GPT Understands, Too
Introduction

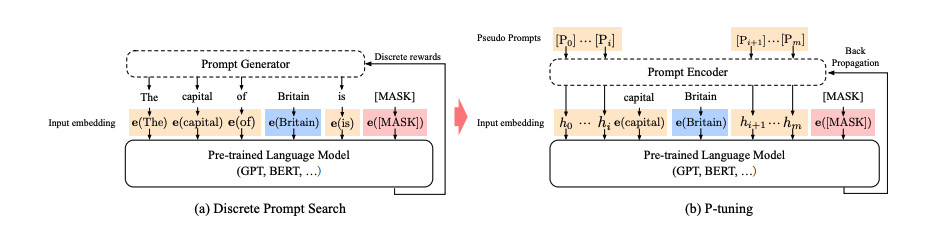
PLMs(Pretrained language models)은 NLU(natural language understanding)의 성능을 상당히 향상시켰다. PLMs은 masked language modeling, autoregressive language modeling, seq2seq, permutation language modeling과 같이 다양한 pre-training objective와 함께 학습되어 진다. PLMs은 input에 직접 작성한 prompt pattern을 추가하는 prompting 기술로 더욱 더 향상될 수 있다. PLM은 small labeled dataset에서 fine-tuning하거나 dawonstream tasks에서 추론을 위해 frozen된다. Prompting은 다양한 NLU tasks에서 상당히 향상된 성능을 보여준다. 하지만, 수동으로 작성된 discrete prompt는 큰 불안정성을 보이는 것을 발견할 수 있다. 위 Table에서 처럼, prompt에서 하나의 단어를 변경하는 것은 상당한 성능 저하를 일으킬 수 있다.
discrete prompts의 불안정성을 줄이기 위해, discrete prompts와 연결하여 학습가능한 continuous prompt embedding을 사용하는 P-tuning을 제안한다. 특히, input으로 discrete prompt가 주어질 때 P-tuning은 input과 continuous prompt embeddings을 연결하고 그것을 언어모델의 input으로 사용한다. continuous prompts는 task objective를 최적화하기 위한 역전파로 업데이트 된다. 성능을 더 높이기 위해, LSTM이나 MLP를 사용한 prompt encoder를 적용하여 continuous prompt embeddings 사이의 의존성을 모델링한다.
연구는 LAMA, SuperGLUE benchmark에서 진행하고 frozen 언어 모델을 사용한 LAMA, fine-tuning한 언어 모델을 사용한 SuperGLUE에서 월등한 성능을 보여줬다.
Method
Issues with Discrete Prompts
-
성능이 좋은 discrete prompts를 작성하는 방법은 여전히 문제가 된다.
-
위의 table에서 처럼 discrete prompts에서 하나의 단어만 변경해도 성능 저하가 크게 일어 난다.
-
다양한 연구에서 discrete prompts를 자동으로 찾는 것을 제안하지만, 불안정성은 변하지 않는다.
-
discrete space에서는 역전파의 기울기를 완전히 사용할 수 없다.
P-Tuning
-
: PLM
-
: hidden size
-
: vocabulary size
-
: labeled dataset
-
: input : consisting of sequence of discrete tokens
-
: label
-
을 fine-tuning 또는 frozen하여 의 조건부 확률을 추정하는 것이 목표이다.
-
를 discrete prompt token이라고 하고 각 prompt는 template 로 묘사할 수 있다.
-
template은 labeled data를 포함해 sequence로 구성하고 task를 input text의 빈칸을 채우는 것으로 재구성 될 수 있다.
-
"The capital of [INPUT] is [LABEL]" -> "The capital of Britain is [MASK]"
-
결과적으로 discrete prompt와 discrete data 둘다 input embedding으로 매핑되어 진다.
-
이전에도 언급한것 처럼, discrete prompt는 극도로 불안정한 경향이 있고 역전파에 최적화되지 못하기 때문에 P-Tuning을 제안한다.
-
: 번째 continuous prompt embedding
-
Template of P-tuning :
-
P-tuning은 추가적인 embedding을 활용하여 로 매핑한다.
-
-
결국 task loss function의 최적화를 위해 embedding들을 업데이트 한다.
-
P-tuning은 fine-tuned와 frozen language model 둘다 적용할 수 있다.
