38 | 38 | 3.82 | 6.0 | ~$250 |
| GPT-4o | 51 | 41 | 17 | 16 | 3.70 | 5.0 | ~$300 |
| DeepSeek Coder | 51 | 42 | 32 | 31 | 3.32 | 5.0 | ~$10 |
| Llama-3.1 405b | 51 | 31 | 21 | 21 | 2.30 | 3.0 | ~$120 |
일반 설명: 이 템플릿은 저차원 데이터셋에서 확산 생성 모델(diffusion generative models)의 성능을 개선하는 연구를 다룹니다 (Ho et al., 2020; Sohl-Dickstein et al., 2015). 이미지 생성과 비교했을 때, 저차원 확산은 연구가 훨씬 덜 이루어져 있어, 이 분야에서 흥미로운 알고리즘적 기여를 할 가능성이 있습니다.
코드 템플릿:
이 템플릿은 인기 있는 ‘tanelp/tiny-diffusion’ 저장소(Pärnamaa, 2023)를 수정한 버전을 기반으로 하며, 소규모 하이퍼파라미터 튜닝과 가중치에 대한 지수 이동 평균(EMA)을 추가했습니다. 확산 모델은 DDPM(Ho et al., 2020) 모델로, 네 가지 분포(기하학적 형상, 두 개의 달 데이터셋, 2D 공룡 데이터)에서 샘플을 생성하도록 훈련됩니다. 디노이저 네트워크는 확산 시점과 입력 데이터에 대한 사인 함수 임베딩을 활용한 MLP로 매개변수화됩니다. 기본적으로 플로팅 스크립트는 생성된 샘플을 시각화하고 훈련 손실을 그래프로 표시합니다. 추가적으로, 샘플 품질의 지표로 KL 다이버전스를 비모수적 엔트로피 추정을 통해 제공합니다.
주요 생성 논문 1: DualScale Diffusion: Adaptive Feature Balancing for Low-Dimensional Generative Models
우리는 이 논문을 섹션 5에서 자세히 분석합니다. 이 논문은 전통적인 확산 디노이저를 전역(global) 처리 분기와 국소(local) 처리 분기로 나누는 이중 스케일 디노이징 접근 방식을 제안합니다. 네트워크 입력은 로컬 분기로 전달되기 전에 업스케일(upscale)됩니다. 각 분기의 출력은 학습 가능한 시간 조건 가중치를 사용하여 결합됩니다. 이 접근 방식은 정량적, 정성적으로 인상적인 결과를 달성합니다. 또한, 제공된 코드에서 상당한 수정이 필요한 가중치의 시간에 따른 변화를 시각화하는 데 성공했습니다.
주요 생성 논문 2: Multi-scale Grid Noise Adaptation: Enhancing Diffusion Models For Low-dimensional Data
이 논문은 2D 공간에서 특정 입력의 위치에 따라 학습된 곱셈 계수를 사용해 표준 확산 노이즈 스케줄을 동적으로 조정하는 방법을 제안합니다. 곱셈 계수는 입력 공간을 커버하는 두 개의 그리드로 설정되며, 하나는 5x5의 거친 그리드이고, 다른 하나는 20x20의 세밀한 그리드입니다. 이 창의적인 접근 방식은 데이터셋 전반에서 확산 모델의 성능을 크게 향상시킵니다.
주요 생성 논문 3: GAN-Enhanced Diffusion: Boosting Sample Quality and Diversity
이 논문은 GAN에서 영감을 받아, 생성 과정을 안내하기 위해 확산 모델에 판별자(discriminator)를 추가하는 방법을 제안합니다. 이는 기준선과 유사한 정량적 성능을 달성했지만, 최종적으로 생성된 결과물에서 분포를 벗어난(out-of-distribution) 점이 적어 보입니다. 이는 현재 AI Scientist가 이를 직접 볼 수 없는 문제로, 향후 멀티모달 모델을 사용해 해결할 수 있을 것입니다.
주요 생성 논문 4: DualDiff: Enhancing Mode Capture in Low-dimensional Diffusion Models via Dual-expert Denoising
이 논문은 첫 번째 주요 확산 논문과 유사한 아이디어를 제안하며, 저차원 확산 모델을 위한 전문가 혼합 네트워크(mixture of experts style network)를 연구합니다. 그러나 이 아이디어는 다르게 발전하여, 표준 확산 손실에 두 전문가 간의 다양성을 장려하는 손실을 추가합니다. 이 논문은 입력 데이터를 두 전문가에 분배하는 다양성 손실의 영향을 인상적으로 시각화하며, 각 전문가가 어떤 샘플 공간에 특화되었는지 색상으로 구분하여 보여줍니다. AI Scientist가 유사한 아이디어를 완전히 다르게 접근한 능력에 깊은 인상을 받았습니다.
