0. Abstract
Deep learning 기반의 model에게 long-tail distribution은 class imbalance 문제를 발생시킨다.
Loss re-weighting, data re-sampling, transfer learning과 같은 class-balancing strategies가 있지만 대부분은 representations, classifiers의 jointly learning을 고수하고 있다.
본 논문에서는 model의 학습을 representation learning과 classification 두 단계로 나누고 서로 다른 balancing strategies가 long-tailed recognition에 미치는 영향을 알아보려고 한다.
실험 결과, long-tailed benchmarks에서 SOTA의 성능을 보였다.
1. Introduction
ImageNet과 같이 open된 datasets는 일반적으로 artificially balanced된 datasets이다. 그러나 현실 세계의 데이터들은 long-tailed distribution을 일반적으로 따르며 기존의 접근 법은 model 성능의 하락을 가져온다.
Long-tailed distribution의 가장 큰 문제는 학습 시 head class data에 대해서는 model의 성능이 좋으나 tail class data에 대해서는 상대적으로 성능이 많이 떨어진다는 점이다.
이 문제를 해결하기 위해 data를 re-sample 하거나 loss를 새롭게 디자인하는 방법이 있었다. 다른 방향으로는 head class data로 학습 후 tailed class data로 transfer learning을 하는 방법이 있다.
하지만 앞 선 방법들은 classifier와 representation을 함께 학습하기 때문에 long-tailed recognition이 얼마나 해결되었는지 가늠하기가 어렵다. 그래서 본 논문에서는 long-tail recognition을 representation learning과 classification으로 나눴다.
구체적으로, 첫 번째로 서로 다른 sampling strategies로 representations를 학습하고 balanced decision boundaries를 얻는 세 개의 접근 법을 적용해 비교하였다.
실험 결과, 다음과 같은 흥미로운 결과를 얻었다.
-
Instance-balanced sampling은 가장 generalizable하고 좋은 representation을 학습한다.
-
Representation learning 이후에 decision boundaries를 재 조정함으로 long-tailed recognition의 의 성능을 높였다.
-
일반적인 network (e.g., ResNeXt)에 decoupled learning을 적용함으로 복잡한 기존 SOTA의 methods보다 좋은 성능을 얻었다.
2. Related Work
Long-tailed recognition은 real-world application의 imbalance data와 연관성이 있기 때문에 많은 주목을 받았다. 최근의 연구는 크게 세 가지의 방향을 추구하고 있다.
1) Data distribution re-balancing
Balanced data distribution을 얻기 위해 dataset을 re-sample하는 방법이다. 각각의 class의 sample 개수를 바탕으로 minority classes를 over-sampling하고 majority classes를 under-sampling한다.
2) Class-balanced Losses
각각의 class의 samples마다 다른 loss를 할당하는 방법들이 제안이 되었다. Class-level에서 data distribution을 맞추고 tail classes를 generalization을 향상을 시키는 loss가 제안이 되었다.
또한 좀 더 fine-graied한 control을 위해 sample-level에서 loss를 조정하는 Focal loss, Meta-Weight-Net, re-weighted training, Bayesian uncertainty와 같은 methods들이 제안이 되었다.
3) Transfer learning from head to tail classes
Transfer learning 기반의 methods는 head class data로 부터 학습한 model을 tail class data를 학습 시 transferring 함으로 data imbalance 문제를 해결한다.
3. Learning Representations for Long-tailed Recognition
Representation learning과 classifier learning을 분리하는 것이 long-tailed recognition에 미치는 영향을 확인하기 위해 체계적으로 조사하였다.
1) Notation
Training set:
Data point:
Label:
Class 에 속하는 training sample의 개수:
Training set의 총 개수:
가 입력일 때, parameter가 인 CNN model로 부터 얻은 representation:
2) Sampling strategies
Representation, classifier learning을 위해 data distribution을 balancing하는 여러 strategies를 소개한다.
