P-Tuning v2: Prompt Tuning Can Be Comparable to Fine-tuning Universally Across Scales and Tasks
Introduction
-
fine-tuning은 target task에 맞게 모델 전체를 업데이트하는 방법
-
fine-tuning은 gradient와 optimizer의 모든 파라미터를 저장해야 하고, 각각 task에 맞는 모델을 복제 및 저장하는 것은 매우 비효율적
-
Prompting은 사전학습된 모델을 freeze하고 자연어로 된 prompt를 모델의 query로 사용하는 방법
-
prompting은 전체 training을 요구하지 않고 오직 하나의 model만 저장하면 됨
-
하지만, discrete prompting은 fine-tuning과 비교하여 대부분의 상황에서 최적의 성능을 보여주지 못함
-
따라서, Prompt Tuning은 continuous prompt를 사용하는 아이디어
-
특히, P-Tuning v1, Prompt Tuning 연구에서는 학습가능한 continuous embeddings(also continuous prompts)을 원래의 input word embeddings에 추가하는 방법을 제안함
-
prompt tuning은 대부분의 task에서 prompting보다 더 나은 성능을 보여주었지만, 여전히 모델의 크기가 작을때(under 10B)에서는 fine-tuning보다 성능이 좋지 못함
-
본 논문의 주요 contribution은 적절히 최적화된 prompt tuning이 다양한 모델의 크기와 NLU task에 걸쳐 보편적으로 fine-tuning과 비교할 수 있다는 발견임
-
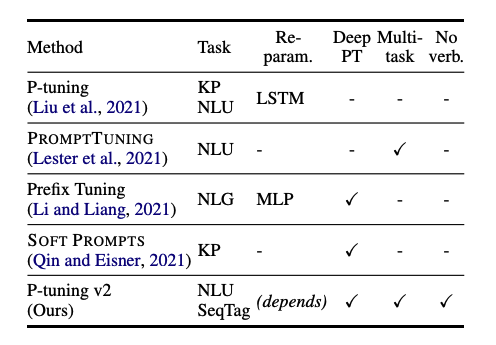
P-tuning v2는 개념적으로는 새로운 것이 아니고 Deep Prompt Tuning(Li and Liang, 2021; Qin and Eisner, 2021)을 최적화 및 적응을 한 것으로 볼 수 있음
-
가장 중요한 개선사항은 단순한 input layer 대신에, 사전 학습된 모델의 모든 layer에 continuous prompts를 적용하는 점
-
P-tuning v2는 다양한 크기의 모델들과 extractive question answering, named entity recognition과 같은 hard sequence tagging tasks에서 fine-tuning과 비교할만 하다.
Preliminaries
NLU Tasks
-
NLU tasks를 simple classification과 hard sequence labeling tasks로 나눌 수 있음
-
simple classification은 label space에 대한 분류가 포함되며 GLUE, SuperGLUE가 여기에 포함됨
-
hard sequence labeling은 named entity recognition과 extractive question answering과 같이 sequence of tokens에 대한 분류를 의미함
Prompt Tuning
-
를 vocabulary, 을 언어 모델, 를 임베딩 레이어라고 할때, discrete prompting(classify a movie review)은 로 사용할 수 있고, input 일때, 로 표현할 수 있음
-
continuous prompts는 학습가능한 continuous embeddings()이 주어지면, 로 나타낼 수 있음.
P-Tuning v2
Lack of Universality
Lack of universality across scales
- prompt tuning은 10B 이상의 모델 크기에서는 fine-tuning과 비슷한 성능을 보이지만 가장 많이 사용되는 중간크기(100M to 1B)에서는 성능이 좋지 못함.