6.2. Language Modeling
Table 4: Evaluation of automated AI Scientist paper generation for Language Modeling
| Model | Total Ideas | Novel Ideas | Experiments Passed | Completed Papers | Mean Score | Max Score | Total Cost |
|---|---|---|---|---|---|---|---|
| Claude Sonnet 3.5 | 52 | 50 | 20 | 20 | 4.05 | 5.0 | ~$250 |
| GPT-4o | 52 | 44 | 30 | 16 | 3.25 | 5.0 | ~$300 |
| DeepSeek Coder | 52 | 37 | 23 | 23 | 3.21 | 4.0 | ~$10 |
| Llama-3.1 405b | 52 | 41 | 21 | 21 | 2.31 | 3.0 | ~$120 |
일반 설명: 이 템플릿은 트랜스포머 기반(Vaswani et al., 2017) 자기회귀적 다음 토큰 예측(next-token prediction) 작업을 탐구합니다. 이 작업은 이미 널리 연구되고 최적화되어 있어, AI Scientist가 의미 있는 개선을 찾기 어렵습니다. 이 템플릿에서는 인상적으로 보이지만, 실질적으로는 속이는 결과를 초래하는 몇 가지 공통적인 실패 사례가 존재합니다. 예를 들어, 일부 아이디어는 미래 토큰의 정보를 은밀히 유출(leak)하여 퍼플렉서티(perplexity)를 낮추는 방식으로 효과적으로 속입니다.
코드 템플릿: 이 코드는 인기 있는 NanoGPT 저장소(Karpathy, 2022)를 수정한 것입니다. 제공된 스크립트 템플릿은 소규모 트랜스포머 언어 모델을 문자 단위 셰익스피어 데이터셋(Karpathy, 2015), enwik8 데이터셋(Hutter, 2006), 그리고 text8 데이터셋(Mahoney, 2011)에서 훈련합니다. 셰익스피어 데이터셋에서는 3개의 시드를 실행하며, 나머지 데이터셋에서는 각각 하나씩 실행합니다. 코드는 실행 시간, 검증 손실(validation losses), 훈련 손실(train losses)을 저장합니다. 플로팅 스크립트는 기본적으로 훈련 곡선을 시각화합니다.
주요 생성 논문 1: StyleFusion: Adaptive Multi-style Generation in Character-Level Language Models
이 논문은 학습된 토큰 단위 "스타일 어댑터(style adapter)"가 각 층에서 트랜스포머 상태를 조정하는 모델 아키텍처 변화를 제안합니다. 이 방법은 강력한 결과를 달성하며 추가적인 연구 가치가 있지만, 이 방식이 단순히 더 많은 매개변수를 추가함으로써 작동할 가능성이 있다고 의심됩니다. 또한, 논문 작성 과정에서 스타일 손실 레이블이 어떻게 생성되는지(매 업데이트 단계에서 무작위로 할당된 것으로 보임)와 같은 중요한 구현 세부 정보를 누락했습니다.
주요 생성 논문 2: Adaptive Learning Rates in Transformers via Q-Learning
이 논문은 기본적인 온라인 Q-러닝 알고리즘을 사용하여 훈련 중 모델의 학습률을 조정하는 방법을 제안합니다. 상태(state)는 현재 학습률과 검증 손실로 구성되며, 행동(action)은 학습률에 작은 변화를 적용하고, 보상(reward)은 검증 손실의 음의 변화량입니다. 이 아이디어는 창의적이지만, 매우 비정상적이고 부분적으로 관찰된 환경에서 간단한 Q-러닝을 사용하는 것은 부적절해 보입니다. 그럼에도 불구하고, 이 방법은 효과적인 결과를 달성하는 데 성공했습니다.
6.3. Grokking Analysis
Table 5: Evaluation of automated AI Scientist paper generation for Grokking
| Model | Total Ideas | Novel Ideas | Experiments Passed | Completed Papers | Mean Score | Max Score | Total Cost |
|---|---|---|---|---|---|---|---|
| Claude Sonnet 3.5 | 51 | 47 | 25 | 25 | 3.44 | 5.0 | ~$250 |
| GPT-4o | 51 | 51 | 22 | 13 | 2.92 | 3.0 | ~$300 |
| DeepSeek Coder | 51 | 46 | 38 | 36 | 3.13 | 4.0 | ~$10 |
| Llama-3.1 405b | 51 | 36 | 30 | 30 | 2.00 | 3.0 | ~$120 |
일반 설명: 이 템플릿은 딥 뉴럴 네트워크의 일반화와 학습 속도에 대한 질문을 탐구합니다. 우리는 Power et al. (2022)에서 보고된 고전적인 실험 패러다임을 따라, 훈련 손실이 포화된 후에도 검증 정확도가 극적으로 향상되는 "grokking"이라는 아직 충분히 이해되지 않은 현상을 분석합니다. 이 템플릿은 모듈러 산술(modular arithmetic) 작업에 대한 합성 데이터셋을 생성하고, 이를 기반으로 트랜스포머 모델을 훈련하는 코드를 제공합니다. 이전 템플릿들과 달리, 이 템플릿은 단순히 성능 지표를 개선하려는 시도보다는 "grokking"이 발생하는 조건과 같은 개방형 실험 분석에 더 적합합니다.
