The Power of Scale for Parameter-Efficient Prompt Tuning
Introduction
사전학습된 언어 모델이 성공함에 따라 downstream task에 보편적으로 이용할 수 있는 모델을 adpat하는 기술들도 연구되어 왔다. ELMo 연구에서 사전학습된 모델을 freeze하고 task에 맞는 가중치를 학습하는 것을 제안했다. 하지만 GPT와 BERT 이후로 모든 파라미터를 업데이트 하는 fine-tuning이 대표적인 adaptation 방법이 되었다. 최근 연구에서는 Text prompt를 통해 GPT-3 모델을 freeze하고 놀랄만한 성능을 보여준 prompt design(or "priming")도 알려졌다. prompt는 task에 대한 설명과 예시들로 구성된다. 특히, 모델의 크기가 증가함에 따라 사전학습된 모델을 freezing하는 것은 매력적이다. downstream task 각각에 모델을 분리하는것 보다는 하나의 generalist 모델은 다양한 task에 동시에 사용할 수 있따.
불행하게도, prompt 기반의 adaptation은 몇 가지 단점을 가진다. Task description은 에러를 만들기 쉽고 사람의 개입을 필요로 하며 prompt의 효과는 모델의 입력의 크기에 제한된다. 결과적으로 downstream task의 질은 모델을 fine-tuning 하는것 보다 훨씬 뒤쳐진다. 예를 들어, SuperGLUE에 대한 GPT-3 175B의 few-shot의 성능은 T5-XXL보다 16배 많은 파라미터를 사용함에도 불구하고 17.5 포인트 낮다.
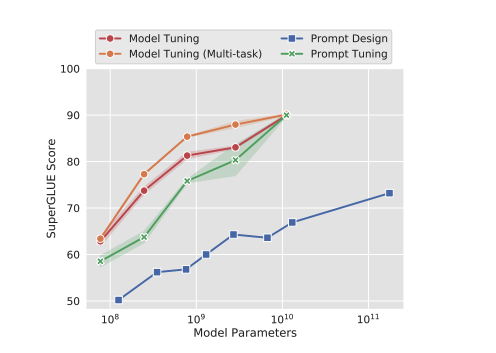
본 논문에서는 언어 모델의 adapting을 위한 더 단순화한 prompt tuning을 제안한다. 사전학습된 모델을 전부 freeze하고 오직 input text에 prepend되고 tuning 할 수 있는 토큰 개만 허용한다. 이 "soft prompt"는 end-to-end로 학습되어지고 full labeled dataset으로 부터의 신호를 압축할 수 있으며 이런 방법으로 model tuning의 격차를 줄이고 few shot prompt를 능가한다(위의 그림 참고).
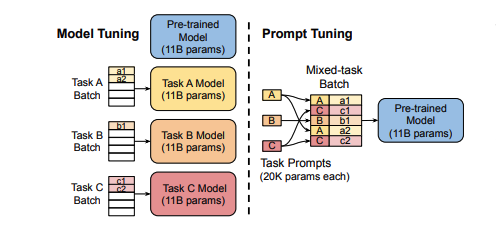
동시에 사전학습된 단일 모델은 모든 downstream task에 재활용되므로, frozen 모델의 이점을 효율적으로 유지할 수 있다.
prompt tuning은 intermediate-layer prefix나 task-specific output layer 없이 모델 튜닝과 충분히 경쟁할 수 있음을 보여준 첫번째 연구이다.
-
prompt tuning은 LLM의 체제에서 모델 tuning과 경쟁할 수 있음을 보여준다.
-
다양한 디자인 선택을 제거하고 스케일에 따라 품질과 강건함이 향상되는 것을 보여준다.
-
domain shift 문제에서 모델 tuning을 능가하는 것을 보여준다.
-
"prompt ensembling"을 제안하고 이것이 효과적인 것을 보여준다.
Prompt Tuning
Prompting은 를 생성하는 동안 조건에 맞게 모델에 추가적인 정보를 더해주는 접근법이다. 일반적으로, prompting은 모델의 매개변수 를 고정하고 의 우도값을 최대화하기 위해 에 토큰()을 prepending하는 방식이다.