Class 에서 data가 추출될 확률은 다음과 같이 표현된다.
는 class 개수이고 는 0, 1 사이의 값이며 strategies에 따라 결정된다.
- Instance-balanced sampling ()
가장 일반적인 sampling 방법으로 모두 동일한 확률로 sampling을 한다.
- Class balanced sampling ()
Imbalanced dataset에서 instance-balanced sampling은 최적의 방법이 아니며 few-shot classes에 대해 under-fit이 되는 문제가 있다. class balanced sampling은 각각의 class를 동일한 확률로 뽑아 이러한 문제를 해결한다. 이는 two stage sampling strategy로 볼 수도 있으며 첫 번째로 class를 uniform하게 선택하고 uniform하게 instance를 sampling한다고 볼 수 있다.
- Square-root sampling ()
위 두 strategies의 중간이 되는 strategy이며 일반적으로 많이 쓰인다.
-
Progressively-balanced sampling
처음은 instance-balanced sampling으로 시작했다가, 학습이 진행됨에 따라 class balanced sampling으로 점점 바뀌는 strategy이다.는 현재 epoch, 는 총 epochs이다.
3) Loss re-weighting strategies
최근에 발표된 높은 성능을 보여주는 접근 법을 보면 학습 난이도가 높고 dataset-specific한 hyper-parameter tuning의 문제가 있다. 본 논문에서는 고려하지 않는다.
4. Classification for Long-tailed Recognition
본 논문에서는 classification에서 representation을 분리하는 방법을 고려한다.
Classifier를 학습 시 다른 sampling strategy를 사용함으로 decision boundaries를 재 조정하거나 non-parametric 방법을 사용하는 경우를 소개한다.
1) Classifier Re-training (cRT)
Representation model은 fix하고, classifier weight , 를 random하게 re-initialize한 후 class-balanced sampling을 이용하여 적은 수의 epoch동안 classifier을 재 학습한다.
2) Nearest Class Mean classifier (NCM)
Representation model에서 얻은 각 class의 mean feature representation을 계산하고, 이를 이용해 nearest neighbor search를 한다. Distance metric은 cosine similarity나 Euclidean distance를 이용한다.
3) -normalized classifier (-normalized)
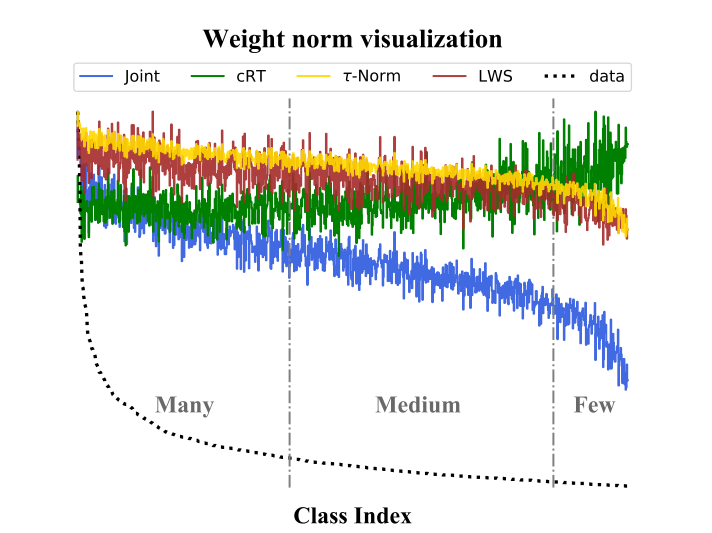
Instance-balanced sampling을 이용한 joint learning (representation learning+classifier learning) 이후, classifier의 각 weight의 norm 가 class에 속하는 sample의 수 와 연관성이 있음을 발견했다.