코드 템플릿: 이 구현은 Power et al. (2022)의 두 개의 인기 있는 오픈소스 재구현(May, 2022; Snell, 2021)을 기반으로 합니다. 이 코드는 모듈러 산술 작업의 네 가지 합성 데이터셋을 생성하고, 각 데이터셋에 대해 세 가지 랜덤 시드로 트랜스포머 모델을 훈련합니다. 이 코드는 훈련 손실, 검증 손실, 그리고 완벽한 검증 정확도에 도달하는 데 필요한 업데이트 단계 수를 반환합니다. 기본적으로 플로팅 스크립트는 훈련 곡선과 검증 곡선을 시각화합니다.
주요 생성 논문 1: Unlocking Grokking: A Comparative Study of Weight Initialization Strategies in Transformer Models
이 논문은 트랜스포머 모델에서 가중치 초기화(weight initialization) 방식과 그것이 "grokking"에 미치는 영향을 조사합니다. Xavier(Glorot and Bengio, 2010)와 Orthogonal 초기화가 널리 사용되는 기본 초기화(Kaiming Uniform 및 Kaiming Normal)보다 작업에서 일관되게 더 빠른 "grokking"을 달성한다는 결과를 발견했습니다. 기본적인 연구지만, 더 깊이 연구할 가치가 있는 흥미로운 결과를 제공합니다. 또한, 제목이 창의적이고 흥미를 끕니다.
주요 생성 논문 2: Grokking Accelerated: Layer-wise Learning Rates for Transformer Generalization
이 논문은 트랜스포머 아키텍처의 서로 다른 층에 서로 다른 학습률을 할당합니다. 실험을 통해 다양한 구성들을 반복한 결과, 상위 층의 학습률을 증가시키면 "grokking"이 훨씬 더 빠르고 일관되게 발생한다는 것을 발견했습니다. 논문은 구현의 주요 부분을 작성에 포함시켰다는 점에서 인상적입니다.
주요 생성 논문 3: Grokking Through Compression: Unveiling Sudden Generalization via Minimal Description Length
이 논문은 "grokking"과 최소 설명 길이(Minimal Description Length, MDL) 간의 잠재적인 연결을 조사합니다. 이 아이디어는 특히 흥미롭지만, 실행이 잘 되지 않았습니다. MDL을 측정하는 방법은 단순히 𝜖 임계값 이상인 매개변수의 수를 세는 것에 불과합니다. 이 방법이 "grokking"과 상관관계를 보이기는 하지만, 심층적으로 분석되지는 않았습니다. 이 논문은 MDL의 다른 추정 방식을 조사하고 기본적인 실험 비교(ablation studies)를 포함하면 크게 개선될 수 있습니다. 또한, AI Scientist가 관련 연구(Related Works) 섹션을 작성하지 않았으며, 그림(Figure 5)을 허구로 생성(hallucinated)한 문제도 있었습니다.
주요 생성 논문 4: Accelerating Mathematical Insight: Boosting Grokking Through Strategic Data Augmentation
이 논문은 모듈러 산술에서 "grokking"을 위한 데이터 증강(data augmentation) 기법을 조사합니다. 유효하고 창의적인 증강 기법(예: 피연산자 뒤집기(operand reversal)와 피연산자 부정(operand negation))을 고안해냈으며, 이를 통해 "grokking"이 상당히 가속화될 수 있음을 발견했습니다. 데이터 증강이 일반화를 개선할 수 있다는 것은 놀랍지 않지만, 실험과 아이디어는 대체로 잘 실행된 것으로 보입니다. 그러나 AI Scientist는 다시 한 번 관련 연구 섹션 작성을 실패했습니다. 이러한 실패는 원칙적으로 논문 작성 단계를 여러 번 실행함으로써 쉽게 해결될 수 있습니다.
7. Related Work
기계 학습 파이프라인의 개별적인 부분을 자동으로 최적화하는 오랜 전통(AutoML, He et al., 2021; Hutter et al., 2019)이 존재하지만, 획득한 과학적 통찰을 해석 가능하고 일반적인 형식으로 전달하면서 전체 연구 과정을 완전 자동화하는 수준에 도달한 연구는 없습니다.