GPT-3에서 prompt tokens의 표현은 freeze된 에 의해 parameterize 되어진 모델의 embedding table의 일부이다. 또한 최적의 prompt를 발견하는 것은 manual search나 non-differentialble search 방식을 통해 prompt token을 선택해야 한다.
Prompt tuning은 에 의해 (prompt)가 parameterize되는 것을 제한하고 대신에 업데이트할 수 있는 를 가진다.
Prompt design은 고정된 frozen embedding의 vocabulary에서 prompt token들을 선택하는 것을 포함하지만, Prompt tuning은 이런 prompt token들의 embeddings만 업데이트할 수 있는 고정된 spectial tokens을 사용하는 것으로 생각할 수 있다.
본 논문에서 제시하는 새로운 조건부 생성은 로 정의할 수 있고 역전파를 통해 Y의 우도를 최대화하고 만 업데이트하여 훈련할 수 있다.
개의 토큰 이 주어졌을때, T5모델이 첫번째로 하는 것은 를 로 임베딩하는 것이다(여기서 는 임베딩 차원). 본 논문에서의 soft-prompts는 로 prompt를 임베딩 하는 것이며 여기서 는 prompt의 길이이다. prompt는 임베딩된 input과 연결하여 하나의 행렬인 의 형태로 모델의 encoder와 decoder를 통과하게 된다. 본 논문의 모델은 의 확률을 최대화 하도록 학습되어지며 여기서는 오직 만 업데이트 되어진다.
Design Decisions
prompt representation을 초기화하는 방법은 다양하게 있으며 가장 간단한 것은 random initialization을 사용하여 처음부터 학습하는 것이다. 더 정교한 옵션은 prompt를 모델의 vocabulary에서 추출한 embedding으로 초기화하는 것이다.
개념적으로 soft-prompt는 input의 앞의 text와 같은 방식으로 freeze된 모델의 행동을 조절하기 때문에 soft-prompt는 word와 같은 표현으로 좋은 초기화 지점으로 제공될 수 있다. classification에서, Schick and Schuze(2020)의 논문에서 제안한 "verbalizers"와 비슷하게 output class들을 열거하는 임베딩으로 프롬프트를 초기화하는 것이 세번째 옵션이다. 논문에서는 output에서 이러한 tokens들을 생산하는 모델을 원하기 때문에 유효한 타겟 토큰 임베딩들의 prompt를 초기화하는 것은 모델의 출력이 적절한 output class로 제한되도록 모델을 준비해야 한다.
또 다른 design 고려 사항은 prompt의 길이이다. prompt tuning의 parameter cost는 로 나타낼 수 있으며 여기서 는 토큰 임베딩 차원, 는 prompt의 길이이다. prompt의 길이가 짧을 수록 더 적은 파라미터를 업데이트하므로, 좋은 성능을 가진 최소 길이의 prompt를 찾는 것을 목표로 한다.
Unlearning Span Corruption
autoregressive한 GPT-3와 달리, T5 모델은 encoder-decoder 구조이며 span corruption objective에 대해 사전학습한다. 특히, T5는 unique sentinel token으로 표시된 input text에서 masked span을 "reconstructing"하는 task를 수행한다. target output text는 sentinel들로 분리된 masked content와 final sentinel로 구성된다. 예를 들어 " Thank you for inviting me to your party last week"문장은 "Thank you <X> me to your party <Y>"로 입력되어 지고 target output은 "<X> for inviting <Y> last <Z>"이 된다.
Raffel et al.(2020)에서는 이런 아키텍처가 전통적인 모델링보다 더 효과적인 pre-training 방법이라고 소개하는 반면에, 본 논문에서는 이런 setup이 prompt tuning을 통해 쉽게 통제가능한 frozen 모델을 생성하는 것에 적합하지 않다고 가정한다. 특히, T5.1.1처럼 span corruption에 대해 사전학습된 T5 모델은 자연스러운 input text(free of sentinel tokens)를 본적이 없고 자연스러운 대상을 예측하라는 요청을 받은적도 없다. 실제로, T5의 sapn corruption 전처리 세부 사항들 덕분에, 모든 pre-training target은 sentinel로 시작된다. 이처럼 sentinel들을 출력하는 "unnatural"한 경향은 fine-tuning으로 극복하기 쉽지만, decoder의 우선 순위들을 조절할 수 없기 때문에 prompt만으로 override하는 것은 더 어려울 것으로 의심된다.
