참고논문 : Attention is all you need
참고영상 : https://www.youtube.com/watch?v=kyIw0nHoG9w
https://www.youtube.com/watch?v=AA621UofTUA
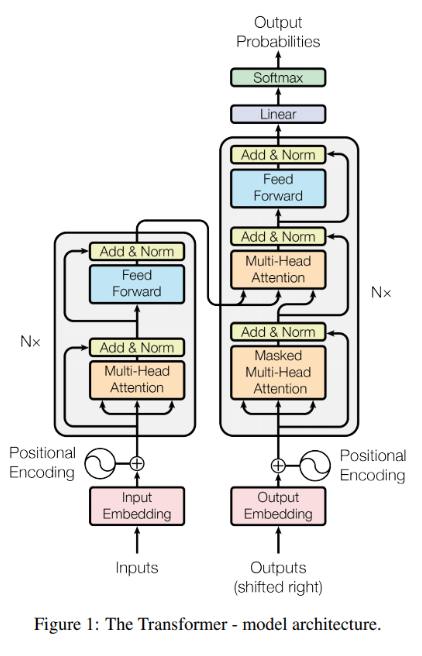
앞절에서는 Transformer의 구조에대해 simple하게 살펴보았다. 이번 절에서는 좀더 구체적으로 살펴보도록 한다.
Embedding Layer
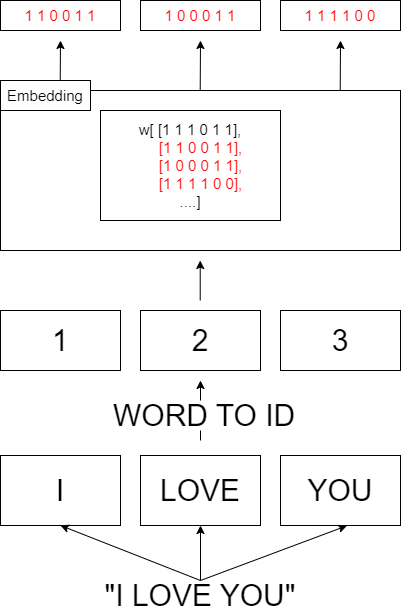
임베딩 레이어는 한마디로 단어를 숫자벡터로 바꿔주는 계층이다. ex) 'LOVE' -> [1,0,0,0,1,1]
임베딩 레이어에서는, 이 숫자벡터를 행렬형태 W로 저장한다. 그런 다음 input sequence를 받는데, 단어형태가 아닌, 단어의 idx를 입력으로 받는다. 예를들어 i love you 라는 단어를 transformer의 입력으로 받는다고 가정하고, i, love, you 각각의 단어의 id가 1,2,3 일때 이 embedding layer에서는 [1,2,3]을 입력으로 받는 것이다. 이때 output은 W[1],W[2],W[3]이 된다.
즉 임베딩 계층에서의 forward는 단어의 id에 해당하는 W의 행을 그대로 출력해주는 과정이다.
backward는 앞층으로부터 전해진 기울기를 W에 갱신해주면 된다. 이때 이 갱신해주는 과정에서 idx가 중복될 수 있다.
예를들어 'i say hello you say goodbye' 라는 문장이 있다고 할 때, say라는 단어가 중복이 된다. 이렇게 단어 중복이 일어나면, 입력값에 say에 해당하는 id 역시도 중복이 일어나고, 역전파가 행해진다고 했을때 say에 해당하는 가중치값이 두번 할당이 되기 때문에 첫번째 say의 가중치 갱신은 무시된다. 따라서 가중치를 할당하는 것이아닌, 더하기를 통해서 갱신을 해주어야 한다.
Positional Encoding
트랜스 포머에서는 입력문장을 RNN,LSTM과 같이 단어 순서대로 하나씩 받는 것이 아니라 문장 전체를 한번에 병렬적으로 받는다. 따라서 입력문장의 단어의 위치정보를 학습과정에서 알 수 없기 때문에, 각 단어 별 Embedding vector에 Positioning Encoding을 통해, 위치정보를 추가해 주어야 한다. 위치정보를 추가하는 방법은 다음과같은 식을 Embedding vector에 더해줌으로써 추가해준다.

여기서 d_model은 임베딩 벡터의 차원을 의미한다. 예를들어 위의 [1,0,0,0,1,1]의 경우 6차원이 된다. pos는 입력 문장에서 임베딩 벡터의 위치를 나타낸다.'I love you'라는 문장이 주어졌을 때, I의 pos는 0, love의 pos는 1, you의 pos는 2가 된다. i는 embedding 벡터 내에서의 index를 의미한다. love의 embedding vector가 [1,0,0,0,1,1]이라고 할때 1,0,0,0,1,1 각각의 i는 0,1,2,3,4,5가 되는 셈이다. 이때 이 i가 짝수일 경우, sin함수로 계산하며, 홀수면 cos함수로 계산한다. 이렇게 계산된 포지셔널 인코딩 값을 기존의 embedding 값에 더해주고, transformer의 입력 문장은 이렇게 위치정보를 포함한 embedding 값으로 재탄생하게 된다.
