LoRA: Low-Rank Adaptation of Large Language Models
Introduction
최근 대부분의 자연어처리는 사전학습 된 초거대 언어 모델을 여러가지 downstream에 adaptation하는데 의존한다. 이런 adatation은 보통 사전학습 된 모델의 파라미터를 업데이트하는 fine-tuning과정으로 이루어진다. 하지만 이런 방법은 초거대 모델의 파라미터를 전부 업데이트해야 하는 단점이 있으며, 이는 GPT-2와 RoBERTa와 같이 단순히 불편한 부분에서 1750억개의 파라미터를 가진 GPT-3에서는 더큰 문제로 바뀌어 왔다.
이를 해결하기 위해, 일부분의 파라미터만 adaptation하거나 외부 모듈을 학습하는 방식이 제안되어 왔으며 전체 모델 파라미터가 아닌 일부분의 파라미터를 저장하고 로드하는 방식으로 효율성을 크게 향상시켰다. 하지만 기존의 방식들은 모델 깊이를 늘려 추론 지연(inference latency)이 발생하거나 모델의 입력 시퀀스의 길이를 줄여 fine-tuning 베이스라인에 맞지 않으며 효율성과 모델의 질 사이에서 trade-off가 발생한다.
본 논문은 over-parametrized model들이 실제로 낮은 고유 차원에 존재하는 것을 보여주는 Li et al.(2018)과 Aghajanyan et al.(2020) 논문들에 영감을 받았다. 따라서, 본 논문에서는 모델을 adaptation하는 동안 모델의 가중치의 변화는 낮은 "intrinsic rank"가 존재한다는 가설을 세웠으며 이를 Low-Rank Adaptation(LoRA)라고 소개한다. LoRA는 사전학습된 모델들은 freeze하며 대신 adaptation 하는 동안 dense layers의 변화의 rank 분해 행렬을 최적화하여 간접적으로 신경망을 학습할 수 있도록 한다. GPT-3 175B을 예시로, 매우 큰 full rank(d=12,288)는 매우 낮은 rank(r=1 or 2)로 충분하고 스토리지 및 컴퓨팅 자원의 효율성을 높일 수 있다.
LoRA는 몇 가지 이점들을 가지도 있다.
-
사전 학습된 모델은 다른 task에서 LoRA 모듈이 빌드하도록 공유하고 사용될 수 있다. 사전 학습 모델의 파라미터는 freeze하고 행렬 A, B로 대체함으로 스토리지 요구 및 task-witching 오버헤드를 상당히 줄일 수 있다.
-
LoRA는 파라미터에 대한 기울기를 계산하거나 옵티마이저의 상태를 유지할 필요가 없기 때문에 더 효율적인 학습과 하드웨어의 장벽을 3배까지 낮출 수 있다. 대신 추가된 훨씬 작은 low-rank 행렬을 최적화한다.
-
간단한 선형 구조로 추론 지연 없이 freeze된 가중치와 합칠 수 있다.
-
LoRA는 이전의 많은 방법들과 직교하기 때문에 prefix-tuning과 같은 방법과 결합할 수 있다.
Problem Statement
LoRA는 모델에 상관없이 적용할 수 있지만, 동기를 받은 언어 모델에 적용하는데 집중한다.
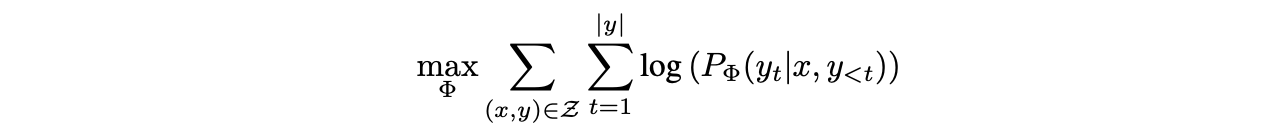
기존의 사전 학습된 언어 모델은 을 기반으로 학습되어 진다. 이렇게 학습된 모델을 downstream에 적응시키기 위해서는 페어된 학습데이터()가 필요하다. 예를 들어 요약 task에서 x는 글의 본문, y는 요약문 NL2SQL에서 x는 자연어 쿼리, y는 그에 상응하는 SQL command 이다.
이렇게 full fine tuning하는 동안, 모델의 초기 파라미터 는 초기화 되어지고 언어 모델링을 최대화 하기 위해 반복적으로 로 업데이트 된다.
full fine tuning의 주요 단점 중 하나는 와 의 차원의 크기가 같은 것 이다. 만약 GPT-3와 같이 매우 큰 모델이라면, 저장하고 배포하는 것은 매우 어려울 수 있다.
본 논문에서는 task별 파라미터()를이 더 작은 파라미터()로 인코딩시키는 파라미터 효율적인 접근 방식을 채택한다. 따라서 를 찾는 작업은 에 대해 최적화 된다.