이러한 문제점 고려하여, 3가지 셋팅으로 T5 모델을 실험한다.
-
"Span Corruption" : frozen 모델로 사전학습된 T5를 사용하고, downstream task를 위한 예상된 텍스트를 출력하는 기능을 테스트한다.
-
"Span Corruption + Sentinel" : 1번과 같은 모델을 사용하지만 모든 downstream target에 sentinel을 prepend하여 pre-training에서 볼 수 있는 target과 더 유사하게 한다.
-
"LM Adaptation" : T5의 적은 수의 추가 단계를 위해 self-supervised training을 하지만 자연적인 text prefix가 주어지면, 모델은 output으로 natural text를 연속으로 생성해야 하는 "LM" objective를 사용한다. 결정적으로, 이런 adaptation은 오직 한 번만 이루어지고, 대부분의 downstream task에 prompt tuning을 위해 재사용할 수 있는 frozen 모델을 생성한다.
LM Adaptation을 통해, T5가 항상 realistic text를 출력하고 "few-shot learner"로 prompt에 잘 반응하는 것으로 알려진 GPT-3와 더 유사한 모델로 "quickly" 변환하기를 원한다. last-stage의 변화가 처음부터 pre-training하는 것과 비교하여 얼마나 성공적인지는 분명하지 않고, 이전에 조사되지 않았다. 이처럼, 100K 단계까지 adaptation의 다양한 길이를 실험한다.
Results
frozen 모델들은 모든 사이즈(small, base, large ..)의 사전학습된 T5이 대해 구현된다. 기존의 T5보다 향상된 public T5.1.1을 활용한다.
default 설정은 추가된 100K 단계에 대해 학습된 LM-adapted 버전의 T5를 사용하고, class label을 사용하여 초기화하며 100 tokens의 prompt length를 사용한다. Li and Liang (2021)연구에서 사용된 default(10-token)보다 더 길지만, 논문의 방법은 모든 layer들을 tuning하는 것과 달리 오직 input layer만 tuning함으로 여전히 더 적은 task-specific parameter를 사용한다. 또한 모델 크기가 증가함에 따라 더 짧은 prompt도 사용할 수 있다는 것을 볼 수 있다.
8가지의 English language understanding tasks로 이루어진 SuperGLUE benchmark로 성능을 측정한다. 각각의 prompt는 multi-task나 mixing of training data across tasks 없이 SuperGLUE task에 대해 학습한다. SuperGLUE 데이터셋의 input 데이터에 예시를 나타내는 task name을 제외하고 text-to-text 형태로 변환한다.
learning rate는 0.3, batch size는 32, T5의 standard cross-entropy loss를 사용하여 30,000 step을 학습한다. checkpoint는 early stopping을 통해 선택하고, stopping metric은 데이터셋의 default metric을 사용하거나 multiple metric의 평균을 사용한다. 모든 실험을 , 그리고 parameter scaling off로 Adafactor optimizer를 사용하여 JAX에서 수행되고 모델은 Flax에서 구현된다.
Closing the Gap
기존의 모델 tuning과 비교하기 위해, 본 논문에서는 T5 library에 명시된 default hyperparameter를 사용하여 SuperGLUE에 대한 public T5.1.1 튜닝한다. 본 논문에서는 2가지 baseline에 대해 고려한다.
-
"Model Tuning" : apples-to-apples를 비교하기 위해 task 별로 분리하여 prompt tuning을 수행한다.
-
"Model Tuning (Multi-task) : 더 경쟁력 있는 baseline을 위해 T5의 multi task tuning을 사용한다. 이 경우에, 하나의 모델은 task name을 나타내는 text prefix를 사용하여 모든 task와 연결되어 tuning한다.
