논문 : SimCSE: Simple Contrastive Learning of Sentence Embeddings
Background
-
unsupervised : labeled 데이터 없이 학습하는 방법
-
supervised : labeled 데이터로 학습하는 방법
-
dropout : 학습 시, overfitting을 방지하기 위해 특정 비율에 따라 뉴런의 출력값을 0으로 바꾸는 기법
-
contrastive learning : 비슷한 의미를 가진 representation은 가깝고, 다른 의미를 가진 representation을 멀게 학습하는 방법. 아래 식의 N은 batch 크기로 in-batch negative 사용
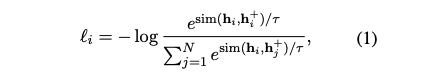
- alignment, uniformity : representation의 quality를 측정하기 위한 지표

Contribution
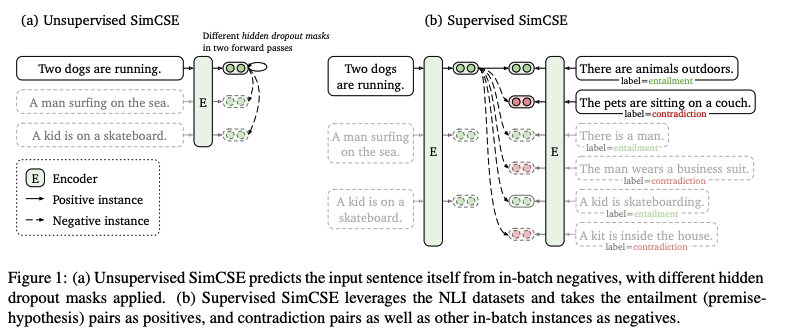
-
이미지 쪽에서는 positive pair를 구성할 때 cropping, flipping, rotation 등을 활용할 수 있다. 자연어 쪽에서도 이와 유사하게 deletion, reordering, substitution 등의 기법을 이용할 수 있다.
-
하지만 자연어는 discrete하기 때문에 위와 같은 방법을 적용하기에는 무리가 있으며, 본 논문에서는 dropout이라는 간단한 방법을 적용하여 효과적인 pair를 구성한다.
Method
Unsupervised SimCSE
-
Transformer model에는 기본적으로 fully-connected layer와 attention probabilites에 dropout(0.1)이 적용되어 있다.
-
입력 를 model에 2번 적용하여 positive pair인 를 얻는다.
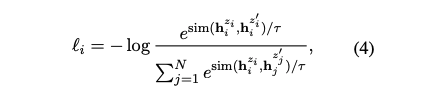
- training objective는 위의 식처럼 표현할 수 있으며, 여기서 N은 batch size 이며 는 cosine similarity 이다.
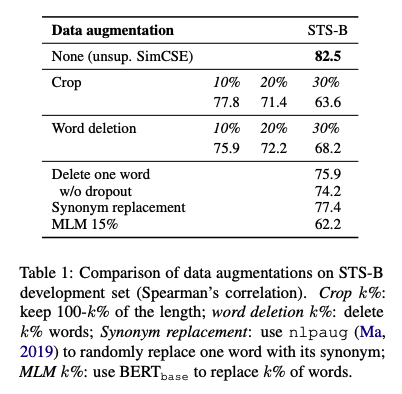
- dropout은 기존의 delete, replace 등의 augmentation들 보다 더 좋은 성능을 보여준다.
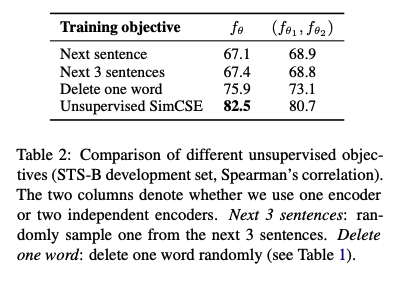
- SimCSE objective는 이전의 objective들 보다 뛰어난 성능을 보여준다.
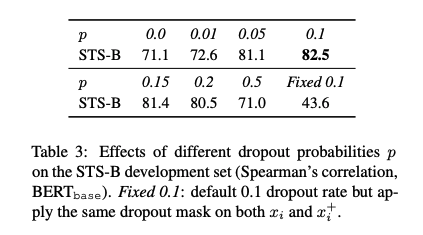
- dropout의 비율에 대한 실험에서 Transformer의 default(0.1)이 가장 성능이 좋은 것을 확인할 수 있다.
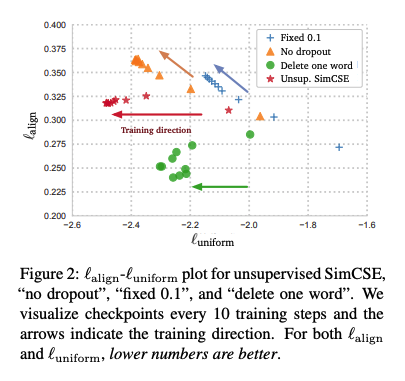
- 다양한 augmentation들의 align와 uniform를 비교해 본 결과, SimCSE 방법이 일반적으로 좋은 성능을 보여줬으며 Delete one word의 경우 align은 좋지만 uniform이 좋지 않는 것을 확인할 수 있다.