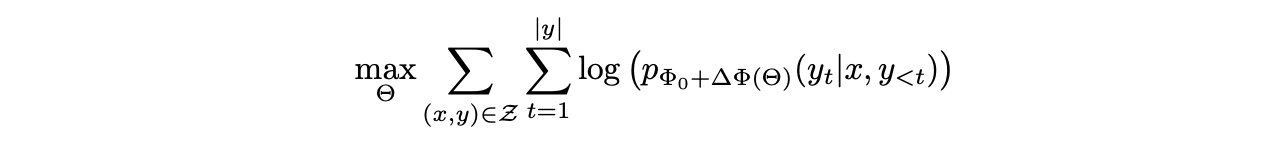
Aren't Existing Solutions Good Enough?
이 논문에서 말하는 문제들은 새로운 것을 의미하는 것이 아니다. 많은 연구들이 전이 학습이 등장한 이래로, 모델을 더 파라미터와 계산 효율적으로 만들기 위해서 노력해 왔다. 예를 들어, adapter layer들을 추가하거나, input layer의 activations들의 형태를 최적화 하는 방법들이 있다. 하지만 두 전략 모두 한계가 있으며 특히, 초거대 모델 및 latency-sensitive한 한계가 있다.
Adapter Layers Introduce Inference Latency
본 논문에서는 2가지 adapter에 집중한다.
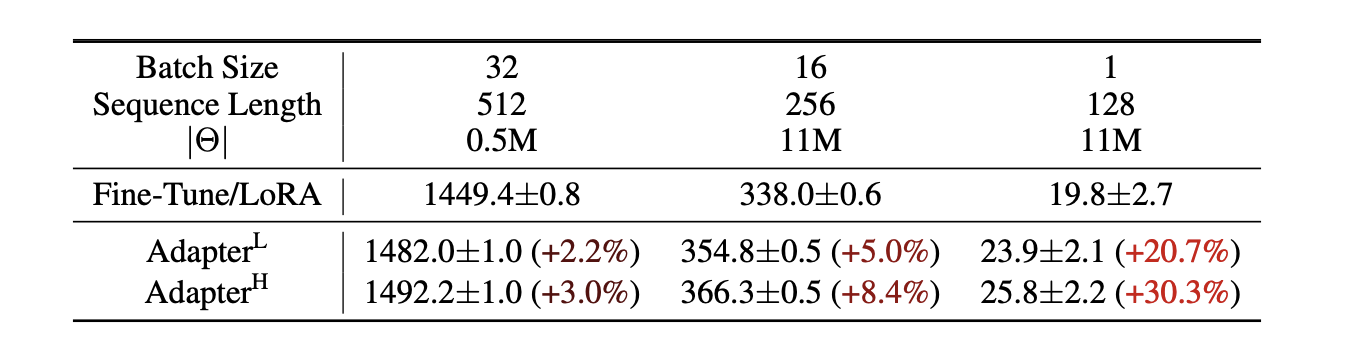
layer를 pruning 하거나 멀티태스크를 활용하여 전반적인 latency를 줄일 수 있지만, adapter layers에 추가적인 계산을 우회하는 직접적인 방법은 없다. 이는 adapter layers가 적은 파라미터를 가지도록 디자인되어 문제가 아닌것 처럼 보인다. 하지만, 거대 신경망은 latency를 낮게 유지하기 위해 하드웨어 병렬처리에 의존하고 adapter layers는 순차적으로 처리되어야 한다. 이런 상황은 1만큼 작은 배치 사이즈를 가진 온라인 추론 설정에서 차이가 있다. 단일 GPU의 GPT-2에서 추론을 진행하는 것과 같은 모델 병렬화 없는 보편적인 상황에서 adapter를 사용할 때 latency가 증가하는 것을 확인할 수 있다.
Directly Optimizing the Prompt is Hard
Prefix tuning과 같은 다른 방법들은 또 다른 문제에 직면해 있다. Prefix tuning은 최적화 하기 어렵고 학습가능한 파라미터에서 성능은 복잡하게 변한다. 근본적으로, adaptation을 위해 sequence 길이의 일부분을 남겨 두는 것은 downstream task를 처리하는데 이용할 수 있는 sequence의 길이가 필연적으로 줄어들기 다른 방법들에 비해 프롬프트를 튜닝하는 것의 성능을 저하시킨다.
Our Method
Low-Rank-Parameterized Update Matrices
신경망은 행렬곱을 수행하는 많은 dense layer들이 포함된다. 이런 layers에 가중치 행렬은 전통적으로 full-rank를 가진다. 특정 task에 adapting 할때, Aghajanyan의 논문에 따르면 사전 학습된 언어 모델은 작은 "instrisic dimension"을 가지며 더 작은 subspace로 랜덤한 projection임에도 불구하고 효과적으로 학습할 수 있다. 이에 영감을 받아, adaptation하기 위해 가중치를 업데이트 하는 것 또한 작은 "intrinsic rank"를 가진다는 가설을 세웠다.
사전 학습된 가중치 행렬은,
위와 같이 low-rank로 분해하여 표현되어 업데이트를 제한한다. 학습이 되는 동안, 는 freeze되고 기울기 업데이트를 하지 않는다. 반면에 와 는 학습 가능한 파라미터로 포함되어 진다. 와 둘다 같은 입력에 곱해지고 각각의 출력 벡터들은 coordinate-wise로 더해진다.