Lack of universality across tasks
- P-tuning, Prompt tuning은 몇몇의 NLU benchmarks에서 우세한 성능을 보여주었지만, hard sequence tagging tasks에서는 검증이 되지 않음
Deep Prompt Tuning
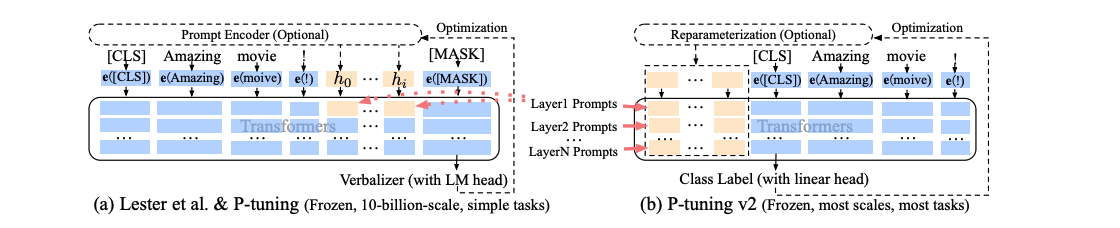
-
기존의 prompt tuning은 input embedding sequence에 continuous prompt를 삽입하는 방식
-
이 방식은 2가지 문제점이 있음
-
sequence length의 제약으로 학습가능한 파라미터의 수가 제한됨
-
input embeddings은 모델 예측에 대하여 비교적 간접적인 영향을 줌
-
-
P-tuning v2는 Deep Prompt Tuning의 아이디어를 채택하여 이 문제를 해결하려고 함
-
위의 그림에 따라, 다른 layer에 prompt를 prefix-token으로 추가함
-
이로 인해, P-tuning v2는 tunable한 파라미터들이 더 많아 효율이 좋은 task당 용량을 더 많이 허용할 수 있음
-
반면, deeper layers에 추가된 prompt는 모델 예측에 더욱 직접적인 영향을 끼침
Optimization and Implementation
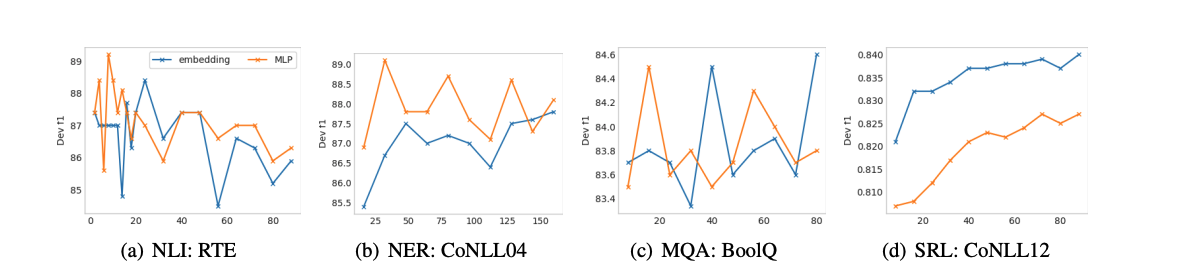
Reparametrization
-
이전 연구에서는 보통 MLP를 사용하여 reparametrization을 함
-
하지만 NLU에서는 특정 dataset에 따라 유용성이 다르다는 것을 확인함
-
RTE, CoNLL04과 같은 데이터에서는 MLP가 좋은 성능 향상을 보이지만, BoolQ, CoNLL12에서는 악영향을 끼침
Prompt Length
-
적절한 prompt Length는 다른 NLU task마다 다르다는 것을 확인할 수 있음
-
일반적으로, 간단한 분류에서는 짧은 prompt(less than 20)가 좋으며 hard sequence labeling에서는 긴 것(around 100)이 좋음
Multi-task Learning
-
task에 대한 fine-tuning 전에 공유된 continuous prompt로 multiple task를 최적화함
-
Multi-task는 P-tuning에서는 선택 사항이지만, 더 나은 초기화를 제공하여 성능 향상을 할 수 있음
Classification Head
- verbalizers를 예측하기 위해 언어 모델 head를 사용하는 것은 prompt tuning에서 중요했지만, 전체 데이터에서는 필요하지 않고 sequence labeling에서는 호환되지 않는 것을 발견함
Experiments
-
모든 실험은 frozen language model backbones에서 수행됨
-
few-shot 설정이 아닌 fully-supervised setting에서 수행됨
-
NLU ablity를 테스트하기 위해 SuperGLUE와 named entity recognition, extractive question answering, semantic role labeling을 도입함
-
모델은 BERT-large, RoBERTa-large, DeBERTa-xlarge, GLM-xlarge/xxlarge를 사용하며 300M to 10B까지의 크기를 비교함
-
Multitask Learning의 경우 각각의 task의 학습 데이터를 결합하고 continuous prompt를 공유하면서 각각의 데이터에 대해 별도의 linear classifiers를 사용함
P-tuning v2: Across Scales
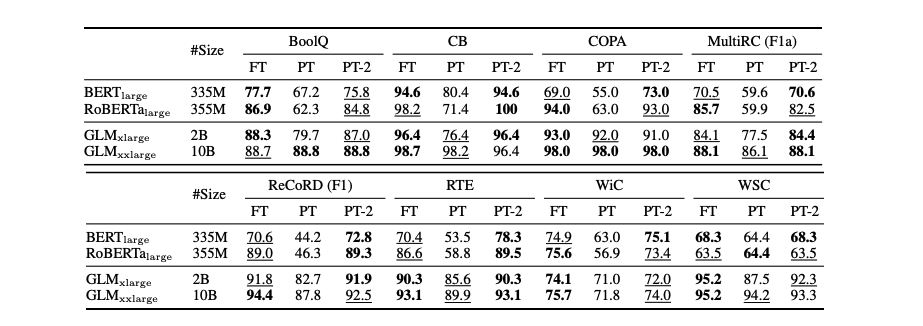
-
SuperGLUE에서 Prompt-tuning과 P-tuning은 작은 크기의 모델에서 성능이 좋지 않음
-
반면에, P-tuning v2는 작은 크기의 모델에서도 fine-tuning과 비슷하거나 심지어 더 좋은 성능을 보여줌.