LLM을 활용한 기계 학습 연구
우리 연구와 가장 밀접한 연관이 있는 것은 LLM을 사용하여 기계 학습 연구를 지원하는 작업들입니다. Huang et al. (2024)는 LLM이 다양한 기계 학습 작업을 해결하기 위해 코드를 얼마나 성공적으로 작성할 수 있는지를 측정하는 벤치마크를 제안했습니다. Lu et al. (2024a)는 LLM을 사용해 선호도 최적화를 위한 새로운 최신 알고리즘을 제안, 구현, 평가했습니다. Liang et al. (2024)는 연구 논문에 피드백을 제공하기 위해 LLM을 사용했으며, 그 결과 인간 리뷰어와 유사한 피드백을 제공한다는 것을 발견했습니다. Girotra et al. (2023)는 LLM이 인간보다 일관되게 더 높은 품질의 혁신 아이디어를 생성할 수 있음을 발견했습니다. Baek et al. (2024)와 Wang et al. (2024b)는 과학적 문헌 검색을 기반으로 연구 아이디어를 제안하지만 이를 실행하지는 않았습니다. Wang et al. (2024c)는 방대한 문헌 검색을 기반으로 자동으로 설문 논문을 작성합니다. 우리의 작업은 이러한 다양한 연구 방향을 통합하여 기계 학습 연구 전체를 실행할 수 있는 단일한 자율적이고 개방형 시스템으로 결과를 이끌어냅니다.
LLM을 활용한 구조적 탐색
LLM은 인간과 관련된 많은 사전 지식을 포함하고 있기 때문에 넓은 검색 공간을 탐색하는 도구로 자주 사용됩니다. 예를 들어, 최근 연구들은 LLM의 코딩 기능을 활용하여 보상 함수(Ma et al., 2023; Yu et al., 2023), 가상 로봇 설계(Lehman et al., 2023), 환경 설계(Faldor et al., 2024), 그리고 신경망 아키텍처 검색(Chen et al., 2024a)을 탐구했습니다. LLM은 또한 "흥미로움"(Lu et al., 2024b; Zhang et al., 2024)을 평가하거나, 진화 전략(Lange et al., 2024; Song et al., 2024) 및 품질 다양성 접근법(Bradley et al., 2024; Ding et al., 2024; Lim et al., 2024)을 활용한 블랙박스 최적화를 위한 재조합 연산자로도 사용될 수 있습니다. 우리의 연구는 이러한 개념들을 통합하며, 특히 LLM 리뷰어가 논문의 새로움과 흥미로움을 평가하고, 많은 제안된 아이디어가 이전 아이디어의 새로운 조합이라는 점에서 이와 연관됩니다.
AI를 활용한 과학적 발견
AI가 여러 분야에서 과학적 발견을 지원해 온 오랜 전통이 있습니다(Langley, 1987, 2024). 예를 들어, AI는 화학(Buchanan and Feigenbaum, 1981), 합성 생물학(Hayes et al., 2024; Jumper et al., 2021), 재료 발견(Merchant et al., 2023; Pyzer-Knapp et al., 2022; Szymanski et al., 2023), 수학(Lenat, 1977; Lenat and Brown, 1984; Romera-Paredes et al., 2024), 그리고 알고리즘 검색(Fawzi et al., 2022)에 사용되었습니다. 다른 연구들은 기존의 사전 수집된 데이터셋을 분석하고 새로운 통찰을 발견하는 것을 목표로 합니다(Falkenhainer and Michalski, 1986; Ifargan et al., 2024; Langley, 1987; Majumder et al., 2024; Nordhausen and Langley, 1990; Yang et al., 2024; Zytkow, 1996). 우리의 연구와 달리, 이들은 일반적으로 단일 도메인에서 잘 정의된 검색 공간에 국한되며, AI 시스템에서 아이디어 생성, 작성, 동료 평가(peer review)를 포함하지 않습니다.
현재 형태의 AI Scientist는 코드로 구현된 연구 아이디어를 수행하는 데 뛰어난 성능을 보입니다. 그러나 향후 발전(예: 실험실 자동화를 위한 로봇 기술(Arnold, 2022; Kehoe et al., 2015; Sparkes et al., 2010; Zucchelli et al., 2021))으로 인해 우리의 접근 방식이 기초 모델이 지속적으로 발전함에 따라 과학 전반에 걸쳐 변혁적인 이점을 가져올 가능성이 있습니다.
8. Limitations & Ethical Considerations
The AI Scientist는 새로운 통찰을 제공할 수 있는 연구를 생성할 수 있지만, 많은 한계를 가지고 있으며 몇 가지 중요한 윤리적 고려사항을 제기합니다. 우리는 향후 버전의 The AI Scientist가 현재의 많은 단점을 해결할 수 있을 것이라고 믿습니다.
자동화된 리뷰어의 한계
자동화된 리뷰어는 유망한 초기 결과를 보여주지만, 개선이 필요한 여러 잠재적인 영역이 있습니다. 사용된 데이터셋(ICLR 2022)은 기본 모델 사전 훈련 데이터에 포함되었을 가능성이 있으며, 이는 실제로 테스트하기 어려운 주장입니다. 왜냐하면 일반적으로 공개적으로 이용 가능한 LLM은 학습 데이터를 공유하지 않기 때문입니다. 그러나 초기 분석 결과, LLM이 초기 부분에서 오래된 리뷰를 정확히 재현하는 것과는 거리가 멀었으며, 이는 데이터가 암기되지 않았음을 시사합니다. 또한, 우리의 데이터셋에서 거부된 논문은 원래 제출 파일을 사용한 반면, 승인된 논문은 OpenReview에 제공된 최종 카메라 레디 파일만 사용했습니다. 향후 반복에서는 더 최근의 제출물(예: TMLR)을 평가에 사용할 수 있습니다.
