논문 : LLM2Vec: Large Language Models Are Secretly Powerful Text Encoders
Background
-
자연어처리 모델은 크게 bidirectional encoders, encoder-decoders, decoder-only로 구성됨
-
과거에는 BERT, T5와 같은 encoder, encoder-decoder 모델들이 우위를 점했지만, 최근에 들어서 decoder로만 구성된 LLM들이 강세를 보임
Problem state
-
decoder-only LLM들이 embedding task에 사용이 더딘 이유는 causal attention mechanism 때문임
-
causal attention limit은 현재 위치에서 그 이전의 표현만 영향을 받는 것
Contribution
- 3가지의 간단한 step을 통해 decoder-only LLM을 효과적인 encoder로 사용할 수 있는 방법 제시
Method
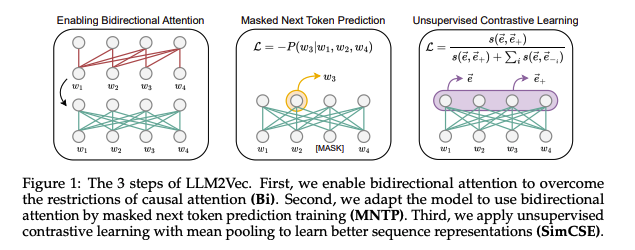
Enabling bidirectional attention (Bi)
-
decoder의 causal attention mask를 bidirectional attention으로 대체
-
decoder-LLM들은 bidirectional하게 학습하지 않았으므로 성능이 저하될 수 있음
Masked next token prediction (MNTP)
-
따라서, MNTP step을 통해 모델이 bidirectional attention을 인지할 수 있도록 함
-
MNTP는 maked language modeling을 한 next token prediction로 새로운 training objective
-
주어진 sequence에서 일정 비율로 making 하고 과거 뿐만 아니라 미래의 정보를 기반으로 masked token을 예측하는 task
-
마스킹된 토큰을 예측할 때, 마스킹된 위치(i)의 logit으로 예측하는 것이 아니라 이전 토큰(i-1)의 logit으로 예측
Unsupervised contrastive learning (SimCSE)
-
이전 단계를 통해 decoder LLM을 word-level task를 통해 encoder로 변환하였지만, sequence 표현에는 아직 부족할 수 있음
-
NSP를 포함하여 학습시키는 BERT와 달리, decoder-only LLM은 context에 대한 capture의 학습이 명확하지 않음
-
이런 차이를 줄이기 위해, contrastive learning의 SimCSE 방식을 도입함.
-
