논문 : POSE: EFFICIENT CONTEXT WINDOW EXTENSION OF
LLMS VIA POSITIONAL SKIP-WISE TRAINING
Background
-
Meta에서 발표한 LLaMA-3는 8k로 context window size를 정의하고 있지만 다양한 hub에서 64k까지 확장한 모델들을 공유하고 있음
-
8k 모델을 64k까지 확장하기 위해 fine-tuning이나 다양한 기법들이 존재하며 그 중 PoSE 방법을 가장 많이 사용하고 있는 것으로 보임
Problem state
-
대부분의 시나리오에서는 긴 입력이 요구되지만 LLM은 pre-defined context window size에 따라 제한 되기 때문에 해당 size 이상의 입력에서는 성능 저하가 일어남
-
window size를 확장하기 위해 fine-tuning을 진행하는 것은 새로운 position indices에 의해 제대로 성공하지 못함
-
기존의 window size를 확장하기 위한 방법들은 Full-length fine-tuning에 의존하기 때문에 매우 많은 비용이 소모됨
Contribution

-
고정된 context window에서 position indices를 조정하는 것으로 long inputs를 simulate하는 것이 주요 아이디어
-
메모리와 시간 효율성을 높임 : original context size만으로 PoSE를 적용하기 때문에 계산 복잡도를 피할 수 있음
-
매우 긴 context에 대해 확장할 수 있는 방법론 제기 : 기존 LLM의 능력을 유지하며 성공적으로 LLaMA 2k -> 128k까지 확장
-
RoPE 기반 LLM과 position interpolation 방법론에 대하여 호환 가능
-
PoSE는 inference시 memory 사용량의 제약을 제외하면, 이론적으로 무한히 context window size를 확장시킬 수 있음
Method
Rotary Position Embedding (RoPE)
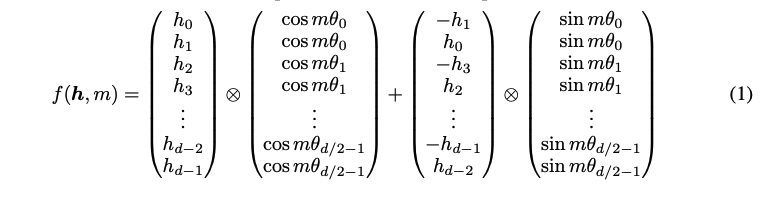
-
RoPE는 현재 많은 LLM에서 사용되는 기법
-
rotation matrix로 토큰들의 position 정보를 인코딩함
-
이전 absolute position encodings과 달리 입력 벡터 x에 직접 적용
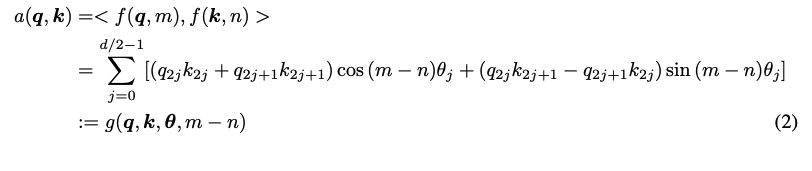
-
RoPE는 각 layer의 query와 key 벡터에 적용됨
-
query의 position , key의 position , attention score 는 위와 같이 정의됨
-
attention score는 absolute position이 보다 position의 상대적 위치에 의존하기 하기 때문에 RoPE는 position 정보를 상대적인 방식으로 인코딩함
Position Interpolation (PI)
-
직접적으로 확장시키는것과 달리, PI는 original context window size(Lc)에 맞도록 position indices를 down-scale함
-
다양한 interpolation 전략들은 의 scaling factor를 사용하여 제안되어옴
- Linear Interpolation, Neural Tangent Kernel(NTK), YaRN Interpolation
Positional Skip-Wise (PoSE)
-
PI는 효과적으로 position indices를 처리하지만, 시퀀스 길이가 증가하면서 계산 복잡도도 지수적으로 증가하기 때문에 극도로 긴 길이로 확장하는 것은 비현실적임
-
따라서, original context window 에서 학습하고 긴 입력에 simulate하기 위해 position indices를 조정하여 context window를 확장함
-
inference 동안 out-of-distribution position을 피하기 위해 조정된 position indices들의 상대적인 거리는 의 범위를 커버해야함
-
조정된 position indices의 fine-tuning은 기존 LLM의 능력에 해를 끼치면 안되기 때문에 조정된 position indices의 구조는 원래의 구조를 최대한 충실해야함
- original context window 를 랜덤하게 개의 chunk로 나눔.
