논문 : Towards General Text Embeddings with Multi-stage Contrastive Learning
Background
- contrastive learning : 공간 상에서 비슷한 데이터는 가깝게 위치하고 그렇지 않은 데이터는 멀게 학습시키는 방법
Problem state
-
기존의 embedding 모델들은 특정 task에서만 성능을 보여줌
-
pre-training에 사용되는 데이터에 대해 의존하는 경향을 보임
Contribution
-
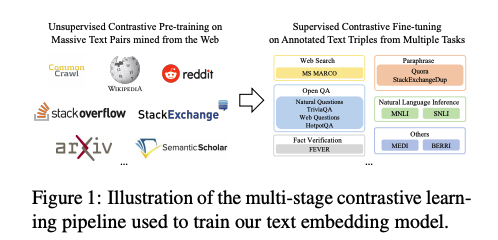
open data를 사용하여 contrastive learning 기법으로 general text embedding model을 제안
-
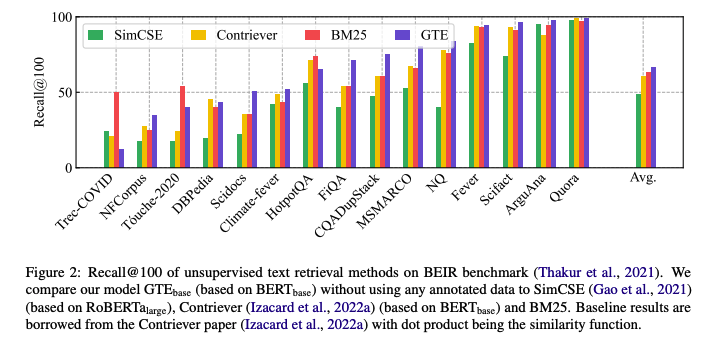
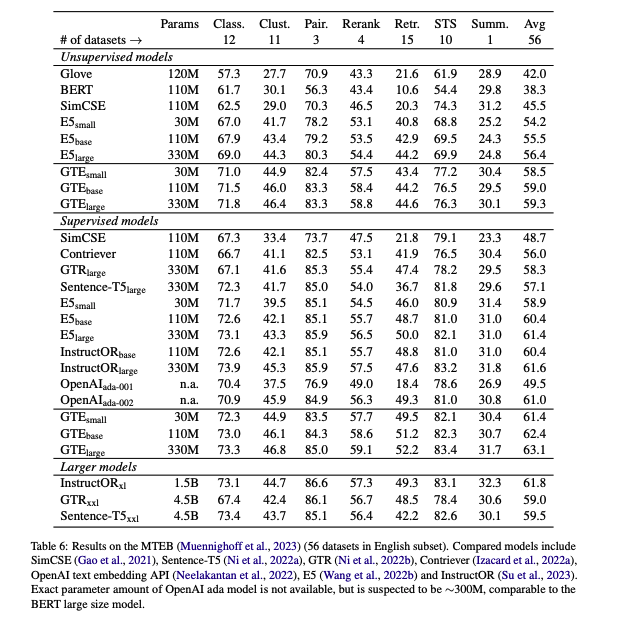
contrastive learning을 적용한 GTE 모델은 zero-shot text retrieval task와 MTEB benchmark에서 기존의 모델(BM25, E5, etc)들을 능가하는 성능을 보여줌
-
더 좋은 성능을 내기 위해, human labels text pair 데이터를 사용함
-
multi-stage training approach를 사용함 (unsupervised pre-training -> supervised fine-tuning)
-
이런 데이터를 바탕으로 학습한 모델은 fine-tuning 없이도 기존 fine-tuning모델의 성능을 넘음
Method
-
GTE 모델은 unsupervised와 supervised 2단계로 학습되며, 각 단계마다 contrastive learning을 사용함
-
backbone 모델로 BERT와 같은 Pre-trained encoder를 사용하며, mean pooling을 적용한 vanilla dual-encoder 구조를 따름
- 입력(x)에 대하여 와 같이 임베딩(E) 모델을 구현하기 위하여 위와 같은 language modeling을 함
-
(q, d+, d-)형태로 데이터를 준비하고 위와 같은 InfoNCE loss를 적용, 여기서 s(q, d)는 E(q)와 E(d)사이의 similarity를 의미함
-
unsupervised data는 다양한 open-source로 부터 수집하며, supervised data는 human annotation데이터와 symmetric/asymmentric task에 관련된 데이터를 사용
- unsupervised pre-training시, data imbalance를 해결하기 위해 다른 데이터 소스에서 샘플링된 데이터에 multinomial distribution을 적용함
Improved contrastive loss
- contrastive objective를 사용할 경우, 보통 in-batch negative를 적용하지만, 해당 논문에서는 bidirectional이며 in-batched query and document로 negative sample을 확대함
- 처음 2가지 term은 query와 document를 비교하기 위함이고, 나머지 항들은 반대로 비교하기 위함
Results
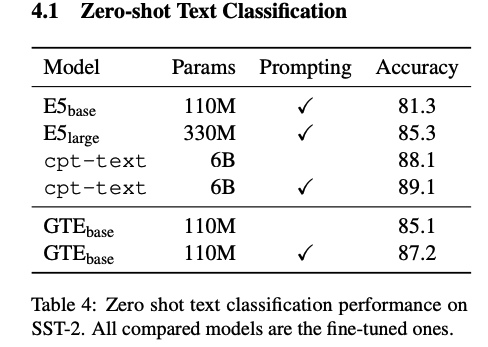
Zero-shot Text Classification
Unsupervised Text Retrieval
Massive Text Embedding Benchmark
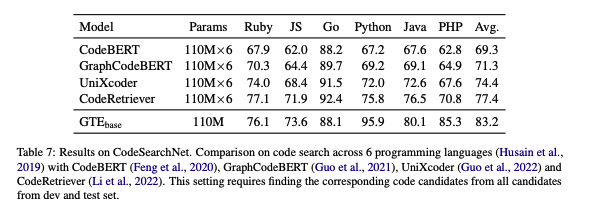
Code Search
Conclusion
-
향상된 Contrastive learning과 multi-stage 방식을 적용하여 general한 embedding 모델을 만들 수 있었음
-
해당 방식을 적용하기 위해 적절한 length와 batch size(for in-batch negative sampling) 등을 고려해야 함