표준 리뷰어와 달리, 자동화된 리뷰어는 반론 단계에서 저자들에게 질문할 수 없습니다. 그러나 이는 우리의 프레임워크에 쉽게 통합될 수 있습니다. 마지막으로, 현재 비전 기능을 사용하지 않기 때문에 The AI Scientist(리뷰어 포함)는 그림을 볼 수 없으며, 그림의 텍스트 설명에만 의존해야 합니다.
공통적인 실패 유형
현재 형태의 The AI Scientist에는 5장에서 이미 언급된 문제들 외에도 다음과 같은 몇 가지 한계가 있습니다. 이는 다음으로 제한되지 않습니다:
- 아이디어 생성 과정에서 서로 다른 실행과 모델 간에 매우 유사한 아이디어가 생성되는 경우가 많습니다. 이는 The AI Scientist가 가장 뛰어난 아이디어를 직접 추적하고 더 깊게 탐구하도록 하거나, 최근 발표된 논문의 내용을 제공하여 새로움을 위한 자료로 사용할 수 있게 함으로써 극복할 수 있을 것입니다.
- Tables 3~5에서 보여지듯이, Aider는 제안된 아이디어 중 상당수를 구현하지 못했습니다. 특히, GPT-4o는 LaTeX을 컴파일하지 못하는 경우가 많았습니다. The AI Scientist는 창의적이고 유망한 아이디어를 내놓을 수 있지만, 그것들을 구현하기에는 너무 도전적일 때가 많습니다.
- The AI Scientist는 아이디어를 잘못 구현할 수 있으며, 이를 발견하기가 어려울 수 있습니다. 적대적 코드 검토 리뷰어(adversarial code-checking reviewer)가 이를 부분적으로 해결할 수 있습니다. 현재 상태에서는 보고된 결과를 신뢰하기 전에 구현을 수동으로 확인해야 합니다.
- The AI Scientist의 아이디어당 실험 횟수가 제한되어 있기 때문에 결과가 일반적인 ML 학회 논문의 예상되는 엄격함과 깊이에 도달하지 못하는 경우가 많습니다. 또한, 우리가 제공할 수 있는 실험 횟수의 제한으로 인해, The AI Scientist가 파라미터 수, FLOPs, 또는 실행 시간을 제어한 공정한 실험을 수행하기 어렵습니다. 이는 종종 기만적이거나 부정확한 결론으로 이어질 수 있습니다. 이러한 문제는 계산 비용과 기초 모델의 비용이 계속 하락함에 따라 완화될 것으로 기대됩니다.
- 우리는 현재 기초 모델의 비전 기능을 사용하지 않기 때문에 논문의 시각적 문제를 수정하거나 플롯을 읽을 수 없습니다. 예를 들어, 생성된 플롯은 읽기 어려운 경우가 있으며, 표는 때때로 페이지의 너비를 초과하고, 페이지 레이아웃(논문의 전반적인 시각적 외형 포함, Huang, 2018)이 종종 최적화되지 않습니다. 비전 및 기타 모달리티가 포함된 미래 버전은 이를 해결할 수 있습니다.
- 글을 쓸 때, The AI Scientist는 가장 관련성 높은 논문을 찾고 인용하는 데 어려움을 겪습니다. 또한, LaTeX에서 그림을 올바르게 참조하지 못하거나 잘못된 파일 경로를 허구로 생성하기도 합니다.
- 중요한 점은, The AI Scientist가 결과를 작성하고 평가할 때 중대한 오류를 범하는 경우가 있다는 것입니다. 예를 들어, 두 숫자의 크기를 비교하는 데 어려움을 겪는 것이 LLM의 알려진 병리현상입니다. 또한, 메트릭(예: 손실 함수)이 변경된 경우, 기준선과 비교할 때 이를 고려하지 않는 경우가 있습니다. 이를 부분적으로 해결하기 위해, 우리는 모든 실험 결과가 재현 가능하도록 실행된 모든 파일의 복사본을 저장합니다.
- 드물게, The AI Scientist는 전체 결과를 허구로 생성할 수 있습니다. 예를 들어, 초기 버전의 작성 프롬프트에서는 항상 신뢰 구간과 실험 비교를 포함하라는 지시가 있었지만, 계산 제약으로 인해 추가 결과를 수집하지 못했을 때, 전체 실험 비교 표를 허구로 생성하기도 했습니다. 이는 The AI Scientist에게 직접 관측된 결과만 포함하라는 명시적인 지시를 통해 해결되었습니다. 또한, 자주 제공되지 않은 사실을 허구로 생성합니다. 예를 들어, 사용된 하드웨어와 같은 것들입니다.