Multihead Attention
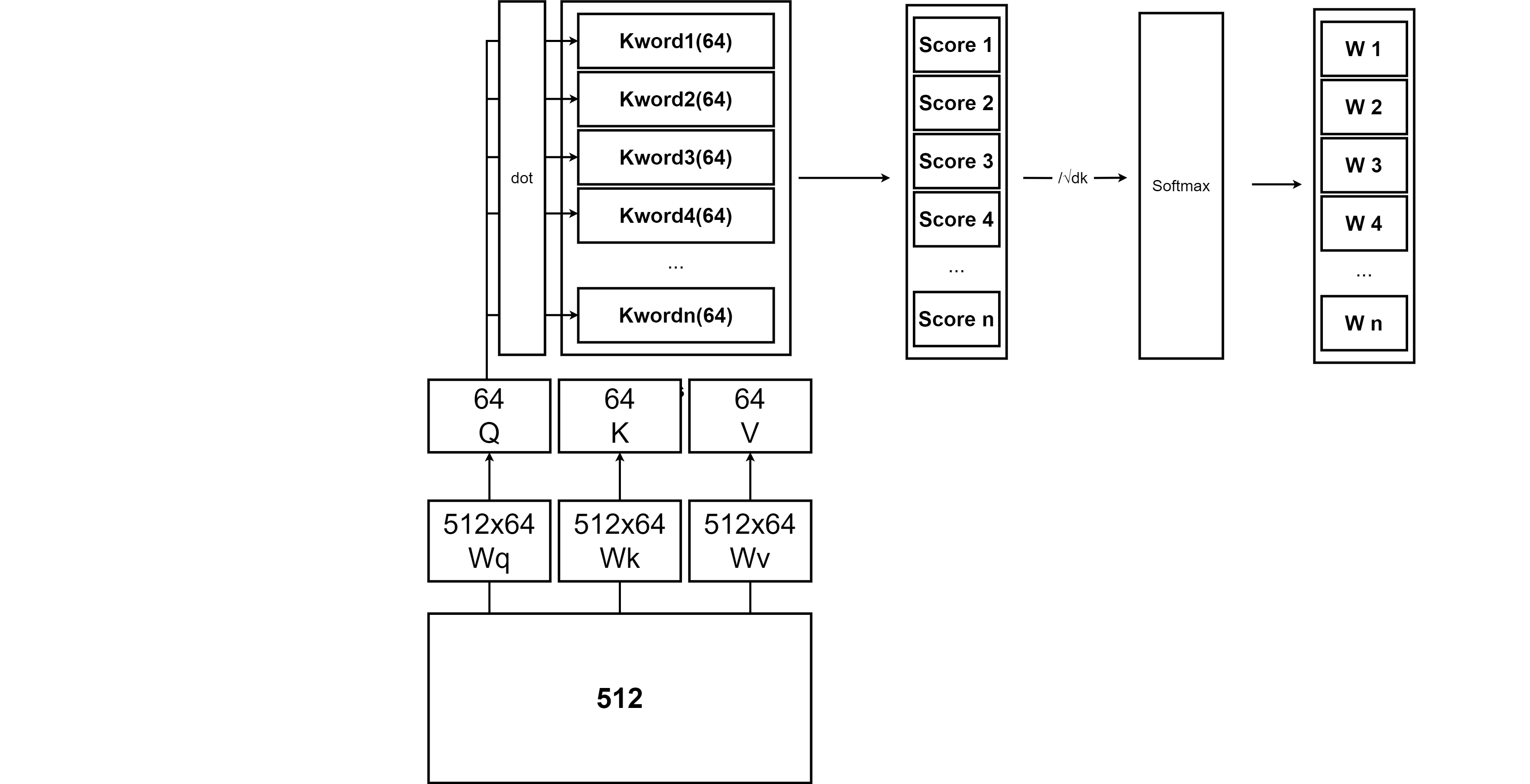
이렇게 Positional Encoding을 거친 각 단어들의 임베딩 벡터들은 다시한번 가중치에 의해 Query, Key, Value vector로 나뉘어진다. 논문에서 Q,K,V 벡터의 차원은 64차원으로 설정이 되었으므로 각 가중치는 512 * 64가 된다.