P-tuning v2: Across Tasks
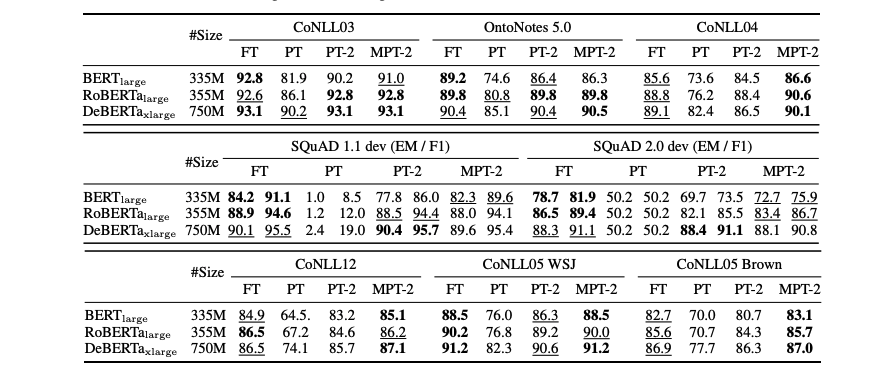
-
P-tuning v2는 전반적인 모든 tasks에서 fine-tuning과 동등한 성능을 보여줌
-
Multi-task learning에서, P-tuning v2가 QA를 제외한 모든 task에서 성능 향상을 보여줌
Ablation Study
Verbalizer with LM head v.s. [CLS] label with linear head
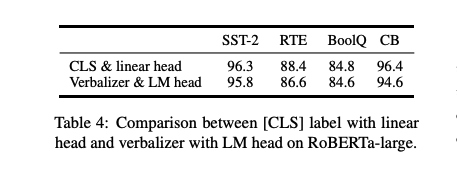
-
LM head를 사용하는 verbalizer는 prompt tuning 접근법 이전의 중심 요소였음
-
supervised setting에서 P-tuning v2은 약 수천 개의 파라미터에 대한 linear head를 튜닝하는 것이 적절함
-
위의 표와 같이, verbalizer와 [CLS] 사이의 큰 차이는 없음.
Prompt depth
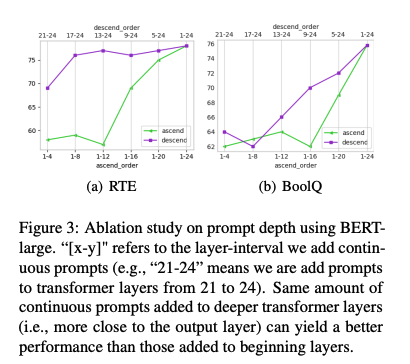
-
P-tuning, Prompt-tuning과 달리, P-tuning v2는 multi-layer continuous prompts임
-
영향력을 알아보기 위해 prompt를 추가하기 위한 개의 layer에서 오름차순, 내림차순으로 prompt를 추가하고 나머지는 그대로 둠
-
위의 그림과 같이, 같은 수의 파라미터에 대하여 내림차순으로 prompt를 추가할 때 오름차순보다 항상 나은 성능을 보여줌
-
RTE의 경우, 17-24 layer에 추가할 시 모든 계층에 추가한 것과 비슷한 성능을 보임
Conclusions
- scales 과 tasks 전반에 걸쳐 fine-tuning과 비교할만한 P-tuning v2를 소개함