위의 그림에서 prompt tuning은 모델의 크기가 커질수록 model tuning과 성능이 비슷해진다. XXL size(11B params)에서, prompt tuning은 multi-task model tuning baseline보다 20,000배 더 적은 파라미터를 가짐에도 불구하고 성능을 비교할만하다.
prompt design을 비교하기 위해, SuperGLUE에 대한 GPT-3의 few-shot의 성능을 포함한다. 위 그래프에서 prompt tuning은 GPT-3의 prompt design을 큰 차이로 더 좋은 성능을 보여준다.
Ablation Study
Prompt Length
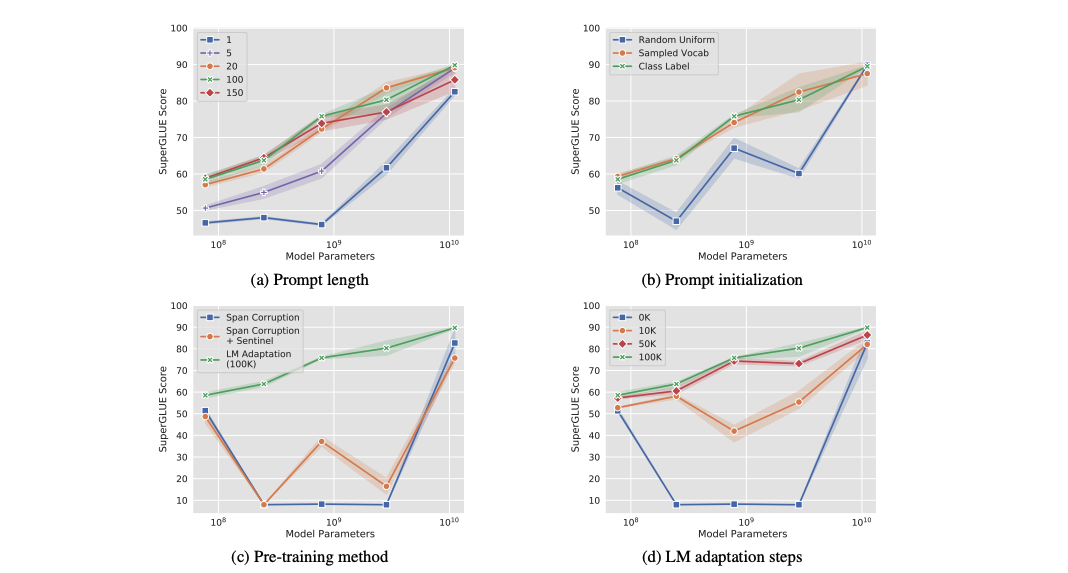
default configuration을 고정하고 오직 prompt length(1, 5, 20, 100, 150)만 달리하여 각각의 모델에 크기에 prompt를 학습한다. 위의 그래프는 대부분의 모델 크기에서 하나의 토큰 이상으로 prompt length를 증가시키는 것이 좋은 성능을 달성하는데 중요하다는 것을 보여준다. XXL 모델은 하나의 prompt 토큰을 사용해도 매우 좋은 결과를 보여주며, 모델이 더 커질수록 목표를 달성하는데 필요한 조건이 적음을 암시한다. 모든 모델에서 토큰을 20개 이상 증가시키는 것이 이점을 얻을 수 있다.
Prompt Initialization
default configuration을 고정하고 학습하여, 모든 크기의 모델에서 prompt initialization의 효과를 제거한다. random initialization는 [-0.5, 0.5] 범위에서 uniform하게 sampling한다. vocabulary initialization은 T5의 sentence-piece vocabulary의 가장 "common"한 토큰 5,000개로 제한하고 이것은 pre-training corpus의 우도에 의해 정렬된다. class label initialization은 downstream task에서 각각의 class의 string representation의 임베딩을 택하여 이를 prompt의 token들 중 하나를 초기화한다. class label이 multi-token일때는 token 임베딩값들의 평균을 취한다. prompt의 길이가 길어질수록 모든 prompt token을 초기화하기 전에 class label이 종종 부족해진다. 이런 경우에는 sampled vocabulary 전략으로 돌아간다.
