Background
-
embedding : data를 underlying semantics을 가지는 latent space로 처리하는 것
-
dense retrieval : query에 대하여 관련있는 answer를 embedding similarity로 추출하는 것
-
multi-vector retrieval : query와 document를 여러 개의 embeddings를 사용한 score를 기반으로 계산 하여 추출하는 것
-
sparse or lexical retrieval : 각 term들의 importance로 계산 하여 추출하는 것
Problem state
-
embedding 모델은 NLP에서 광범위하게 사용되지만 versatility(다용도성)이 떨어짐.
-
대부분의 embedding 모델들은 영어에 적합함
-
대부분의 embedding 모델들은 하나의 retrieval functionality에 대하여 학습함
-
대부분의 embedding 모델들은 short input만 지원함
contribution
-
100개 이상의 언어 지원
-
dense retrieval, sparse retrieval multi-vector retrieval의 retrieval functionalities를 지원하기 위해 다양한 embedding 생성 가능
-
짧은 문장부터 8192토큰의 긴 문서를 다룰 수 있음
-
다양한 retrieval functionalities를 연결하여 학습하고 서로 간의 강화를 시켜줄 수 있는 새로운 self-knowledge distillation 제안
-
batching strategy를 최적화 하여 큰 batch size와 높은 training throughput 달성
-
고품질의 데이터를 사용함
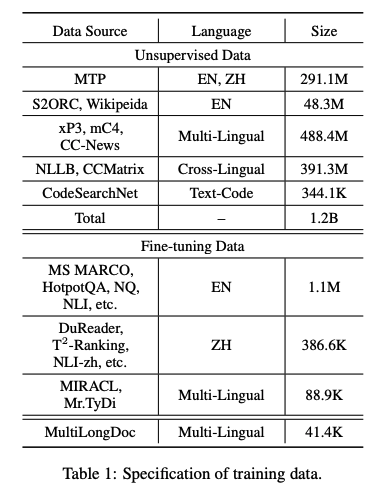
- massive multi-lingual corpora로 부터 unsupervised data 추출
- labeled corpora로 부터 fine-tuning data 통합
- 부족한 training data 합성
- 긴 글에서 무작위로 paragraph를 선택하고 GPT-3.5를 사용해 paragraph에 기반한 questions 생성
Method
- M3-Embedding은 임의의 언어 x로 쿼리 q가 주어지면 언어 y로 문서를 검색할 수 있음.
- 여기서 fn은 dense, sparse/lexical, multi-vector retrieval을 의미
- y는 x와 같거나 다른 언어가 될 수 있음
Hybrid Retrieval
-
해당 논문에서는 3개의 retrieval functionalities를 통합함
-
Dense retrieval : normalize한 CLS 토큰을 사용하며, inner product를 통해 relevance score 측정
- Lexical retrieval : 각 term(token)의 weight을 사용함
- 는 hidden state를 float number에 매핑시킴
- 만약 term(token)이 query안에 많이 있다면, 그 중 가장 큰 weight만 남겨둠
- passage도 이와 같이 계산함
