Prefix-Tuning: Optimizing Continuous Prompts for Generation
Introduction
Fine-tuning은 일반적으로 사전학습된 모델을 downstream task에 사용하는 방법이다. 하지만 이 방법은 모델의 모든 파라미터를 업데이트해야 하며 저장을 해야한다. 결과적으로 LLM에 의존하는 NLP 시스템을 개발하고 배포하기 위해서는 각각의 task에 맞게 수정된 모델 파라미터들을 저장해야 한다. GPT-2(774M)와 GPT-3(175B)같은 현재의 언어 모델들을 다루기에는 매우 비싸다.
이런 문제를 해결하기 위한 접근법으로 대부분의 사전학습된 파라미터들을 freeze하고 매우 작은 수의 파라미터들만 학습하는 lightweight fine-tuning이 있다. 예를 들어, adapter-tuning은 사전학습된 언어모델들의 layer 사이에 각각 테스크에 맞는 layer들을 추가하는 방법이다. 이 방식은 약 2-4%의 파라미터들을 추가하고 fine-tuning 하여 Natural Language Understanding(NLU)와 NLG(Natural Language Generation)분야에서 성능 향상을 선보였다.
GPT-3는 모델의 파라미터들의 수정 없이 프로픔트 형태를 제공하는 in-context learning을 사용하여 배포되어질 수 있다. in-context learning은 task에 대한 설명(e.g. TL;DR for summarization)이나 몇몇 예시들을 input데이터 앞에 prepend하여 원하는 output을 얻는 방식이다. 하지만, Transformer 제한된 길이의 컨텍스트(e.g. 2048 tokens for GPT-3)만 가질 수 있기 때문에 in context learning도 매우 작게되는 제한이 있다.
본 논문에서는 prefix-tuning을 제안한다. 이 방법론은 prompt에서 영감을 받아 NLG task를 위한 fine-tuning을 대체할 수 있는 방법이다.
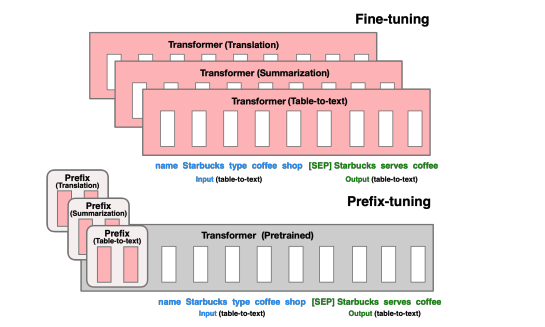
위의 그림에과 같이, prefix-tuning은 continuous task-specific vector(prefix)들을 앞에 붙여 활용한다. 프롬프트와 달리 prefix는 실제 토큰이 아닌 가상의 토큰으로 구성되어 있다. 따라서, 전체 모델을 업데이트해야 했던 것과는 달리 prefix만을 최적화하는 방식이 prefix-tuning이다. 결국 prefix-tuning은 하나의 LLM과 task에 맞고 매우 작은 prefix만을 필요로 한다. 이 방식은 결국 모듈화를 할 수 있으며 data cross-contamination도 피할 수 있다.
본 논문에서는, Prefix-tuning은 GPT-2를 사용한 table-to-text task와 BART를 사용한 abstractive summarization task를 통해 평가한다. storage 관점에서, prefix-tuning은 full fine-tuning보다 1000배 더 적은 파라미터를 저장한다. 성능면에서, full dataset setting에서는 fine-tuning과 동등한 결과를 보여줬으며 요약에서는 낮은 성능을 보여줬다. low data setting에서는 2개의 task에서 모두 fine tuning보다 더 나은 성능을 보여줬다. prefix-tuning은 table-text와 보지 못한 주제에 관한 요약에서 더 나은 성능을 보였다.