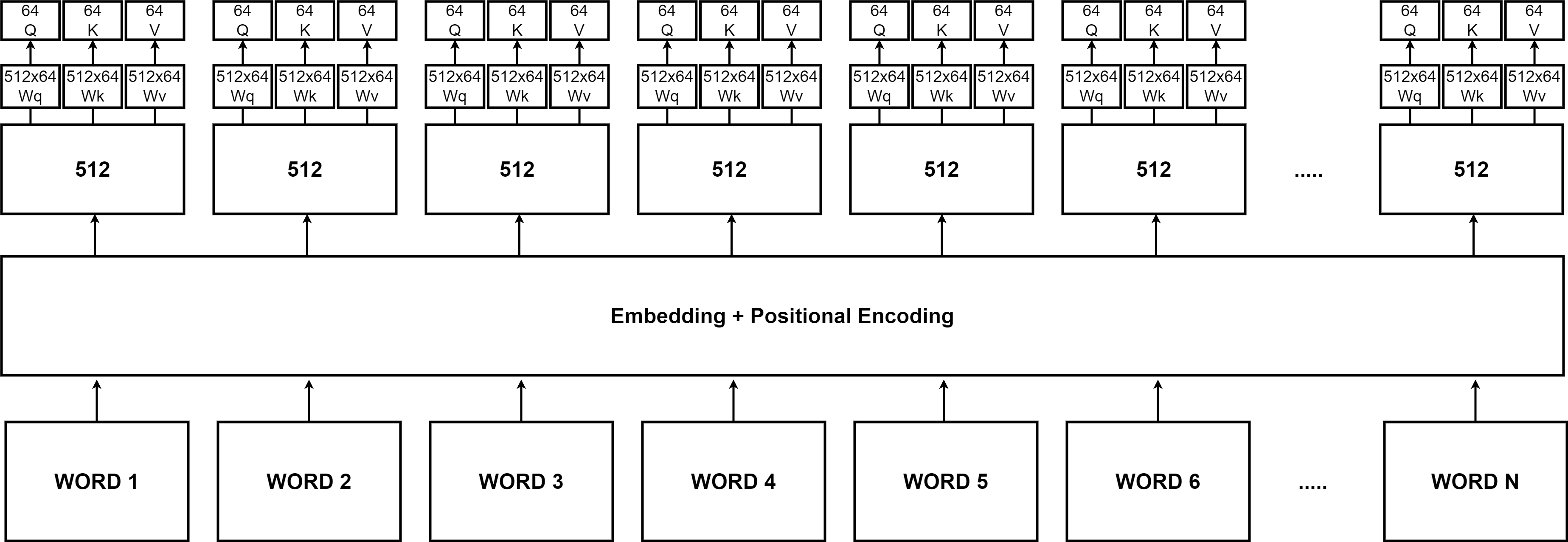
그림을 통해서 보면 일련의 과정을 쉽게 파악할 수 있다. 각각의 단어들은 Embedding layer와 Positional Encoding layer를 거쳐 512 차원의 벡터로 변환이 되고, 이 512 차원의 벡터에 512X64 차원의 행렬 Wq,Wk,Wv를 행렬곱해서, 64차원의 Q,K,V 벡터를 만든다. 트랜스포머에서는 이렇게 만들어진 Q,K,V 벡터를 이용해서 Self-Attention을 먼저 진행한다.
https://velog.io/@khko99/%EB%94%A5%EB%9F%AC%EB%8B%9D-9-Attention