- relevance score는 joint importance of the co-existed term()로 계산
- Multi-Vector retrieval : dense retrieval의 확장으로 전체 output embedding을 사용
- 은 learnable projection matrix
- late-interaction으로 계산함 (ColBERT에서 계산하는 방식)
-
final retrieval result
Self-Knowledge Distillation
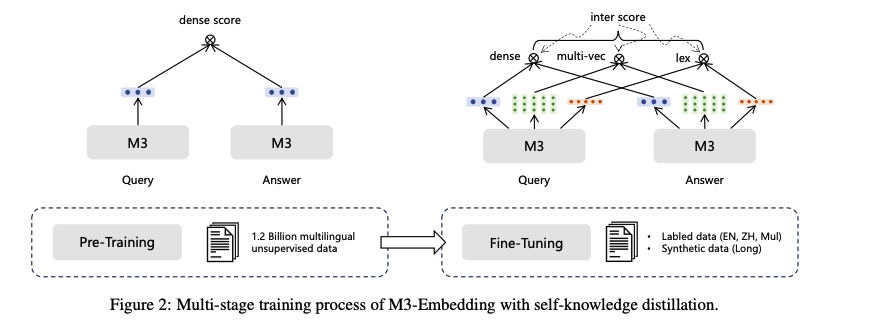
-
embedding 모델은 positive samples과 negative sample을 구분하도록 학습
-
InfoNCE loss를 minimize 하도록 학습
- 는 query에 대한 positive와 negative samples
- 은 을 의미
-
각각의 retrieval methods의 training objectives는 서로 충돌을 일의켜 embedding의 질을 떨어뜨릴 수 있음
-
본 논문에서는 ensemble leaerning에 기반한 self-knowledge distillation을 제안함
-
각각의 prediction score를 sum-up하여 통합
-
이렇게 얻은 score를 teacher로 사용
- 은 softmax activation
- 는
- loss function을 통합하고 정규화하면 아래와 같음
- self-knowlefge distillation의 final loss
- 학습은 XLM-RoBERTa 모델을 사용
- 첫번째 학습은 unsupervised data를 이용하여 오직 dense retrieval 사용하여 contrastive learning 수행
- 두번째 단계에서 self-knowledge distillation이 적용되고, labeled와 synthetic data를 이용하여 학습
Efficient Batching
-
in-batch negative를 사용하기 때문에 가능한 큰 batch-size가 유리함
-
전처리 단계에서 sequence length를 기준으로 그룹화하여 학습시 비슷한 길이로 batch를 구성
-
random seed 고정
-
long-sequence를 다룰 때 mini-batch를 sub-batch로 나눔
-
gradient checkpointing 사용
Results
- multi-lingual retrieval, cross-lingual retrieval, long-doc retrieval에 대하여 평가
Multi-lingual retrieval on the MIRACL dev set

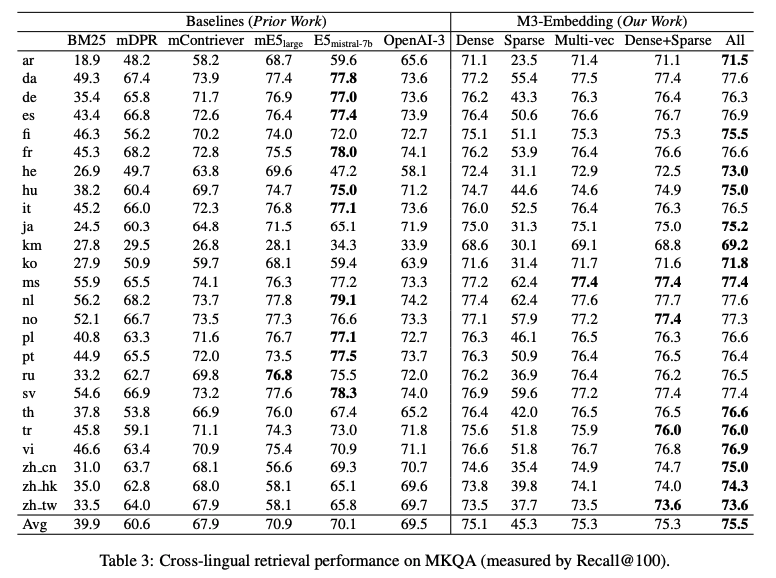
Cross-lingual retrieval on MKQA
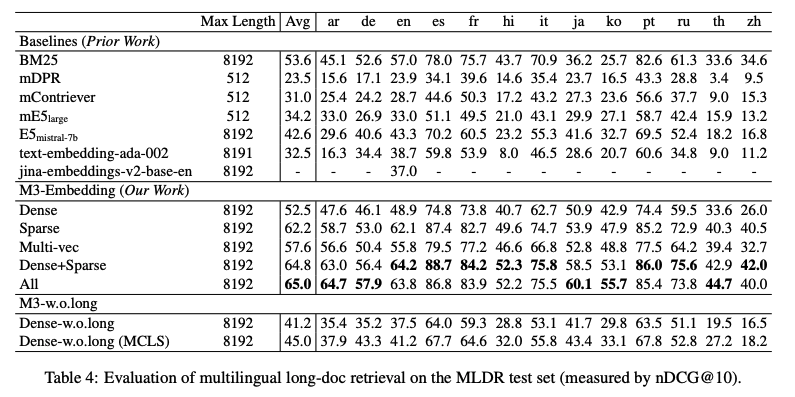
Multilingual long-doc retrieval on the MLDR test set
Conclusion
-
다양한 언어들을 커버할 수 있는 embedding 모델 제안
-
self-knowledge distillation을 통한 성능 향상
-
효과적인 batching strategy를 제안