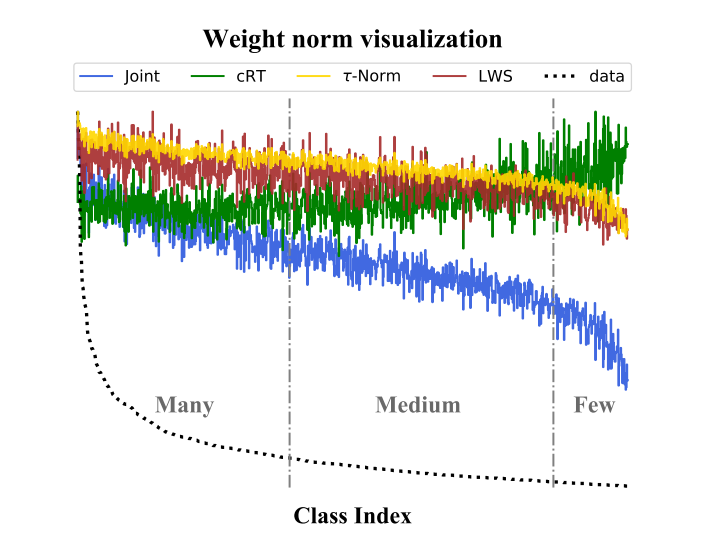
그리고 위 그림과 같이 class balanced sampling으로 classifier를 학습했을 때 (cRT), 각각의 class의 classifier weights의 norm이 서로 비슷해지는 것을 확인할 수 있다.
따라서, classifier re-training을 거치지 않고, 단순히 classifier wieghts의 norm 값들만 재 조정 해준다면 비슷한 효과를 얻을 수 있을 것이라는 발상이다.
Classifier weight norm을 다음과 같이 조정해 준다.
이때 은 "temperature"라는 이름의 hyperparameter이다.
이면 L2-normalization과 동일해지며, 이면 scaling을 하지 않는 것과 같다.
본 논문에서는 validation set을 이용해 를 탐색했다. 각 dataset 별로 사용된 값은 다음과 같다.
ImageNet-LT: 0.7
iNaturalist 2018: 0.3
Places-LT: 0.8
4) Learnable weights scaling (LWS)
-normalization은 각각의 class weight의 magnitude를 re-scaling해주는 과정이라고 볼 수도 있다.
이 때 를 learnable 한 parameter로 설정한다.
cRT와 마찬가지로, class-balanced sampling을 이용하여 만을 learnable parameter로 두고 re-training을 수행한다.
5. Experiments
1) Experimental setup
- Dataset
세 가지의 large-scale long-tailed datasets를 사용했으며 다음과 같다. Places-LT, ImageNet-LT, iNaturalist 2018
- Evaluation Protocol
Top-1 accuracy를 사용했으며, all classes, 100장 이상 image를 포함한 class (Many-shot), 20~100장의 image를 포함한 class (Medium-shot), 20장 이하의 image를 포함한 class (Few-shot)로 나눠서 결과를 출력했다.
- Implementation
PyTorch를 이용했으며, ResNet, ResNext 등을 backbone으로 사용했다. Representation learning stage에서는 90 epoch, cRT나 LWS 등 classifier의 학습이 필요한 경우에는 10 epoch동안 학습했다.