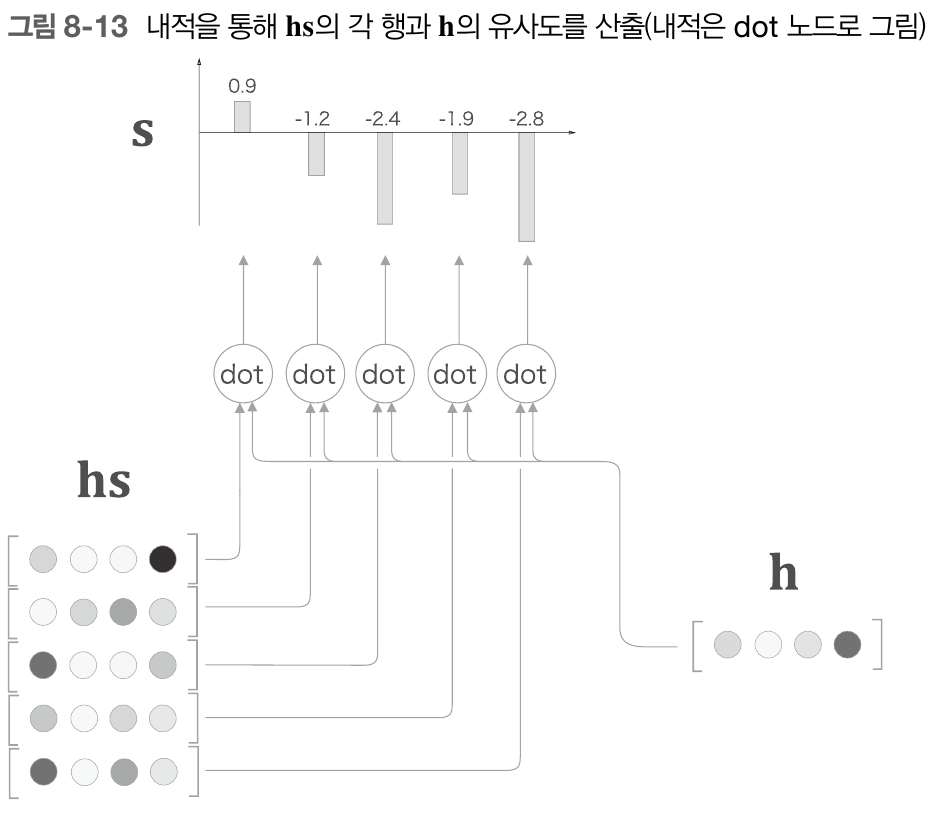
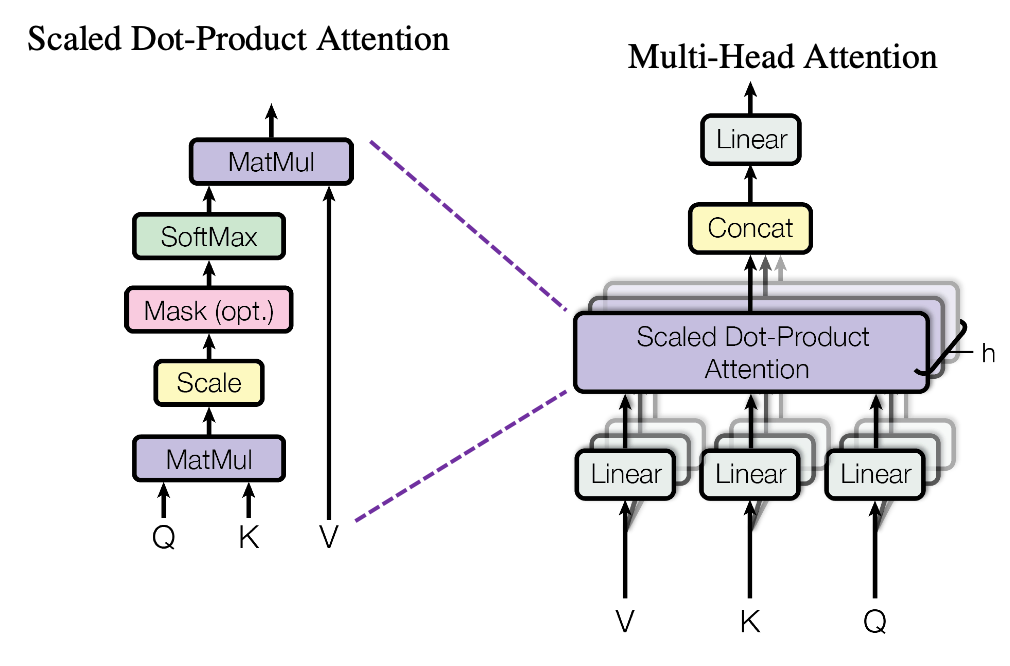
앞서 봤던 seq2seq 구조에서 Attention에서는 encoder 파트에서의 히든 벡터들의 모음인 hs와 현재 decoder서의 출력값 h벡터와의 내적을 통해 Attention score를 구하고 이 Attention Score에 Softmax함수를 적용해 가중치 a를 구한 다음 hs * a를 통해서 출력값을 얻어냈었다. 트랜스포머에서의 self-Attention도 이와 거의 비슷하다. 그저 hs와 h대신에 Q,K,V를 사용하는것과 같다.