Prompt Encoder
-
앞서 설명한 은 학습가능한 embedding 를 model input 로 매핑한다.
-
이런 함수는 독립전인 학습가능한 embeddings과 비교하여 다른 prompt embedding들 사이의 의존성을 모델링하는데 편리하다.
-
으로 LSTM, MLP와 같이 lightweight neural network를 사용한다.
Experiments
Knowledge Probing
Setup
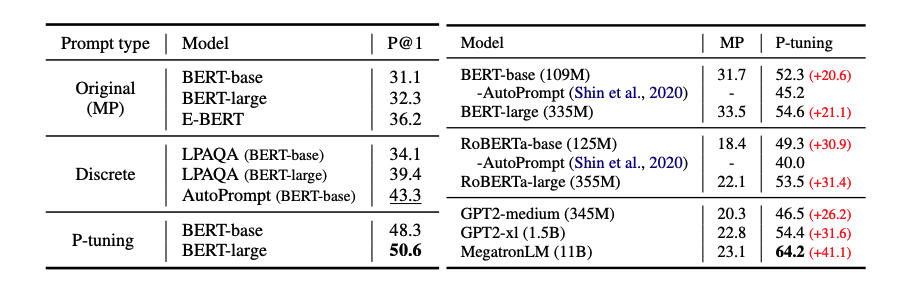
실험은 LAMA에서 진행된다.
-
Knowledge probing은 사전학습된 언어모델이 얼마나 실세계의 지식을 가지고 있는지 평가한다.
-
masked language model을 위해 [X]를 subject entity로 [Y]를 [MASK]로 대체한다.
-
GPT와 같은 단방향 모델에서 LAMA의 기본 설정을 따르고 target position 전의 네트워크 출력을 사용한다.
-
양방향 모델의 경우 template는 (3, sub, org_prompt, 3, obj, 3)
-
단방향 모델의 경우 template는 (3, sub, org_prompt, 3, obj)
-
Adam optimizer, learning rate(1e-5)를 사용한다.
Main results
Fully-supervised Learning
Setup
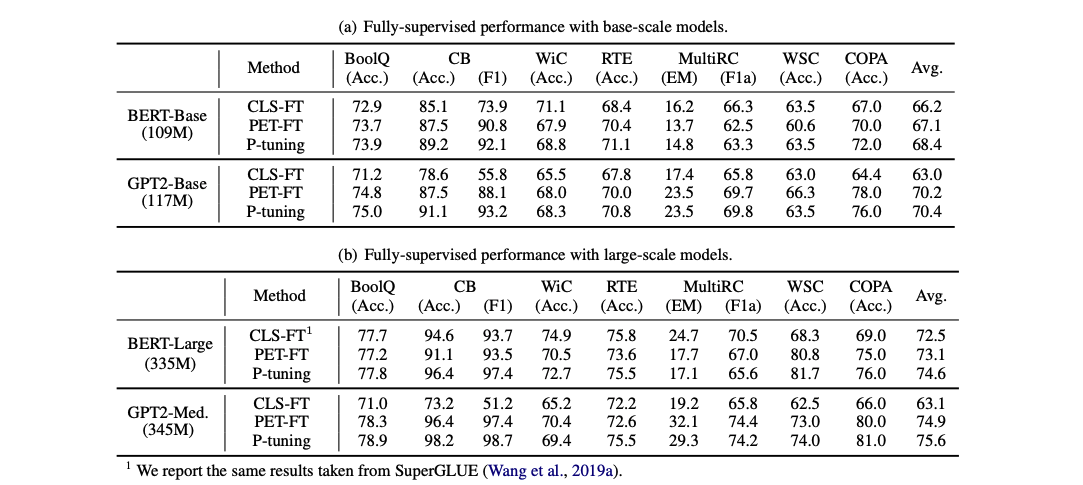
실험은 SuperGLUE의 ReCoRD를 제외한 7개의 NLU task에서 진행된다.
-
다양한 모델에서 CLS fine-tuning, PET(기존의 discrete prompts를 사용한 fine-tuning), P-tuning을 비교한다.
-
linearly decayed learning rate와 함께 AdamW optimizer를 사용한다.
-
learning rate는 [1e-5, 2e-5, 3e-5], batch size는 [16, 32], warm-up ratio는 [0.0, 0.05, 0.1]을 사용한다.