SimCSE 방식은 간단하게 입력 문장을 2번 흘려보내서(dropout mask) positive pair로 사용하고 batch내의 다른 문장들을 negative pair로 묶어 contrastive learning을 하는 방식
LLM2Vec은 위의 Bi + MNTP + SimCSE로 구성됨
-
본 논문에서는 1.3B to 7B의 LLM으로 English Wikipedia로 MNTP와 SimCSE를 수행함
-
English Wikipedia는 모든 모델에서 pre-training 데이터로 사용하기 때문에 고름
-
따라서, 모델에게 새로운 지식을 가르쳐 주는 아님
-
모델들에게는 마스킹을 위한 특별한 토큰이 없기 때문에 underscore(_)로 마스킹함
-
LoRA를 사용하여 fine-tuning 진행
-
MNTP의 LoRA weight를 base model에 merge하고 SimCSE를 학습하기 전 새로운 LoRA를 초기화 함
-
Contrastive training은 SimCSE의 unsupervised와 같음
Results
Evaluation on word-level tasks
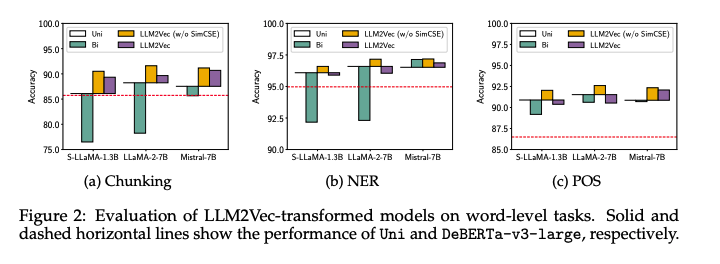
-
실선은 causal attention(Uni), 점섬은 DeBERTa-v3-large를 나타냄
-
이미 causal attention이 encoder-only 모델을 능가함
- 더 큰 파라미터
- 더 많은 데이터로 학습
-
naive하게 bidirectional attention을 적용하는 것은 성능 저하를 일으킴
-
MNTP를 적용한 경우 성능 향상을 보여줌
-
SimCSE까지 적용한 경우 기대와 달리 성능이 떨어짐
- SimCSE는 sequence-level task이기 때문으로 보여짐
Evaluation on sequence-level tasks
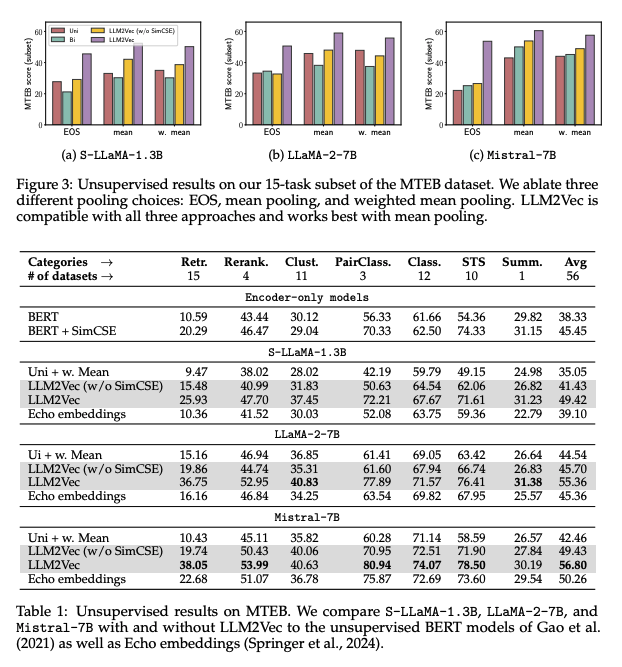
-
MTEB에 대하여 평기 진행
-
decoder-only LLM 모델들 뿐만 아니라 BERT와 SimCSE까지 성능 비교
-
Figure3은 가장 좋은 성능의 pooling 방법을 찾기 위한 실험 진행
- mean pooling 방식이 가장 좋은 성능을 보여줌
Combining LLM2Vec with supervised contrastive learning
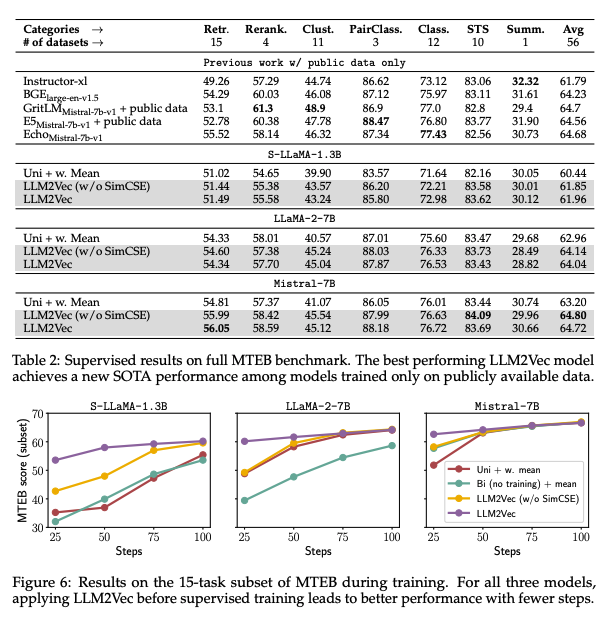
-
supervised LLM2Vec이 새로운 SOTA를 달성
-
LLM2Vec은 초기에 더 나은 성능을 달성
Conclusion
-
decoder-only LLM을 text embedder로 전환하는 방법을 제시
-
word-level부터 sequence-level까지 지원하기 위한 학습 방법 제시
-
LLM2Vec의 성능에 대한 분석을 자세하게 설명