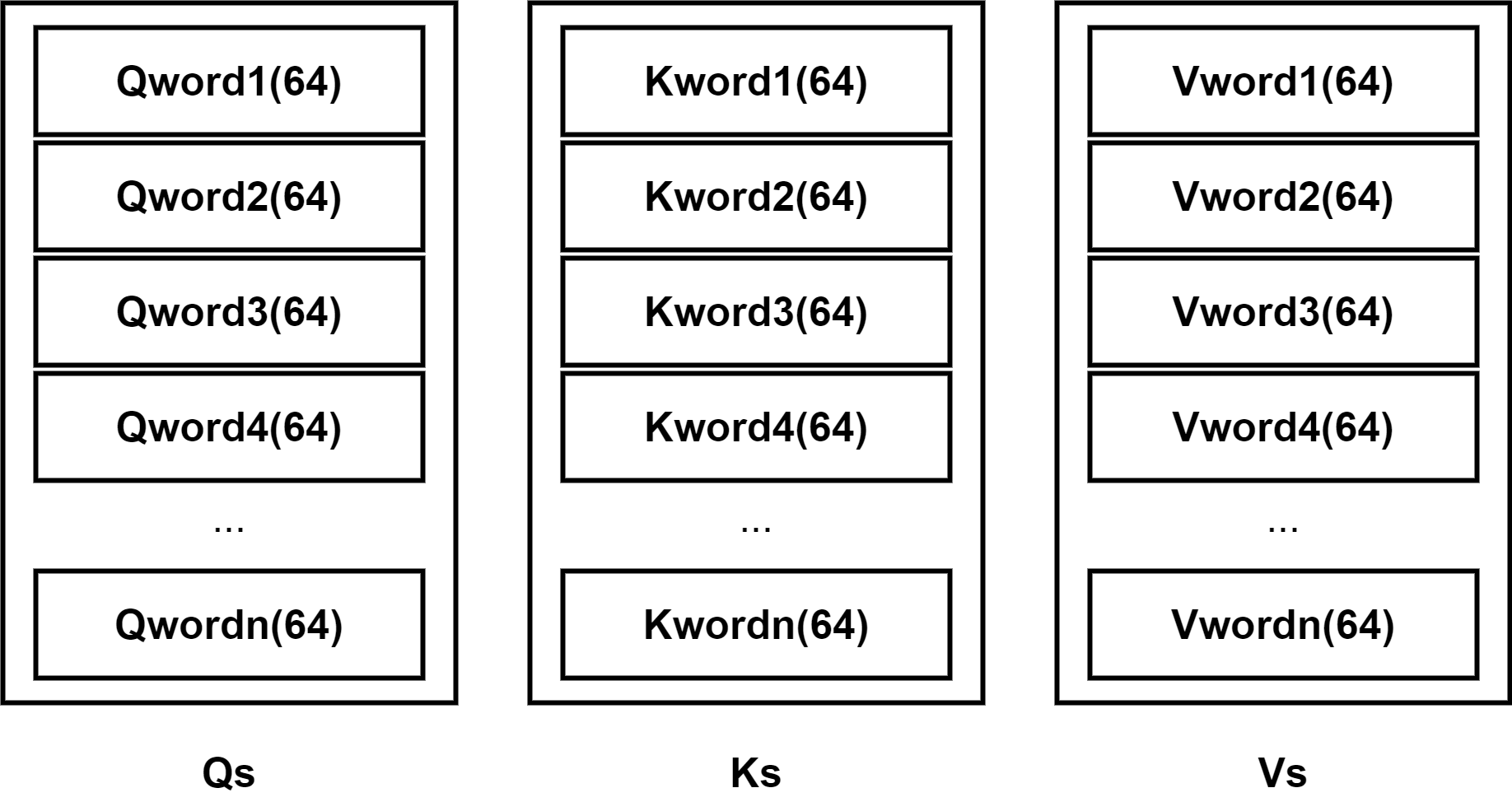
인코더에서 각각 단어들에 대한 Q,K,V 벡터들의 집합들을 Qs,Ks,Vs라 할때 이를 이용해 먼저 Attention Score를 계산한다. 앞선 Attention에서는 hs와 h의 내적을 통해서 구했지만, 트랜스포머에서는 Q와 Ks의 내적을 통해서 Attention Score를 계산한다.
Ks의 각 행의 벡터와 Q의 내적을 구하면 각 단어에대한 Score가 나온다. 이렇게 나온 Score를 스케일링을 해준 다음, Softmax 함수를 적용해주면 최종적으로 Attention Weight이 나오게 된다. 스케일링 할 때는 Attention 스코어에 √dk를 나눠주며, 이때 dk는 key 벡터의 차원으로, 본 논문에서는 key 벡터의 차원이 64로 나와있기 때문에 8을 나눠준 셈이 되는 것이다.