- 각 chunk에 starting index 를 도입하여 아래의 공식을 적용하여 position indices를 나타낼 수 있음
- 각 chunk에 skipping bias term 을 샘플링 하기 위해 이산균등분포 를 도입
- skipping bias terms을 도입하는 것은 모델을 다양한 상대적 위치에 노출 시키게 됨
- target context window에 포괄적으로 적용하기 위해 training example별 모든 chunk에 length와 skipping bias term를 re-sampling 함
- input text로 부터 연속된 토큰 span을 선택하는 것도 유사한 절차를 따름. 즉, bias term을 샘플링하여 아래와 같이 할당
- 위와 같이 각 chunk의 position indices와 content를 세팅하고, 안정된 fine-tuning을 위해 position interpolation을 수행함
-
초기 bias terms 를 0으로 초기화
-
원래 모델의 능력에 악영향을 줄 수 있기 때문에 N을 2로 설정하여 원래 position structure에 최대한 유사하게 세팅
Results
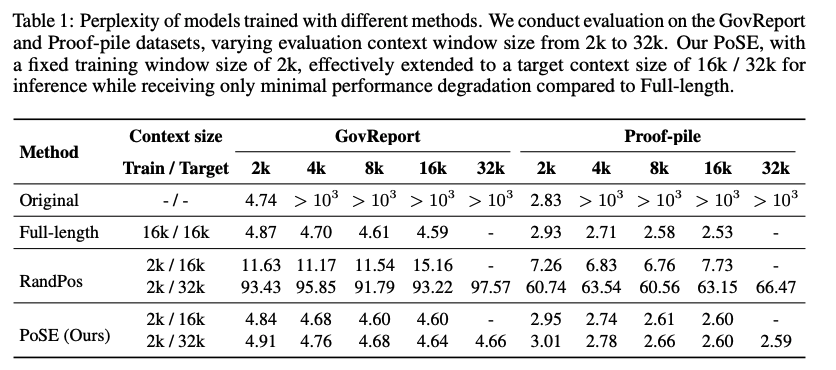
LLaMA-7B 모델을 128k tokens 까지 확장 실험
Baseline Methods
-
Full-length fine-tuning : 이 방식은 계산 복잡도가 지수적으로 증가하여, fine-tuning 전 PI를 수행함
-
RandPos : encoder-only model에 대하여 length extrapolation을 위해 처음부터 학습하도록 설계, 동등한 비교를 위해 이 방식에도 PI 적용