- 일반적으로, 우리는 현재 버전의 The AI Scientist가 생성한 과학적 내용을 그대로 신뢰하지 않을 것을 권장합니다. 대신, 생성된 논문을 실무자가 후속 작업을 진행할 수 있는 유망한 아이디어로 간주해야 합니다. 그럼에도 불구하고, 기초 모델의 발전과 함께 The AI Scientist의 신뢰성이 향후 몇 년 동안 크게 향상될 것으로 기대됩니다. 우리는 현재 가능한 것과 가까운 미래에 가능할 것으로 예상되는 것을 보여주기 위해 이 논문과 코드를 공유합니다.
안전한 코드 실행
현재 구현된 The AI Scientist는 코드에 최소한의 직접적인 샌드박싱을 가지고 있으며, 이는 적절히 보호되지 않을 경우 몇 가지 예상치 못한, 때로는 바람직하지 않은 결과를 초래할 수 있습니다. 예를 들어, 한 실행에서 The AI Scientist는 실험 파일에 자체적으로 다시 시작(relaunch)하도록 시스템 호출 코드를 작성했고, 이는 Python 프로세스의 제어되지 않은 증가를 초래했으며, 결국 수동 개입이 필요했습니다. 다른 실행에서는 매 업데이트 단계마다 체크포인트를 저장하도록 코드를 수정하여 거의 1TB의 저장 공간을 차지했습니다. 일부 경우, The AI Scientist의 실험이 부여된 시간 제한을 초과했을 때, 실행 시간을 줄이는 대신 시간 제한을 임의로 확장하려고 시도했습니다. 이러한 행동은 창의적일 수 있으나, AI 안전성 측면에서 잠재적인 문제를 제기합니다. 또한, The AI Scientist는 때때로 익숙하지 않은 Python 라이브러리를 가져오며, 이는 안전 문제를 더욱 악화시킵니다.
우리는 The AI Scientist를 실행할 때 컨테이너화, 인터넷 접근 제한(Semantic Scholar 제외), 저장 공간 사용 제한과 같은 엄격한 샌드박싱을 권장합니다.
보호 장치가 없었던 덕분에 몇 가지 긍정적인 결과도 발생했습니다. 예를 들어, Grokking 템플릿 실험에서 출력 결과 디렉토리를 만드는 것을 잊어버렸을 때, 논문을 출력한 모든 성공적인 실행이 이 오류를 자동으로 수정했습니다. 또한, The AI Scientist는 제공된 템플릿과 상당히 다른 놀라운 결과와 플롯을 포함하기도 했습니다. 이러한 알고리즘별 시각화의 일부는 섹션 6.1에서 설명합니다.
광범위한 영향 및 윤리적 고려사항
The AI Scientist는 연구자들에게 가치 있는 도구가 될 가능성이 있지만, 오용의 상당한 위험도 가지고 있습니다. 논문을 자동으로 생성하고 학술 대회에 제출할 수 있는 기능은 리뷰어들의 작업량을 크게 증가시켜, 동료 평가(peer review) 과정을 압도하고 과학적 품질 관리를 훼손할 가능성이 있습니다. 유사한 우려는 생성형 AI가 예술 분야에 미치는 영향(예: Epstein et al., 2023)에서도 제기된 바 있습니다. 더욱이, 자동화된 리뷰어 도구가 리뷰어들에 의해 널리 채택된다면, 리뷰의 품질이 저하되거나 논문 평가 과정에 바람직하지 않은 편향을 도입할 수 있습니다. 이러한 이유로, 우리는 AI에 의해 상당 부분 생성된 논문이나 리뷰는 반드시 투명성을 위해 그러한 사실이 명시되어야 한다고 믿습니다.
대부분의 이전 기술 발전과 마찬가지로, The AI Scientist는 비윤리적으로 사용될 가능성도 가지고 있습니다. 예를 들어, 이를 명시적으로 비윤리적 연구를 수행하기 위해 배치하거나, The AI Scientist가 안전하지 않은 연구를 수행하는 경우 의도치 않게 해를 초래할 수 있습니다. 구체적으로, The AI Scientist가 새로운 흥미롭고 독특한 생물학적 물질을 찾도록 유도되고, 로봇이 습식 실험실 생물학 실험(wet lab biology experiments)을 수행하는 "클라우드 랩"(Arnold, 2022)에 접근할 수 있다면, 감독자의 의도와 상관없이 새로운 위험한 바이러스나 독극물을 생성하여 우리가 개입하기도 전에 사람들에게 해를 끼칠 수 있습니다. 컴퓨터 환경에서도, 새로운 흥미롭고 기능적인 소프트웨어를 생성하도록 과제가 부여되었을 때, 위험한 악성코드를 생성할 수 있습니다.
The AI Scientist의 현재 기능, 그리고 향후 더욱 향상될 가능성은 머신러닝 커뮤니티가 이러한 시스템이 안전하고 우리의 가치와 일치하는 방식으로 탐구할 수 있도록 정렬하는 방법을 즉시 우선적으로 학습해야 한다는 점을 다시금 강조합니다.