Related Work
Fine-tuning for natural language generation
현재 NLG에서 SOTA 모델들은 언어모델을 fine-tuning하는데 기반을 둔다. table-to-text task에서도 sequence-tosequence 모델을 fine-tune하여 사용한다. extrative, abstractive 요약도 BERT와 같은 masked language model과 BART와 같은 encoder-decoder model을 fine-tune하여 사용한다. 그 외 번역이나 대화 생성과 같은 분야에서도 fine-tuning은 일반적인 방법으로 사용된다. 본 논문에서는 GPT-2를 사용한 table-to-text와 BART를 사용한 요약에 중점을 두지만, prefix-tuning은 다른 생성 task와 사전학습된 모델들에 사용될 수 있다.
Lightweight fine-tuning
prefix-tuning은 대부분의 사전학습된 모델의 파라미터를 freeze하고 작은 파라미터들을 학습하는 lightweight fine-tuning 방법론에 광범위하게 포함된다. 핵심은 어떻게 언어모델의 구조를 증가시키고 학습하기 위한 파라미터들의 부분집합 어떻게 결정하는지이다. 몇몇 논문에서는 task별 파라미터 mask를 학습하는 방법을 소개하기도 한다. 또 다른 연구에서는 학습가능한 파라미터를 가진 새로운 module들을 삽입하는 연구도 존재한다. 예를 들어, 언어모델 사이에 task에 맞는 layer(adapter)를 삽입하여 이들을 학습시키는 방법도 존재한다. 해당 연구와 비교하여, prefix-tuning은 30배 더 적은 파라미터와 약 0.1%만 tuning하여 table-to-text task에서 비슷한 성능을 보여준다.
Prompting
프롬프팅은 특정 지시사항을 prepend하거나 task에 맞는 몇몇 예시를 제공하는 방법으로 사전학습된 언어모델에 영향을 주는 방법이다. GPT-3 논문에서 보여주는 few-shot learning이 가장 성공적인 형태이다. BERT와 RoBERTa같은 masked 언어모델에서 prompt engineering은 NLU task에 맞게 연구되었다. 예를 들어, AutoPrompt(Shin et al. 2020)에서는 BERT와 RoBERTa로 부터 감정이나 실제 지식을 유도하기 위해 일련의 trigger word와 입력과 연결한 연구를 하기도 했다. 본 논문과 다른점은, descrete한 word를 사용하는 것이 아니라 continuous한 vector(prefix)를 사용한다는 점이다.
LSTM과 같은 모델에서는 input에 맞게 continous vector를 최적화하여 문장을 생성할 수 있지만 prefix-tuning은 task에 맞게 prefix를 최적화 한다. 결과적으로 문장을 재생성하는데 의미를 둔 이전의 연구들과 달리 prefix-tuning은 NLG task에 의미를 둔다.
Controllable generation
controllable generation은 문장 수준의 속성(긍부정)과 매치된 사전학습된 언어모델을 다루는데 목표를 둔다. 이런 control은 학습하는 동안 발생할 수 있다. Keskar et al(2019) 연구에서는 키워드 또는 url과 같은 메타데이터를 조건으로 언어모델을 사전학습 했다. 학습하는 동안 뿐만 아니라, decoding하는 동안에서도 일어날 수 있는데, GeDi, Krause et al. 2020과 Dathathri et al. 2020이 대표적인 논문이다. 하지만, table-to-text와 summarization과 같은 task에서 요구되는 것처럼 세밀하게 제어할 수 있는 확실한 controllable generation 방법은 없다.
P*-tuning
Prefix-tuning은 continuous prefix 또는 prompt를 최적화 한다는 아이디어에 기반을 둔 p-tuning(e.g. p-tuning, prompt-tuning, also start with p) 방법 중 하나이다. P-tuning은 prompt embedding과 언어모델 파라미터들이 결합하여 업데이트 함으로, NLU task에서 GPT-2의 성능을 향상시킨다. Prompt-tuning은 접근방식을 단순화하고 T5에 적용하여 모델 크기가 커짐에 따라 fine-tuning과 p-tuning의 성능 차이가 사라지는 것을 보여준다.