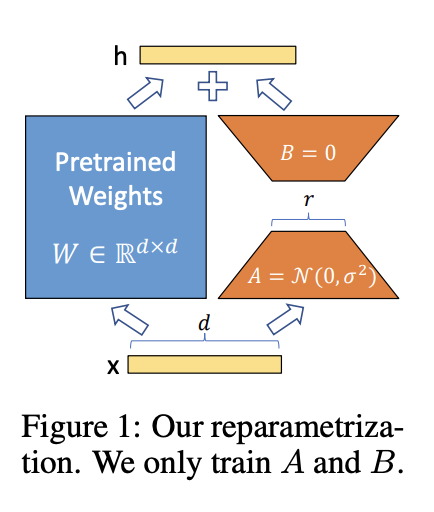
위 그림에서 본 논문에 reparametrization을 설명하고 있다. 는 random Gaussian initialization을 사용하고 는 0으로 초기화 한다. 따라서, 학습을 시작할 때 는 0이 된다. 는 로 스케일링 되며 는 의 상수이다. Adam을 이용해 최적화 할때, 를 튜닝하는 것은 대략 learning rate를 튜닝하는 것과 같다. 결과적으로 을 수정할 때 하이퍼파라미터를 다시 튜닝하는 필요를 줄여준다.
A Generalization of Full Fine-tuning
fine-tuning의 대부분의 보편적인 형태는 사전 학습된 파라미터의 일부분만을 학습할 수 있다. LoRA 한 단계 더 나아가서 adaptation 하는 동안 full-rank를 가진 가중치 행렬의 누적된 기울기 업데이트를 요구하지 않는다. 이 말은 모든 가중치 행렬에 LoRA를 적용했을 때를 의미하고 모든 biases를 학습할 때 LoRA rank 을 사전 학습된 가중치 행렬의 rank로 설정하여 full fine-tuning의 표현을 복구한다. 다시 말해, 파라미터 수가 늘어 날수록 LoRA를 학습하는 것은 원래 모델을 학습하는 것과 수렴한다. 반면에 adapter 기반 의 방법들은 MLP와 수렴하고 prefix 기반의 방법론들은 긴 입력 sequences를 사용할 수 없는 모델에 수렴한다.
No Additional Inference Latency
프로덕션에 배포될 때, 효과적으로 계산하고 로 저장할 수 있으며 평소처럼 추론할 수 있다. 와 둘다 이다. 다른 downstream task로 변환이 필요할 때, 빼고 다른 를 추가 하여 매우 작은 메모리 오버헤드로 빠르게 로 복구 할 수 있다. 결정적으로 fine-tune된 모델과 비교하여 추론하는 동안 추가적인 latency가 발생하지 않는다.
Applying LoRA to Transformer
앞선 원리대로, 학습가능한 파라미터의 수들을 줄이기 위해 신경망의 가중치 행렬의 모든 부분집합에 LoRA를 적용할 수 있다. Transformer 구조에서, 4개의 가중치 행렬()과 2개의 MLP 모듈이 있다. 출력 차원이 보통 attention head로 잘리더라도, 는 차원의 단일 행렬로 다룬다. 간단함과 파라미터 효율을 위해 downstream task를 위한 attention 가중치만 adapting 하고 MLP 모듈은 freeze하는 것으로 제한한다.
Practical Benefits and Limitations
가장 큰 이점은 메모리와 storage 사용량이 감소한 점이다. Adam으로 large Transformer를 학습할때, 만약 라면, freeze된 파라미터를 위해 옵티마이저의 상태를 저장할 필요가 없으므로 VRAM 사용량이 2/3 줄었다. GPT-3 175B의 경우, VRAM 사용량을 1.2TB에서 350GB로 줄였다. 고 오직 query와 value를 projection한 행렬들을 adapt한다면, 체크포인트의 크기가 350GB에서 35MB로 10,000배 감소한다. 이를 통해 상당히 적은 GPUs로 학습하고 I/O 보틀넥을 피할 수 있다. 또 다른 이점은 모든 파라미터가 아니라 LoRA의 가중치들을 교환하는 것 만으로 더 적은 비용을 통해 배포하는 동안 task들 사이를 전환할 수 있다. 이것은 VRAM에 사전 학습된 가중치들을 저장한 것에 의존하지 않고 교환할 수 있는 커스터마이징된 다양한 모델을 생성 할 수 있다. 또한, GPT-3 175B 학습 시간은 25% 감소했다.
LoRA 또한 한계점이 있다. 예를 들어, 추가적인 추론 지연을제거하기 위해 와 를 로 흡수하는 것을 선택한다면, 와 가 여러 task에 대한 입력을 batch 처리하는 것은 쉽지 않다. 가중치를 합치지 않고 latency가 중요하지 않은 시나리오의 경우 batch에서 샘플에 사용할 LoRA 모듈을 동적으로 선택할 수 있다.