위의 그래프에서 class base의 initialization 전략이 가장 우수한 성능을 보여준다. 모델 사이즈가 작을수록 initialization 전략들 간의 차이를 볼 수 있지만 모델 사이즈가 커질수록 그 차이는 없어진다.
class label initialization에서, class label이 학습된 prompt에 유지되어 가장 가까운(cosine) 토큰 임베딩이 초기화에 사용된 토큰과 일치하는 것을 확인할 수 있다.
Pre-training Objective
위 그래프의 c와 d를 보면 pre-training objective가 prompt tuning quality에 영향을 주는 것을 확인할 수 있다. 이 전에 가정한것 처럼, T5의 default "span corruption" objective는 prompt에 의해 조절되는 frozen model을 학습하는데 적합하지 않다. 직감적으로, sentinel token을 읽고 쓰도록 사전학습된 모델은 sentinel없이 읽고 쓰는 task에 직접적으로 적용하기 어렵다. c그림에서 볼수 있듯이, downstream task에 sentinel을 추가하는 "workaround"는 약간의 이점을 가진다. LM adaptation은 모든 모델에 추가하지만 XXL 모델이 가장 좋은 성능을 보여준다.
LM adaptation의 이점을 고려하여, adaptation의 기간이 얼마나 도움이 되는지 연구한다. d 그래프는 adaptation이 길어질수록 추가적인 이점이 있음을 보여준다. 이것은 span corruption로부터 LM modeling objective로의 전환이 쉽지 않으며 효과적인 전환은 추가적인 학습 리소스가 필요하는 것을 보여준다. 동시에 다른 ablations처럼 XXL 모델은 이상적인 objective가 아니여도 견고함을 보여준다. XXL 크기의 모델은 adaptation으로 얻는 이득은 상당히 적다.
최적이 아닌 span corruption에서 모델의 크기에 따라 불안정한 것을 확인할 수 있다. 확인해보니 다양한 task에서 중간 크기의 모델들은 적절한 class label output을 학습하지 않고 score는 0%인 것을 확인했다. 가장 흔한 오류 두 가지는 input으로 부터 subspans을 복제하는 것과 empty string을 예측하는 것이다. 게다가 성능 악화는 각 크기의 모델별로 3번의 실행에서 낮은 variance를 확인했기 때문에 prompt tuning의 random variance 때문이 아니다. 이런 결과들은 "span corruption"으로 사전학습한 모델을 사용하는 것은 신뢰할 수 없으며, 오직 5개의 모델 중 2개의 모델만 잘 작동하는 반면 LM adaptation은 모든 크기의 모델에서 안정적으로 작동하는 것을 나타낸다.
Comparison to Similar Approaches
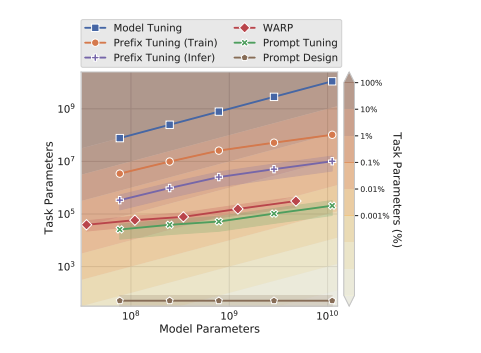
Prefix tuning
-
모든 Transformer layer에 prefix를 prepend하여 학습한다.
-
이 방법은 모든 네트워크의 고정된 transformer activations를 학습하는 것과 유사하다.
-
대조적으로, prompt tuning은 임베딩된 input에 prepend하는 하나의 prompt representation을 사용한다.
-
prompt tuning은 prefix tuning보다 더 적은 파라미터를 요구하는 것 외에도, input example에 의해 맥락에 맞는 intermediate-layer task representation을 업데이트할 수 있다.