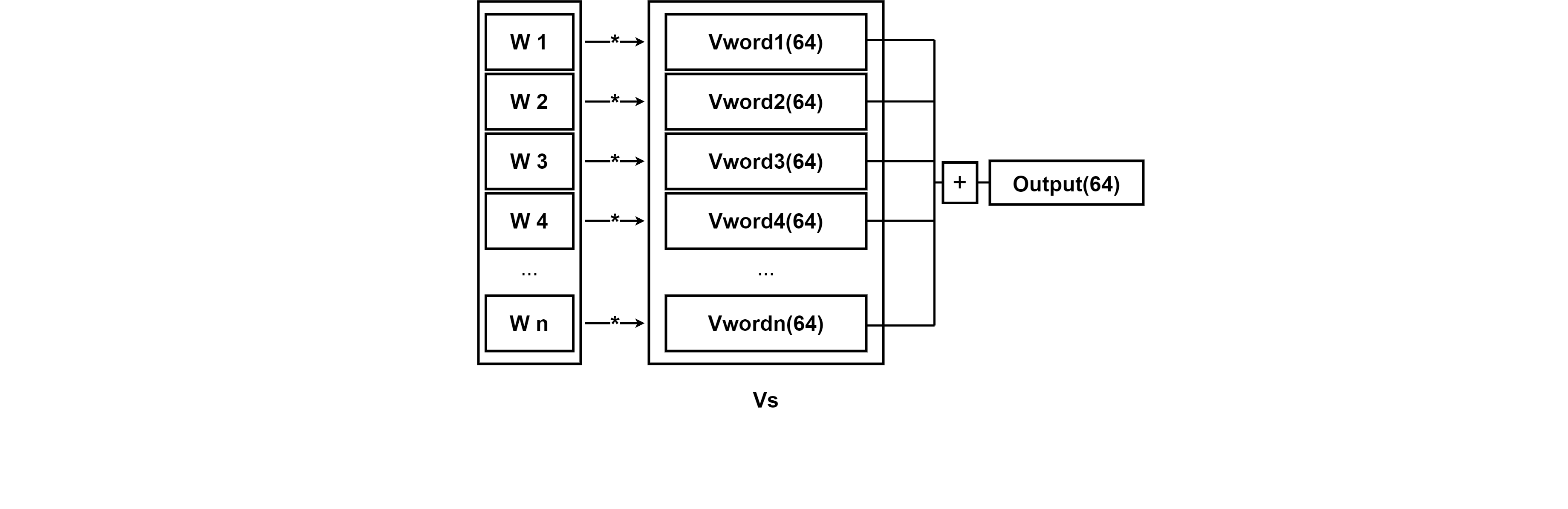
이렇게 나온 Attention Weight을 Vs에 적용한다음 Sum을 하면 최종적인 Attention에서의 출력값이 나오게 된다. seq2seq Attention에서는 멕락벡터 C가 나온것과 같은 의미이다.
위의 과정을 식으로 나타내면 다음과 같다.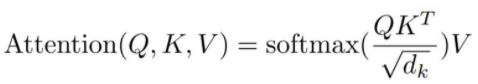
여기까지의 과정이 Attention 레이어 하나의 과정이고, 실제 트랜스포머를 구현할 때에는 Multi-head Attention을 사용한다. Multi-head Attention은 간단히 말해서 앞서 봤던 Attention 메커니즘을 여러번 진행하는 것을 의미한다. 본 논문에서는 총 8개의 Attnetion layer를 설정한다. 앞선 과정을 통해서 Attention 메커니즘을 사용하면 64차원의 output이 나온다는 것을 알 수 있었다. 이 과정을 8번 진행하면 64차원의 output이 8개가 나온다는 것을 의미하고 64*8 = 512 차원의 output을 얻게된다. 512차원은 처음 입력 임베딩의 차원과 같다.
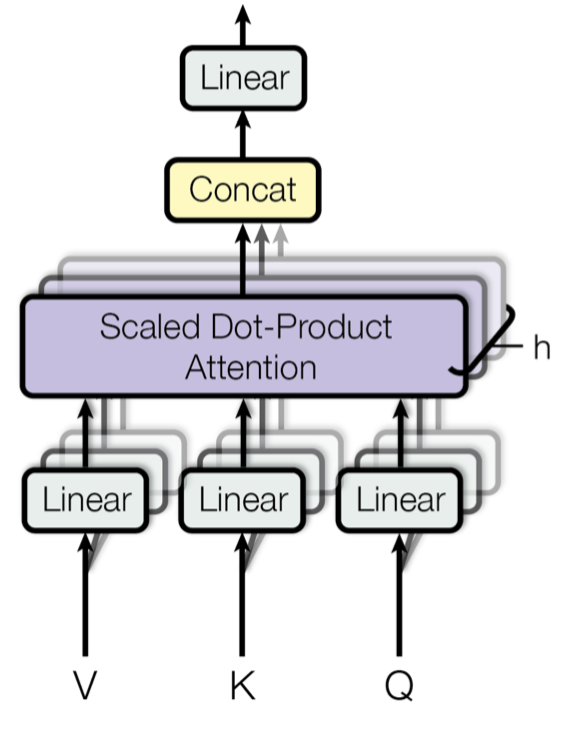
이렇게 얻어진 output을 concat을 통해 붙여 입력 임베딩과 차원을 맞춰준다.
Add & Norm
Add & Norm 계층에서는 Residual learning과 Normalization이 이루어진다. Self Attention의 입력으로 들어가는 각단어의 벡터와 Self Attention 이후 단어의 벡터를 더한후 , 이 더한 벡터들에 대한 Layer Normilization을 진행한다.