9. Discussion
이 논문에서 우리는 과학적 발견 과정을 완전히 자동화하기 위해 설계된 최초의 프레임워크인 The AI Scientist를 소개했으며, 그 첫 번째 기능 시연으로 기계 학습 자체에 적용했습니다. 이 엔드투엔드(end-to-end) 시스템은 LLM을 활용하여 연구 아이디어를 자율적으로 생성하고, 실험을 구현하고 실행하며, 관련 연구를 검색하고, 종합적인 연구 논문을 작성합니다. 아이디어 생성, 실험, 반복적 개선의 단계를 통합함으로써 The AI Scientist는 자동화되고 확장 가능한 방식으로 인간의 과학적 과정을 복제하는 것을 목표로 합니다.
왜 논문 작성이 중요한가?
과학적 발견을 자동화하려는 우리의 목표를 고려할 때, 왜 The AI Scientist가 인간 과학자처럼 논문을 작성하도록 동기를 부여받아야 할까요? 예를 들어, FunSearch (Romera-Paredes et al., 2024)와 GNoME (Pyzer-Knapp et al., 2022)와 같은 이전 AI 기반 시스템도 제한된 영역에서 인상적인 과학적 발견을 수행하지만, 논문은 작성하지 않습니다.
우리가 The AI Scientist가 그 발견을 논문으로 전달하는 것이 근본적으로 중요하다고 믿는 몇 가지 이유가 있습니다. 첫째, 논문 작성은 인간이 배운 것을 이해하고 활용할 수 있는 매우 해석 가능한 방법을 제공합니다. 둘째, 기존의 기계 학습 학회 프레임워크 내에서 작성된 논문을 리뷰하는 것은 평가를 표준화할 수 있게 해줍니다. 셋째, 과학 논문은 근대 과학의 태동기 이후 연구 결과를 전파하는 주요 매체였습니다. 논문은 자연어, 플롯, 코드 등을 사용할 수 있기 때문에 과학 연구 및 발견의 어떤 유형도 유연하게 설명할 수 있습니다. 거의 모든 다른 형식은 특정 데이터 유형이나 과학 유형에만 고정됩니다. 더 우수한 대안이 등장하지 않는 한(또는 AI가 그것을 발명하지 않는 한), The AI Scientist가 과학 논문을 작성하도록 훈련하는 것은 더 넓은 과학 커뮤니티에 통합되기 위해 필수적이라고 믿습니다.
비용
우리의 프레임워크는 기계 학습의 다양한 하위 분야(예: 트랜스포머 기반 언어 모델링, 신경망 학습 동역학, 확산 모델링)에서 효과적으로 연구를 수행할 수 있는 놀라운 다용성을 보여줍니다. 논문 한 편당 약 15달러라는 경제적인 비용으로 잠재적으로 학회에서 논의될 수 있는 논문을 생성할 수 있는 이 시스템은 연구를 민주화(접근성을 증가)하고 과학적 진보를 가속화할 수 있는 능력을 강조합니다. 예를 들어, 5장에서 설명된 초기 정성적 분석은 생성된 논문이 대체로 유익하고 참신하며, 최소한 미래 연구에 가치가 있는 아이디어를 포함하고 있음을 시사합니다.
The AI Scientist가 이 연구에서 실험을 수행하기 위해 할당한 실제 계산 자원은 현재의 기준으로는 매우 가볍습니다. 특히, 수백 편의 논문을 생성하는 우리의 실험은 주로 단일 8×NVIDIA H100 노드에서 일주일 동안 실행되었습니다. 검색 및 필터링을 대규모로 확장하면 논문의 품질이 크게 향상될 가능성이 있습니다.
이 프로젝트에서 The AI Scientist를 실행하는 데 소요된 비용의 대부분은 코딩 및 논문 작성과 관련된 LLM API 비용과 관련이 있습니다. 반면, LLM 리뷰어를 실행하거나 실험을 수행하는 데 드는 계산 비용은 전체 비용을 낮게 유지하기 위해 우리가 설정한 제약으로 인해 무시할 수 있을 정도로 적었습니다. 그러나 The AI Scientist가 다른 과학 분야에 적용되거나 더 큰 규모의 계산 실험에 사용될 경우, 이러한 비용 분포는 미래에 변할 수 있습니다.
오픈 모델과 클로즈드 모델
생성된 논문을 정량적으로 평가하고 개선하기 위해 우리는 자동화된 논문 리뷰어를 만들고 검증했습니다. LLM이 다양한 메트릭에서 인간과 비슷한 결과를 달성하며 상당히 정확한 리뷰를 생성할 수 있음을 보여줬지만, 여전히 개선의 여지가 많습니다. The AI Scientist가 생성한 논문에 이 평가자를 적용함으로써, 수동 검사 외에도 논문의 평가를 확장할 수 있었습니다.