2) Sampling strategies and decoupled learning
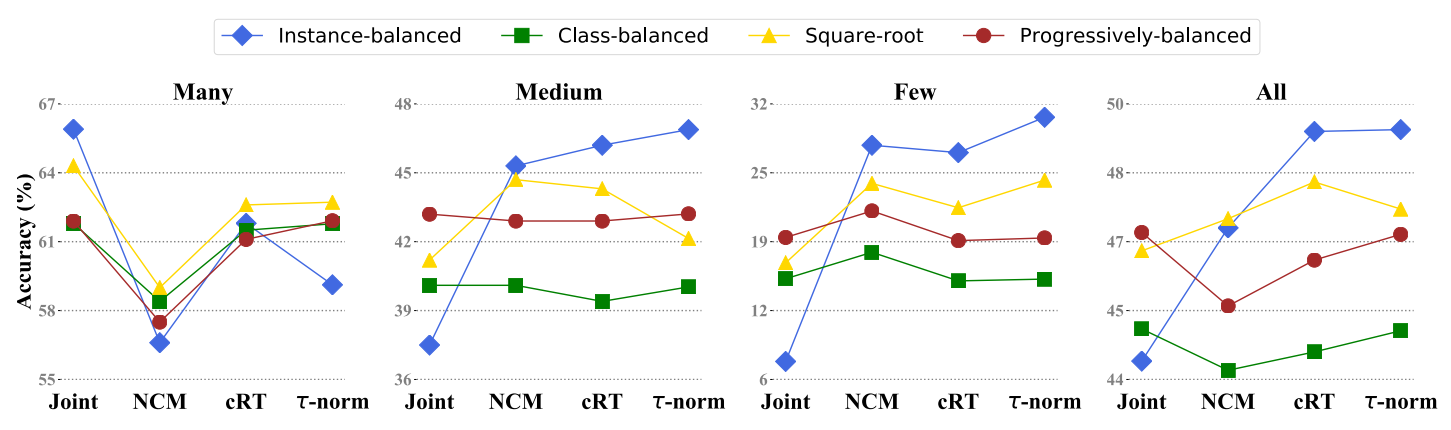
- Sampling matters when training jointly
Joint training의 경우, 더 나은 sampling strategy를 이용할수록 성능이 향상되었다. 이는 더 나은 sampling method를 제안하는 방향으로 연구되어 온 기존의 연구들과 일치한다.
-
Joint or decoupled learning?
Decoupled method를 사용하는 것이 항상 더 좋은 결과를 보였다.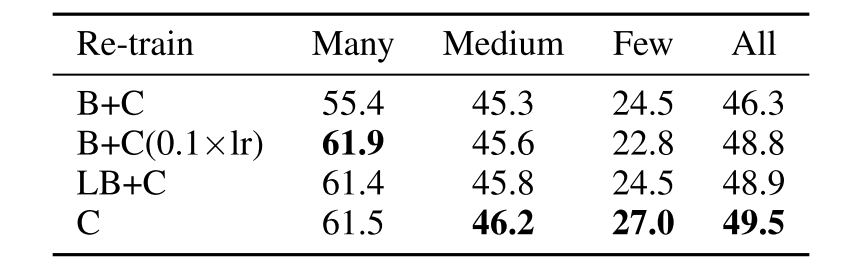
Representation과 classifier을 분리하는 방법의 타당성을 보다 증명하기 위해, network의 각 부분을 fine-tuning 하였다. 위 표를 보면 알 수 있듯이 전체 network를 fine-tuning하는 것이 가장 낮은 성능을 보였으며 representation을 freeze하는 것이 가장 좋은 결과를 보여준다.
- Instance-balanced sampling gives the most generalizable representations
놀랍게도, instance-balanced sampling을 이용해 representation을 학습한 경우가 classifier을 재 조정 이후 가장 좋은 성능을 보였다. 이는 data imbalance가 좋은 representation을 학습하는 데에 큰 영향을 미치지 않을 수도 있음을 의미한다.
3) How to balance your classifier?
Training 과정이나, data imbalance 해소를 위한 추가적인 sampling strategy의 사용을 필요로 하지 않는 NCM과 -normalized가 cRT와 비슷하거나 더 높은 성능을 보인다.
이는, 각 class의 decision boundary를 재 조정한다는 점에서 얻은 효과일 것으로 예상된다.
Joint classifier의 weight norm은 해당 class에 속하는 sample의 수와 연관이 있다.