Supervised SimCSE
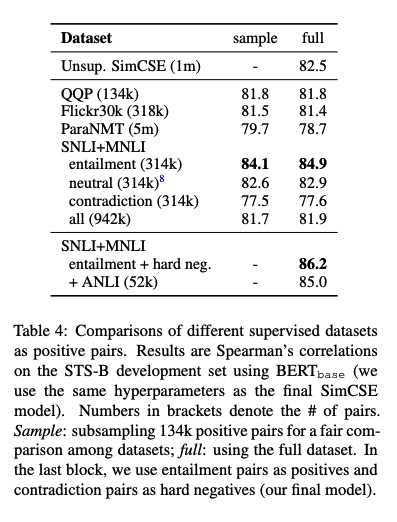
- NLI 데이터셋을 기반으로 entailment는 positive로 사용하고 contradiction은 hard negative로 사용한다.
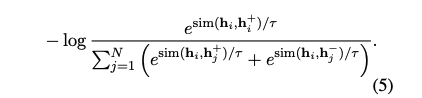
- 기존의 를 로 확장하며 위의 training objective를 적용한다.
Connection to Anisotropy
-
anisotropy는 embedding space가 고르게 분포하지 못하는 특성을 말한다.
-
input/output이 묶여 학습된 언어 모델은 anisotropic word embedding을 이끈다.
-
이러한 문제를 완화하기 위한 간단한 방법은 post-processing(dominant prinipal components 제거, isotropic 분포로 매핑)이나 학습 중 regularization을 적용하는 방법이 있다.
-
anisotropy문제는 uniformity와 관련이 있으며 embedding들이 공간에 골고루 분포되어야 하는 것을 의미한다.
-
따라서, contrastive learning은 negative는 멀리 분포하게 하므로 uniformity를 향상시킬 수 있다.
Results
- 사전학습 된 BERT, RoBERTa로 실험을 진행하고 CLS 토큰 임베딩을 문장 임베딩으로 사용한다.
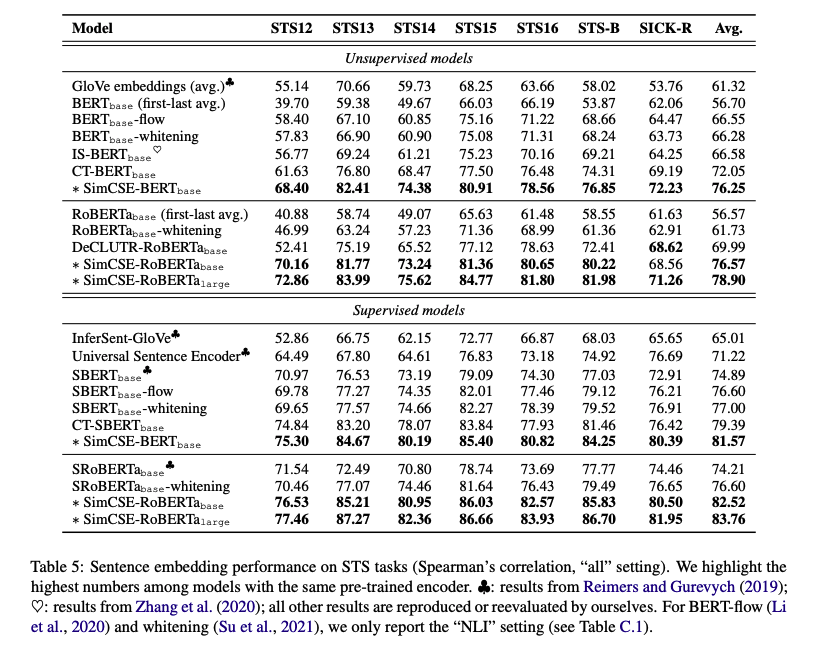
- 다양한 Embedding 모델들 중 SimCSE 모델이 주로 좋은 성능을 보여주고 있으며, 특히 supervised model은 상당히 높은 성능을 보여준다.
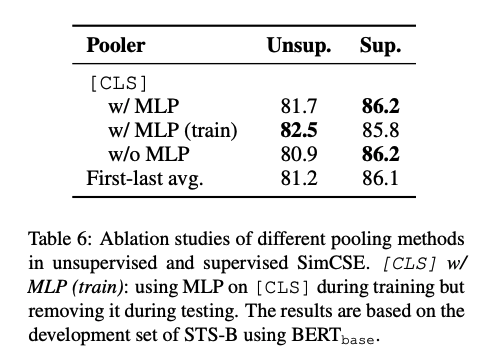
- 각각의 pooling 방법에 대한 성능 분석을 시도 했으며, unsupervised에서는 MLP(train)이 가장 성능이 좋았으며 supervised에서는 MLP를 사용한다.
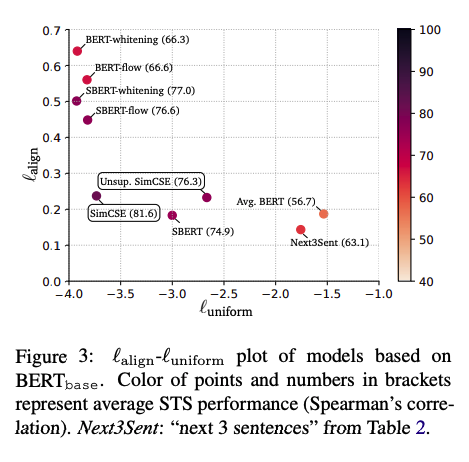
- align과 uniform 지표 측면에서 SimCSE가 가장 안정적인 수치를 보여준다.
Conclusion
-
SimCSE는 Dropout이라는 간단한 기법을 통해 unsupervised 방식을 소개했다.
-
supervised 방식에서는 NLI 데이터셋을 이용하여 기존의 contrastive learning을 적용한 모델들 보다 더욱 좋은 성능을 보여 주었다.