Prefix-Tuning
Intuition
Prompting은 파라미터 업데이트 없이 적절한 context로 언어모델을 다룰 수 있다는 것을 보여줬다. 이처럼 하나의 단어 또는 문장들을 넘어 NLG task를 해결하기 위해 사용되는 언어 모델을 다룰 수 있는 context를 찾는것을 원했다. 직감적으로, 그 context는 input x로부터 무엇을 얻고 싶은지 가이드함으로 x에도 영향을 주고 다음 토큰들에게 영향을 줌으로 output y에도 영향을 준다. 하지만 이런 context가 존재하는지 명확하지 않다. "다음 표를 한줄로 요약해라"라는 지시사항은 사람이 작업을 해결할 수 있도록 가이드 할 수 있지만 중간 크기의 언어모델은 실패한다. 이와 같이 discrete한 지시 사항을 최적화하는 것은 도움될 수 있지만 효율적으로 하기 어렵다.
discrete한 token들을 최적화하는 것 대신, continuous vector를 최적화할 수 있고 이 영향은 activation layer와 후속 토큰으로 전파된다. 이 방법은 실제 단어의 embedding으로 제한된 discrete prompt보다 더 좋은 표현력을 보인다. prefix-tuning은 단순히 embedding layer가 아니라 모든 layer를 최적화함으로 더 표현력이 좋아진다. 또 다른 이점으로, 직접적으로 representation을 수정할 수 있고 네트워크의 깊이에 따른 긴 계산을 피할 수 있다.
Method
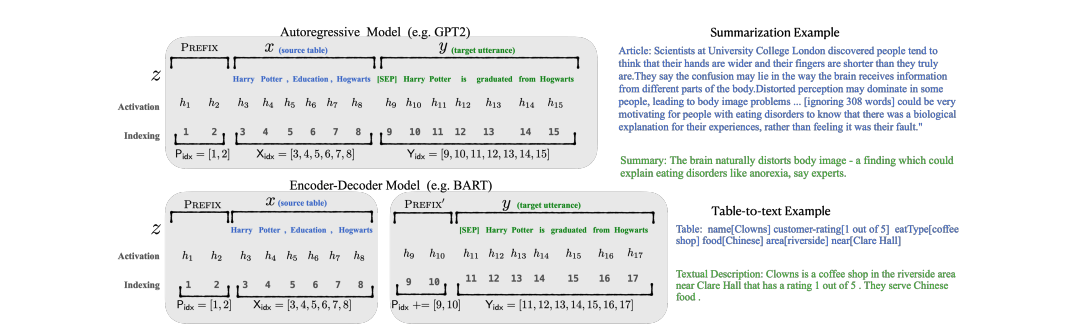
위의 그림과 같이 Autoregressive LM에는 , encoder-decoder에서는 의 형태로 prepend한다. 여기서 는 prefix의 인덱스를 나타내고 는 prefix의 길이를 나타낸다. prefix 파라미터는 의 차원을 가진다.
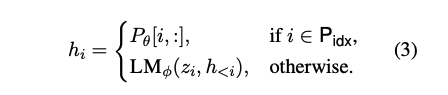
위의 식처럼, 일때, 의 값을 복사하여 사용한다. 이 경우가 아니라면, prefix 활성은 항상 왼쪽에 존재하고 그 영향을 오른쪽으로 전파하기 때문에 는 여전히 에 의존한다.
Parametrization of
실험적으로, 직접 를 업데이트하는 것은 불안정한 최적화와 성능 저하를 이끈다. 그래서 로 reparameterize한다. 여기서 는 large feedforward neural network(MLP)로 구성된 작은 matrix이다. 결국, 학습가능한 파라미터는 와 MLP의 파라미터를 포함한다. 와 는 같은 수의 행를 가지지만 열은 다르다. 학습이 완료되면, reparameterization 파라미터들은 빼고 오직 prefix()를 저장한다.
Main Results
-
table-to-text에서 0.1%의 파라미터를 추가해 fine-tuning과 비슷한 성능을 보여주며 일반화 성능도 좋다.
-
summarization에서는 fine-tuning보다는 낮은 성능을 보여줬다.
-
데이터가 적을 때, fine-tuning 대비 좋은 성능을 보여준다.