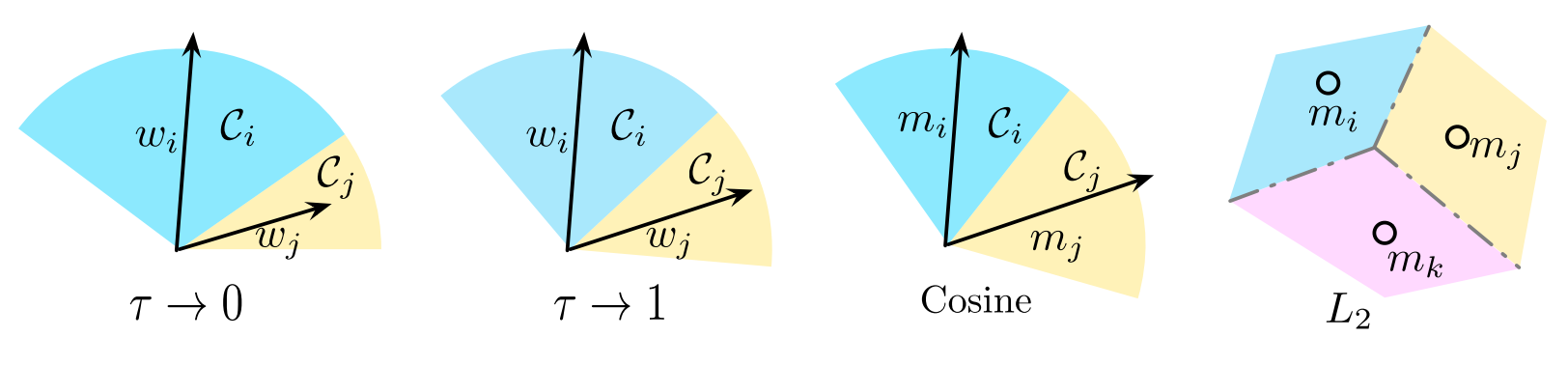
Weight norm이 크다는 것은, feature space에서 더 넓은 classification boundary를 가지고 있다는 것과 같다. 따라서 이 경우 더 많은 sample을 가진 class가 더 넓은 classification boundary를 갖고 더 높은 성능을 얻게 된다.
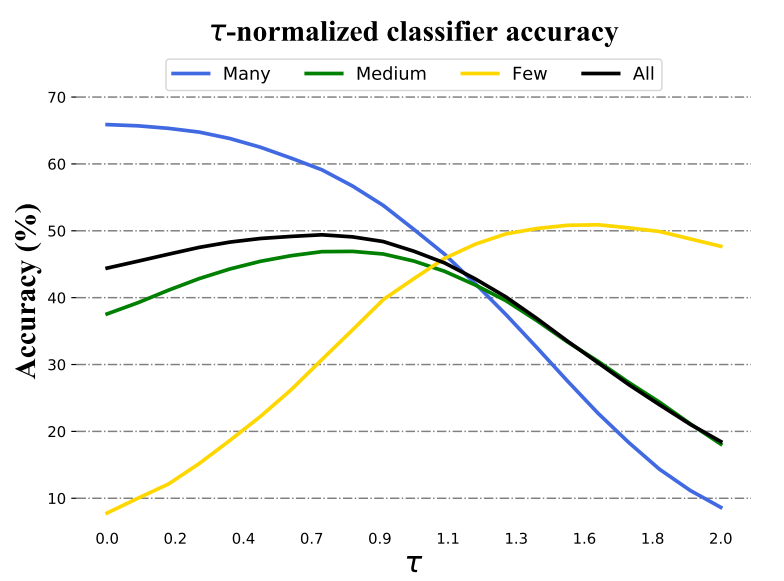
가 커질수록, many-shot accuracy가 감소했으며 few-shot accuracy가 증가하였다.