-
prefix tuning은 GPT-2와 BART에서 연구되고 prompt tuning은 T5에서 수행하며 모델의 크기가 증가함에 따라 성능과 design의 선택에 따른 견고함을 연구한다.
-
prefix tuning은 BART의 encoder, decoder 둘다 prefix를 포함하는 반면 prompt tuning은 오직 encoder에 대한 prompt만 요구한다.
-
prefix tuning은 안정된 학습을 위해 prefix의 reparameterization 의존하며 이는 학습하는 동안 많은 수의 파라미터를 추가하는 반면 prompt tuning은 reparameterization을 요구하지 않으며 SuperGLUE task와 모델 크기에 관하여 강건하다.
WARP
-
WARP는 input layer에 추가되는 prompt parameter이다.
-
이 방법은 masked language models에서 [MASK] 토큰과 학습 가능한 출력 레이어에 의존하여 mask를 class logits으로 투영한다.
-
WARP는 모델이 하나의 출력을 생성하도록 모델을 제한하여 classfication으로 제한한다.
-
prompt tuning은 input에 어떠한 변화나 task-specific head를 요구하지 않는다.
-
prompt tuning의 성능도 model tuning의 강력한 성능과 비슷하다.
P-tuning
-
P-tuning은 human design 기반으로 한 패턴을 사용하여 임베딩 된 입력에 interleave할 수 있는 학습가능한 continuous prompt 기법이다.
-
prefix-tuning은 단순히 input에 prompt를 prepend하는 것으로 이런 복잡성을 제거한다.
-
P-tuning은 성능 향상을 위해 model tuning과 결합하여 사용되었고 그로 인해 model parameter와 prompt 둘다 업데이트 해야하는 반면 prompt-tuning은 LM 모델을 frozen하여 유지한다.
Soft words
-
사전학습 된 LM으로부터 지식을 추출하는 prompt를 학습하기 위해 사용된다.
-
prompt들은 수작업으로 설계된 prompt prototype에 기반하여 입력과 관련하여 배치되고 각 layer에 학습된 파라미터가 포함되기 때문에 비용은 모델의 depth에 따라 늘어난다.
Few-shot sequence learning with Transformers
-
다양한 tasks에 대해서 transformer 모델을 adapt하기 위해 학습가능한 prepend된 토큰을 사용한다.
-
하지만, 대규모의 real-world 데이터보다 compositional task representation을 수용할 수 있는 작은 synthetic 데이터에 초점을 둔다.
-
이 연구는 task representation과 같이 처음부터 학습된 small transformers를 사용하는 반면 prompt tuning은 base model을 frozen하여 유지하고 더 큰 transformer를 사용하여 scaling의 법칙을 조사한다.
Adapters
-
adapter는 사전학습된 frozen network layer 사이에 small bottleneck layer들을 삽입하는 방법이다.
-
adapter는 task-specific 파라미터를 줄이는 수단을 제공하고 Houlsby et al.(2019) 논문은 BERT-Large를 동결할때 GLUE에서 full model tuning과 근접한 성능을 도달했고 오직 2-4%의 파라미터만을 추가했다.
-
adapter와 prompt tuning의 가장 큰 차이점은 접근 방식이 모델의 행동 변경하는 방법이다.
-
adapter는 주어진 layer에서 활성화를 재사용하는것에 의해 신경망에 의해 parameterized된 input representation에 작용하는 실제 함수를 수정한다.
-
prompt tuning은 함수는 고정하고 후속의 입력이 처리되는 방법에 영향을 주는 새로운 input representation을 추가하여 모델의 행동을 수정한다.
Resilience to Domain Shift
중요 모델의 파라미터들을 freeze하는 것에 의해 prompt tuning은 일반적인 언어에 대한 이해를 수정하는 것을 막는다. 대신 prompt representations은 간적접으로 input의 representation을 조절한다. 이것은 모델이 특별한 어휘적 단서나 비논리적인 상관관계를 기억하여 데이터셋에 오버피팅하는 것을 줄인다.