Feed Forward
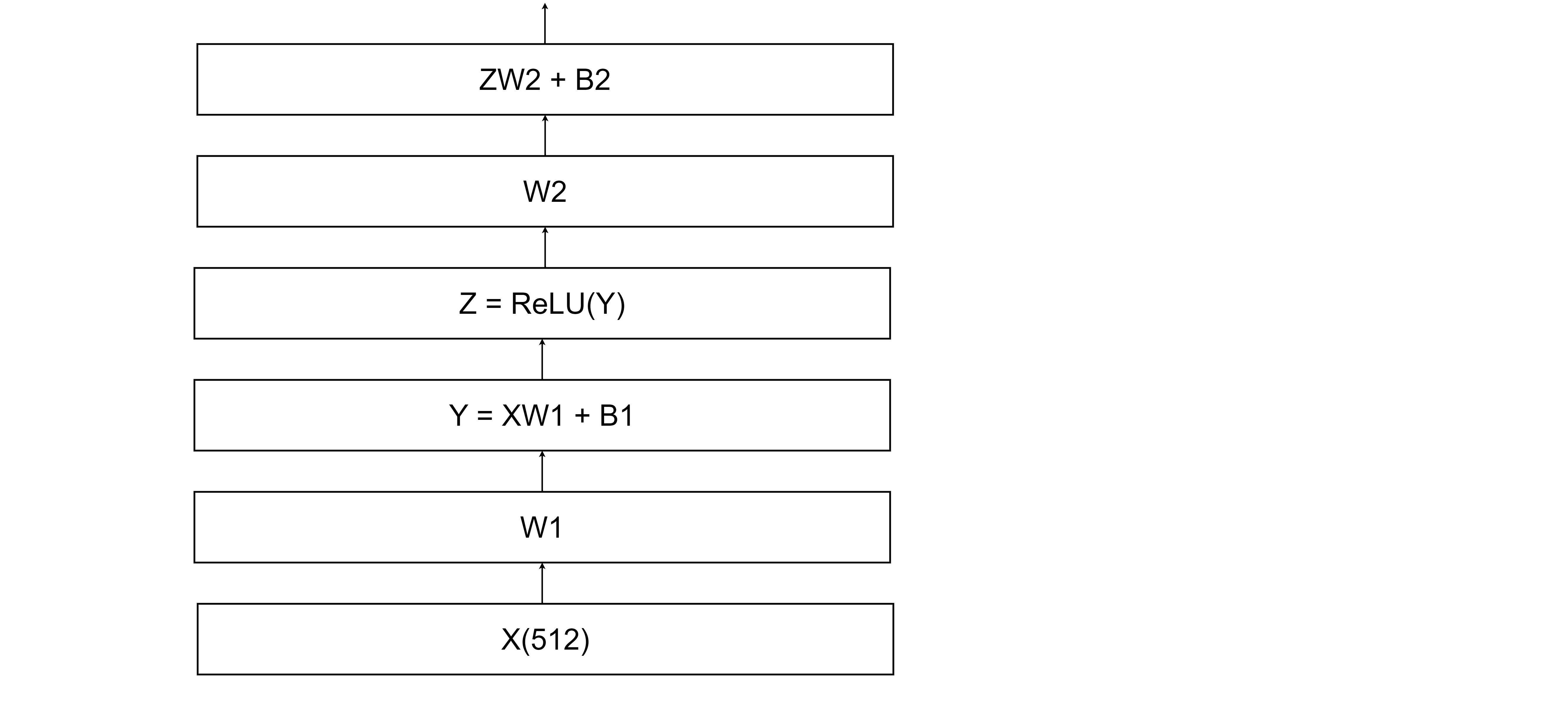
Feed Forward 계층에서는 두개의 Fully Connected layer로 구성한다. 각 단어마다 독립적으로 적용하며 활성화 함수로는 ReLU함수를 사용한다.
FFN(x) = max(0,xW1+B1)W2+b2
그림으로 표현하면 대략 다음과 같다.