-
작은 데이터셋에서는 20 epochs, 큰 데이터셋에서는 10epochs로 줄인다.
-
오버피팅을 피하기 위해 elrly stopping을 사용한다.
Main results
Few-Shot Learning
Setup
FewGLUE로 알려진 few-shot SuperGLUE에서 진행한다.
-
few-shot의 성능은 다양한 요소들에 민감하고 high variance를 일으킨다.
-
따라서, 평가는 variance 대신 실제로 확인해야 한다. 이를 위해, FewNLU 평가 절차를 따른다
-
base model로 ALBERT-xxLarge를 사용한다.
-
learning rate는 [1e-5, 2e-5], maximum training step은 [250, 500], evalutation frequency는 [0.02, 0.04]로 설정한다.
-
PET을 위해 Schick and Schutze(2020)에서 발표한 manual prompts를 사용하며 P-tuning도 같은 prompts를 사용하지만 continuous prompt token을 추가한다.
Main results
Few-Shot Performance

Ablation Study
Type of Prompt Encoder
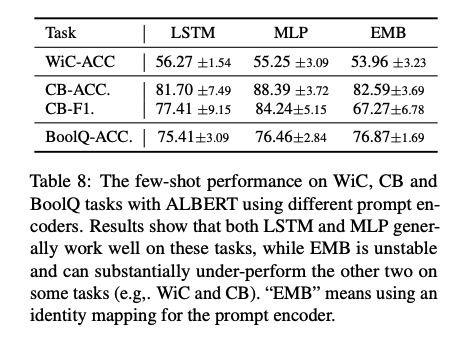
Location of Prompt Tokens & Number of Prompt Tokens

Comparison with Discrete Prompt Search
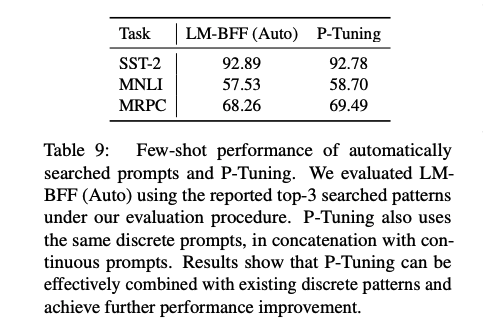
Stablilizing Language Model Adaptation
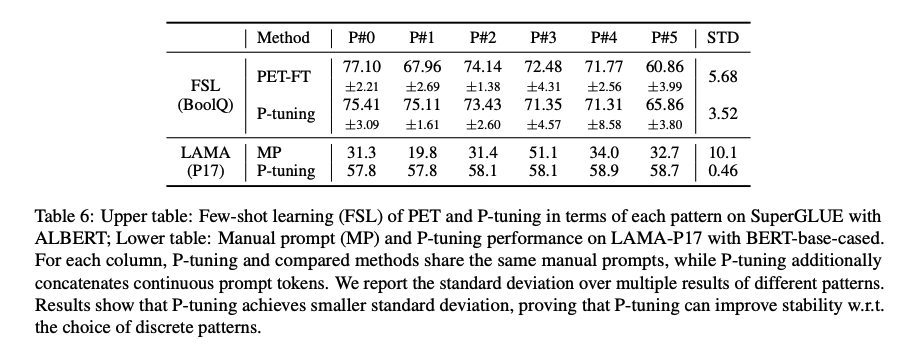
P-tuning은 P#5의 최악의 패턴에서도 안정성을 유지할 수 있다.
Related work
-
GPT-3의 in-context example을 통해 downstream task에 지식을 전이하는 방법
-
cloze pattern을 사용해 few-shot learning을 하는 방법
-
학습 corpus를 mining하여 고성능 prompt를 자동으로 검색하는 방법
-
gradient-based search 방법
-
generative models을 사용하는 방법
-
Prefix-tuning 방법
P-tuning은 few-shot과 fully-supervised 설정에서 frozen, finetune model 둘다의 성능 향상을 보여주는 결론을 유일하게 보여준 연구이다.
Conclusions
본 논문에서는 continuous와 discrete prompt를 연결한 P-tuning을 제시했고 성능 향상과 안정성을 보여줬다. 또한 few-shot과 fully supervised 설정에서, frozen model과 fine-tuning 모델 모두에서 성능 향상을 보여줬다.