이러한 제한은 prompt tuning가 학습과 평가 사이에 입력에 대한 분포가 다른 domain shifts에 대해 강건함을 향상시킬 수 있음을 암시한다.
question answering(QA)와 paraphrase detection 두 가지 task에서 zero-shot domain transfer에 대해 조사한다.
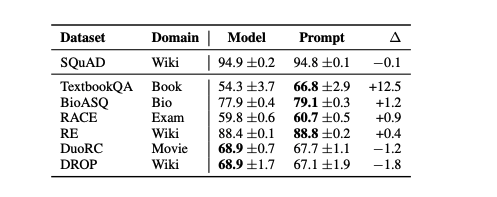
question answering을 위해 MRQA 2019를 사용한다. 이 task는 통합된 형태의 추출 QA 데이터를 수집하고 "in-damain" 데이터로 학습된 모델이 "out-of-domain" 데이터에 대해 평가될 때 얼마나 잘 작동하는지 테스트한다. 본 눈문에서는 SQuAD에 대해 학습하고 out-of-domain 데이터에 대해 평가한다. 위의 table은 prompt tuning이 대부분의 out-of-domain 데이터에서 model tuning을 능가하는 것을 보여주며 TextbookQA에서는 12.5 포인트의 차이가 나는 것을 보여준다.

두번째 domain shift 테스트를 위해 GLUE의 2 가지 paraphrase detection task에 대해 탐구한다. 첫 번째 task는 QQP로 커뮤니티 Q&A 사이트 Quora의 2개의 질문이 중복되는지 묻는다. 두 번째 task는 MRPC로, 뉴스 기사에서 추출한 두 문장이 paraphrase인지 묻는다. 여기서 QQP와 MRPC 사이의 transfer를 테스트한다. 위의 table은 QQP 데이터에 대해 lightweight를 학습하고 MRPC에 대해 평가하는 것이 전체 모델을 tuning하는것 보다 더 좋은 성능을 주는 것을 볼 수 있다. MRPC에서 학습하고 QQP에서 평가하는 것은 F1 점수가 떨어지는 것을 확인할 수 있다. 이런 결과는 model tuning이 더 over-parameterized되고 training task에 과적합 되고 다른 도메인에서 비슷한 task를 저하시킬 수 있는 관점을 뒷받침한다.
Prompt Ensembling
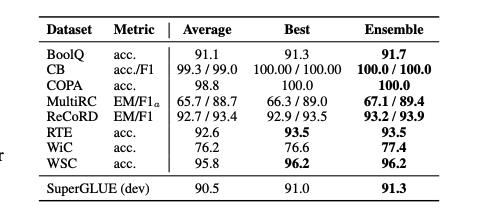
같은 데이터에 대해 다른 initialization으로 학습한 신경 모델의 앙상블은 광범위하게 성능 향상을 관찰할 수 있고 모델의 불확실성을 평가하는데 유용하다. 하지만 모델 크기가 증가함에 따라, 앙상블은 비현실적인 기법이 되었다. T5-XXL 모델 각각의 복제 모델이 45 GiB인것처럼 공간도 많이 필요할 뿐만 아니라, 병렬이든 직렬이든 N개의 모델의 추론 비용도 매우 상당하다.
Prompt tuning은 보다 효과적인 사전학습된 언어모델의 multiple adaptation 앙상블 방법을 제공한다. 같은 task의 N개의 promp를 학습함으로, task에 맞는 N개의 분리된 model 생성할 수 있고 중요 언어모델 파라미터는 전체적으로 공유할 수 있다. 저장 비용이 급격히 줄어드는 것 이상으로, prompt 앙상블은 추론을 보다 효과적으로 할 수 있게 한다. 하나의 예시로, N개의 다른 모델의 forward를 계산하는것 보다, N개의 batch size로 하나의 forward를 실행할 수 있고 batch 전체에 예제를 복제하고 prompt를 다르게할 수 있다.
prompt 앙상블의 실행 가능성을 증명하기 위해, default hyperparameter의 하나의 frozen T5-XXL 모델을 사용하여 SuperGLUE task 각각에서 5가지 prompt를 학습한다. 앙상블의 예측을 계산하기 위해 간단한 majority voting을 사용한다. 위의 table은 모든 테스크에서 앙상블이 하나의 prompt average 보다 성능이 좋은 것을 보여주고 best prompt와도 비슷하거나 좋은 것을 볼 수 있다.