Encoder
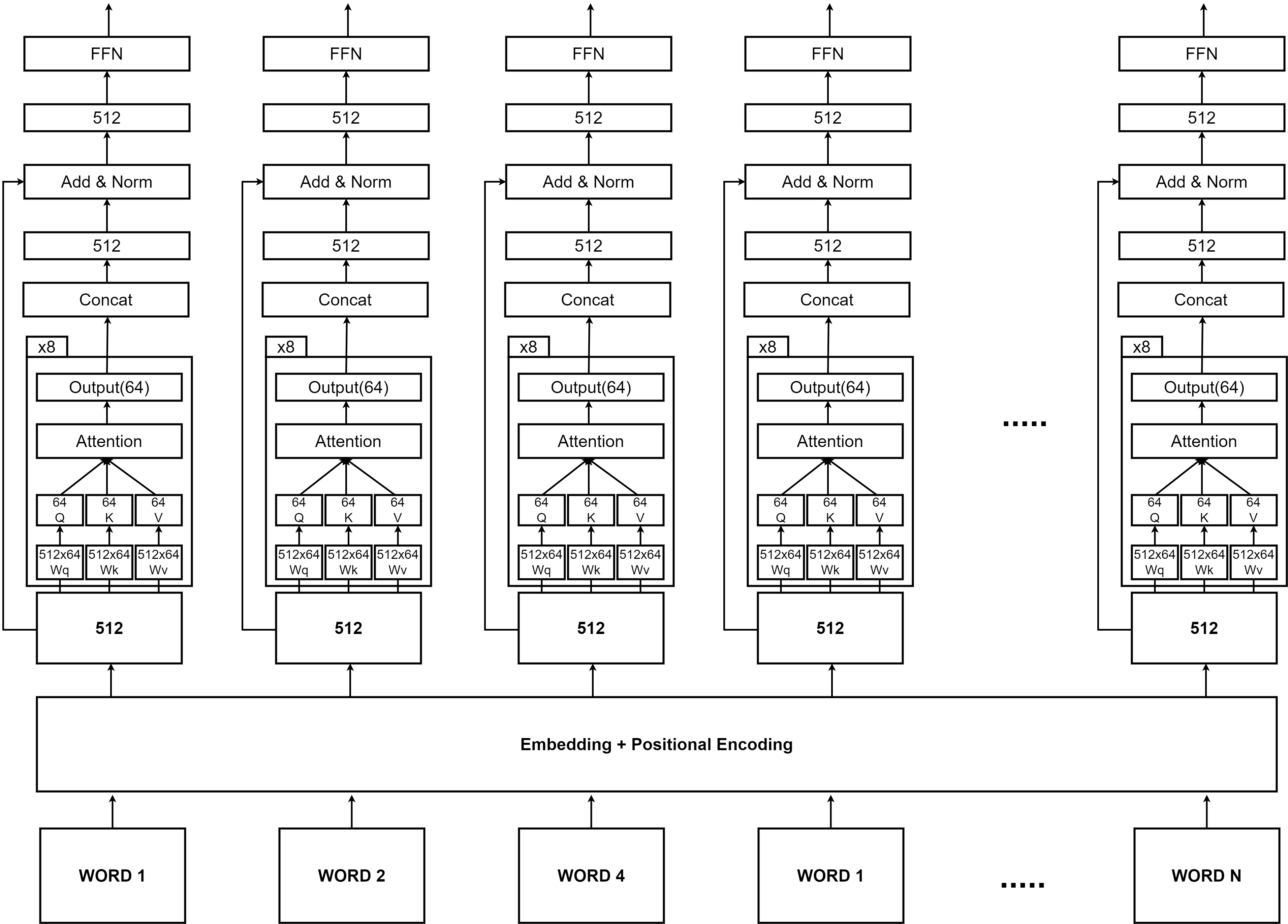
앞서 봤던 각 레이어의 구체적인 구조에따라 더욱 자세하게 그리면, Transformer encoder 하나는 다음과같은 구조로 되어있다는 것을 알 수 있다.
Transformer
이제 각 계층의 구체적인 구조는 모두 봤다. Transformer의 전체적인 구조를 보면, 사실 위의 그림대로의 Encoder를 하나만 쓰는 것이 아닌, Nx개의 Encoder를 이어붙인 구조로 되어있다. 그리고 가장 마지막 Encoder의 출력값만 디코더의 두번째 Multi-head Attention의 입력으로 받는다. 이때 Encoder의 출력값에 Key, Value 벡터를 Decoder의 입력으로 넣어준다. Decoder는 Masked Multi-head Attention을 먼저 수행한 뒤, Encoder의 출력값과 Decoder의 Masked Multi-head Attention에서의 출력 값을 이용해 한번더 Attention 연산을 진행한다. 이때 Masked Multi-head Attention은 말 그대로 특정 단어를 Making 한 Multi-head Attention이다. Encoder와 달리 Decoder에서의 Attention의 기능은, 단어와 단어사이의 관계가아닌, 다음 단어를 예측을 해주는 기능을 수행해야한다. 따라서, 만약 난 너를 사랑해를 I Love You로 번역해주는 경우, Decoder에서는 I Love You를 초기 입력 데이터로 받고, Multi-head Attention을 수행할 것이다. 이때 Love라는 단어를 입력으로 받을 때, Decoder는 다음 단어를 예측해줘야 하기 때문에, Love 앞쪽의 단어만을 고려해, 가중치 계산을 수행해야 한다. 따라서 Love와 You의 Attention Score 값을 -∞ 이라는 값으로 Masking 해주는 것이 Masked Multi-head Attention이다.
Attention Score를 -∞로 설정할 경우, Softmax함수를 적용한 Attention Weight은 거의 0에 수렴하게 될것이다. 이렇게되면, Attention을 이용해 단어의 연관성을 출력해줄때 해당 단어 앞쪽과의 단어들과의 연관성만을 계산하게 될 것이다.