LANGUAGE MODELING
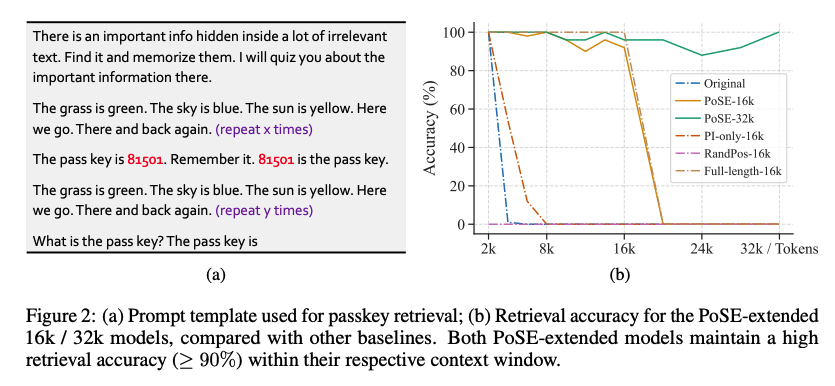
PASSKEY RETRIEVAL FOR EFFECTIVE CONTEXT WINDOW
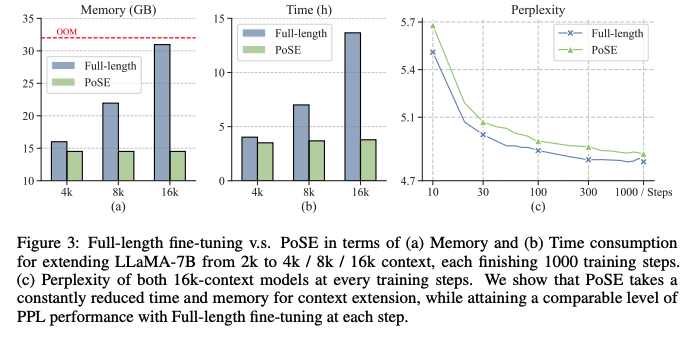
MEMORY AND TIME EFFICIENCY
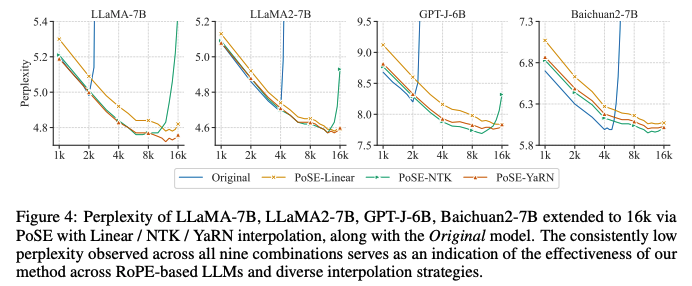
COMPATIBILITY WITH ROPE-BASED LLMS AND DIVERSE INTERPOLATION STRATEGIES
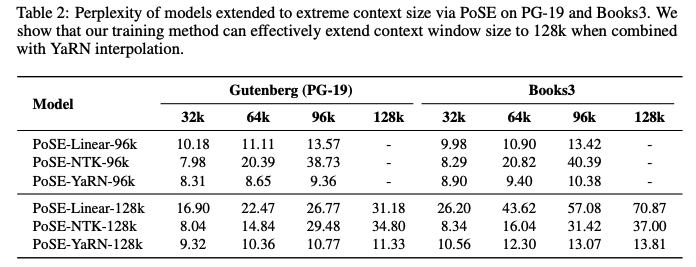
POTENTIAL FOR EXTREMELY-LONG CONTEXT
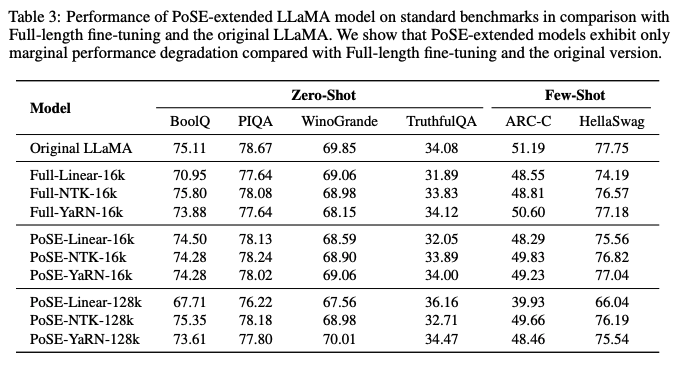
EVALUATION OF CAPABILITY ON ORIGINAL CONTEXT WINDOW
Conclusion
-
context window를 확장할 수 있는 Positional skip-wise 방식을 제시함
-
position indices를 조정함으로 매우 긴 입력에 대해서도 다룰 수 있음
-
original context window만 필요하기 때문에 train length와 target length를 분리할 수 있음
-
full-length에 대한 fine-tuning과 동등한 성능을 보여줌
-
memory, time 오버헤드를 줄임
-
최소한의 성능저하로 LLaMA를 128k까지 확장
-
RoPE base의 모든 모델과 PI 전략을 사용하는 모델과 호환 가능을 증명