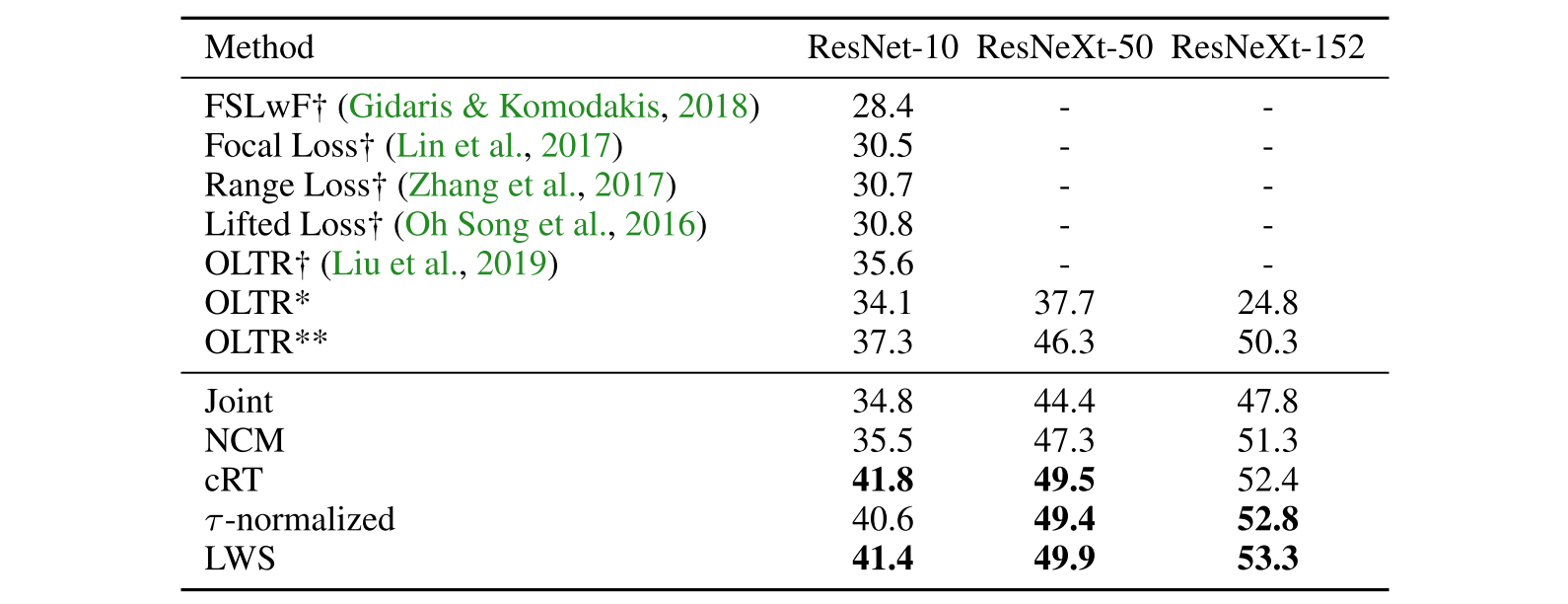
Dataset 중 대표로 ImageNet-LT를 선정했으며 다양한 SOTA method들과 비교한 결과이다.
Training이 필요하지 않는 NCM method 또한 대부분의 SOTA method들보다 더 높은 성능을 보이며, classifier weight을 re-balancing하는 -normalized, LWS는 그 방법이 매우 간단함에도 불구하고 모든 SOTA method들보다 더 높은 성능을 보인다.
6. Conclusion
본 논문은 long-tailed recognition을 위한 여러 strategies를 알아보고 jointly learning과 decoupled learning을 비교하였다.
Jointly learning에서는 sampling strategies가 중요하지만 instance-balanced sampling이 좀 더 generalizable한 representation을 주며 classifier를 re-balancing 함으로 SOTA에 준하는 성능을 가져다 줬다.
세 가지의 long-tailed benchmarks에서 SOTA의 성능을 얻었으며 long-tailed recognition task에 좀 더 깊은 이해와 추후 연구에 영감을 주었다고 생각한다.