Interpretability
이상적으로 설명 가능한 prompt는 작업을 명확하게 묘사하고 모델에게 결과나 행동을 명시적으로 요청하며 prompt가 모델로부터 행동을 이끌어 내기 위한 이유를 쉽게 이해할 수 있는 자연어로 구성된다.
prompt tuning은 discrete token space보다 continuous embedding space에서 연구되어 prompts를 설명하는 것은 더욱 어렵다. 학습된 soft prompt의 interpretability를 테스트하기 위해, frozen 모델의 vocabulary로부터 각각의 prompt token의 가장 인접한 이웃을 계산한다. 이때 vocabulary embedding vector와 prompt token representation 사이의 cosine distance를 metric으로 사용한다.
주어진 학습된 prompt token에 대하여 가장 가까운 이웃 상위 5개가 밀접한 클러스터를 형성하는 것을 관찰했다. 예를 들어, Technology, technology, Technologies, technological, technologies와 같이 어휘적으로 비슷한 클러스터 뿐만 아니라 entirely, completely, totally, altogether, 100% 처럼 다양하지만 연관성이 있는 클러스터를 확인할 수 있다. 이런 클러스터들의 성질은 사실 prompt가 "word-like" representation을 학습한다는 것을 암시한다. embedding space에서 추출한 random vector들은 이런 종류의 의미론적 클러스터를 보여주지 않는 것을 발견했다.
"class label" 전략을 사용하여 prompt를 초기화 할때, 종종 class label이 학습을 통해 지속되는 것을 발견한다. 특히, prompt token이 주어진 label로 초기화된다면 label은 tuning 후 학습된 token의 가장 인접한 이웃이 되는 경우가 많다. "random uniform" 또는 "sampled vocabulary" 방법으로 initialization 할때, class label 또한 prompt의 가장 가까운 이웃에서 발견할 수 있지만 multiple prompt tokens의 이웃으로 나타나는 경향이 있다. 이것은 모델이 예상된 output class를 참고용으로 저장하는 것을 학습하고 prompt를 output class에 초기화하는 것은 더 쉽고 집중화할 수 있음을 보여준다.
긴 prompt를 연구할 때, 종종 동일한 가까운 이웃을 가진 prompt token을 발견할 수 있다. 이는 prompt의 용량이 초과되거나 prompt representation에서 sequential 구조가 부족하여 모델이 특정 위치로 정보를 집약하기 어렵게 만든다.
sequences로 학습된 prompt는 interpretability가 거의 나타나지 않지만, BoolQ에 대해 학습된 prompt의 가장 가까운 이웃으로 과학, 기술, 엔지니어링과 같은 단어가 가장 빈도가 높고 거의 질문의 20%가 "Nature/Science" 범주안에 있다. 더 많은 조사가 필요하지만, 이것은 prompt의 한 가지 역할이 모델이 특정 domain 또는 context(e.g. "scientific")의 입력을 해석하도록 prime 하는 것임을 암시한다.
Conclusion
본 논문에서, downstream task에서 frozen pre-trained language model을 adapting하는 효과적인 기술인 prompt tuning을 소개했다. 모델 크기가 커짐에 따라 SuperGLUE에서 기존의 model tuning과 차이가 없음을 보여줬다. zero-shot domain transfer에 대해 prompt tuning이 일반화 성능을 높이는 것을 이끄는 것을 발견했다. 이는 주요 모델 파라미터를 freeze하고 downstream에서 lightweight 파라미터로 제한하는 것이 특정 도메인에 대한 오버피팅을 피하는 것에 도움을 주는 것을 나타낸다.
저장 및 서빙 비용 측면에서 frozen 사전학습 모델로 전환에 대한 매력에 대해 논의했다. 이는 효율적인 multi-task serving 뿐만 아니라 높은 성능의 prompt 앙상블을 할 수 있게 했다.