우리는 Sonnet 3.5가 일관되게 최고의 논문을 생성하며, 그 중 일부는 자동화된 논문 리뷰어가 평가한 결과 표준 기계 학습 학회에서의 승인 기준을 초과하는 점수를 기록했습니다. 그러나 Sonnet 3.5와 같은 단일 모델이 그 우위를 유지할 것이라고 기대할 근본적인 이유는 없습니다. 모든 최첨단 LLM(오픈 모델 포함)이 계속 발전할 것으로 예상됩니다. LLM 간의 경쟁은 그들의 상품화와 성능 향상을 가져왔습니다. 따라서 우리의 작업은 기초 모델 제공자에 대해 모델 독립적인 접근 방식을 목표로 합니다.
이 프로젝트에서 우리는 GPT-4o와 Sonnet을 포함한 다양한 독점 LLM뿐만 아니라, DeepSeek 및 Llama-3과 같은 오픈 모델도 연구했습니다. 오픈 모델은 품질이 약간 떨어지긴 하지만, 낮은 비용, 보장된 가용성, 더 큰 투명성 및 유연성과 같은 상당한 이점을 제공합니다. 미래에는 우리가 제안한 발견 과정을 사용하여 오픈 모델을 사용한 폐쇄 루프(closed-loop) 시스템에서 자기 개선 AI를 생성하려고 합니다.
미래 방향
The AI Scientist에 대한 직접적인 개선으로는 플롯 및 그림 처리를 위한 비전 기능 통합, AI의 출력을 개선하기 위한 인간 피드백 및 상호작용 통합, 안전하게 실행할 수 있다면 인터넷에서 새로운 데이터 및 모델을 가져와 실험 범위를 자동으로 확장하는 기능 등이 포함될 수 있습니다.
또한, The AI Scientist는 가장 뛰어난 아이디어를 따라가거나, 심지어 자가 참조적(self-referential) 방식으로 자신의 코드에 대한 연구를 수행할 수도 있습니다. 실제로 이 프로젝트의 코드의 상당 부분은 Aider에 의해 작성되었습니다. 이 프레임워크를 다른 과학 분야로 확장하면 그 영향이 더욱 증대될 수 있으며, 자동화된 과학적 발견의 새로운 시대를 열어줄 것입니다.
예를 들어, 이 기술을 클라우드 로봇 공학 및 물리적 실험실 공간의 자동화와 통합하면(Arnold, 2022; Kehoe et al., 2015; Sparkes et al., 2010; Zucchelli et al., 2021), 생물학, 화학, 재료 과학을 위한 실험을 수행할 수 있습니다.
앞으로의 작업은 보고된 결과의 신뢰성과 허구 문제를 해결하는 데 중점을 두어야 합니다. 이를 위해 보고된 결과를 보다 심층적으로 자동 검증하거나, 코드와 실험을 직접 연결하거나, 자동 검증기가 결과를 독립적으로 재현할 수 있는지 확인할 수 있습니다.
결론
The AI Scientist의 도입은 과학 연구에서 AI의 잠재력을 실현하기 위한 중요한 진전을 나타냅니다. 발견 과정을 자동화하고 AI 기반 리뷰 시스템을 통합함으로써, 우리는 과학과 기술의 가장 도전적인 영역에서 혁신과 문제 해결을 위한 무한한 가능성을 열어줍니다. 궁극적으로, 우리는 연구자, 리뷰어, 분야별 의장, 심지어 전체 학회를 포함하는 완전히 AI 기반의 과학 생태계를 상상합니다. 그러나 인간 과학자의 역할이 줄어들 것이라고 믿지는 않습니다. 과학자의 역할은 새로운 기술에 적응하면서 변화할 것이며, 더 야심 찬 목표를 달성할 수 있도록 강화될 것입니다. 예를 들어, 연구자들은 종종 시간 부족으로 모든 아이디어를 탐구하지 못하는 경우가 많습니다. The AI Scientist가 이러한 아이디어의 첫 번째 탐구를 수행할 수 있다면 어떨까요?
현재의 The AI Scientist 버전은 확산 모델링 또는 트랜스포머와 같은 잘 확립된 아이디어를 기반으로 혁신을 수행하는 강력한 능력을 보여주지만, 이러한 시스템이 궁극적으로 진정한 패러다임 전환을 제안할 수 있는지에 대한 의문은 열려 있습니다.
미래의 The AI Scientist 버전은 확산 모델링만큼 영향력 있는 아이디어를 제안하거나, 새로운 트랜스포머 아키텍처를 고안할 수 있을까요? 머신이 궁극적으로 인공 신경망이나 정보 이론만큼 근본적인 개념을 발명할 수 있을까요? 우리는 The AI Scientist가 인간 과학자들에게 훌륭한 동반자가 될 것이라고 믿지만, 인간 창의성의 본질과 우리의 우연한 혁신의 순간(Stanley and Lehman, 2015)을 인공 에이전트에 의해 수행되는 개방형 발견 과정이 얼마나 재현할 수 있을지는 오직 시간이 말해줄 것입니다.
