논문 : Training language models to follow instructions with human feedback
Background
-
RL(Reinforcement Learning) : 현재 상태(state)에서 취하는 행동(action)에 따라 특정 보상(reward)를 통해 학습하는 기법
-
RLHF(Reinforcement Leaerning Human Feedback) : 사람들의 선호도 데이터를 통한 보상 모델링 및 강화 학습
-
Alignment : 모델을 사용자의 의도에 맞도록 조정하는 것
Problem state
-
LM은 User의 프롬프트에 대한 응답으로 사실을 꾸며내거나 편향적이거나 악성 텍스트를 생성하거나 의도하지 않은 행동을 하는 경우가 많음
-
보통 LM을 학습시킬 때 사용하는 objective(다음 토큰 예측)이 유용하고 안전하게 User의 의도를 따르라는 목적과는 다르기 때문에 일어나는 현상임. 즉 misaligned 하다고 볼 수 있음
Contribution
-
지시사항을 따르는 명시적인 의도와 편향이나 유해하지 않고 진실을 유지하는 암묵적 의도를 포함하여 alignment
-
misaligned문제를 해결 하기 위한 RLHF 방법을 적용한 InstructGPT 제시
Method
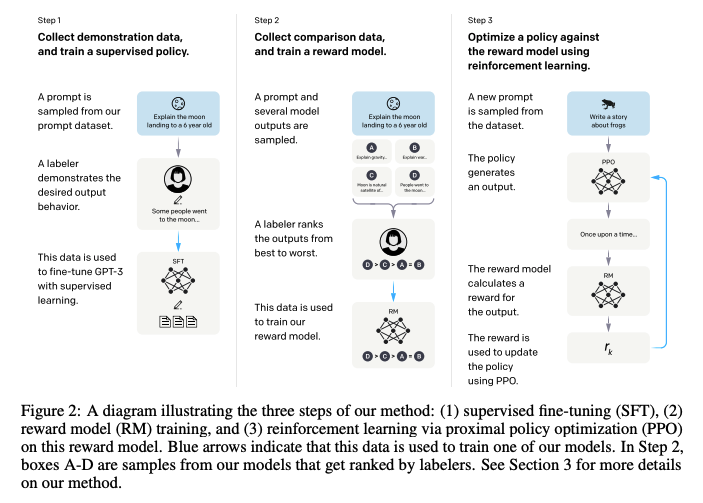
Step 1: Collect demonstration data, and train a supervised policy
-
demonstration data : (prompts : labeler, API로 약 13K / response : labeler 작성)
-
SFT (Supervised fine-tuning) 수행 : GPT-3 모델을 16 epoch 학습
Step 2: Collect comparison data, and train a reward model
-
comparison data : (prompts : labeler, API로 약 33K / 4-9개의 response 결과물에 labeler가 직접 선호도 순위를 매김)
-
SFT model로 부터 response를 얻고 labeler가 직접 선호도(scalar)를 작성하여 Reward Model(RM) 학습
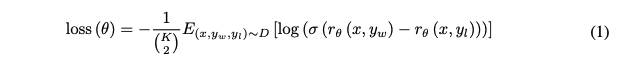
-
입력은 2개의 response 쌍으로 구성되어 있기 때문에 prompt 당 의 comparisons 생성
-
overfit 방지를 위해 모든 조합의 comparisons을 하나의 batch로 다룸
-
위의 lossdptj 는 RM의 scalar output, 는 더 선호되는 응답, 반면에 는 덜 선호되는 응답, 는 human comparisons의 dataset
-
RL(Reinforcement learning)을 하기 전, 평균 score가 0을 달 성할 수 있도록 bias를 이용하여 정규화를 진행함
Step 3: Optimize a policy against the reward model using PPO
-
prompts : only API로 약 31K
-
KL penalty를 추가하여 RM의 over-optimization을 완화
-
RM을 value function으로 함
-
pretraining gradient와 PPO gradient를 섞는 PPO-ptx 모델 제안
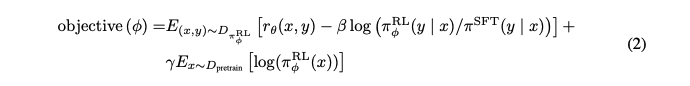
-
보상을 최대화 하도록 학습이 진행되며, 초기 policy는 사전학습 시 사용한 데이터 10%와 demonstration 데이터를 사용하여 supervised fine-tuning 진행
-
는 RL policy, 는 step 1의 모델, 은 pretraining distribution
-
는 KL reward coefficient, 는 pretraining loss coefficient로 KL penalty와 pretraining gradients를 제어
-
PPO models는 를 0으로 세팅하며 본 논문에서는 PPO-ptx 모델을 주로 다룸
Results
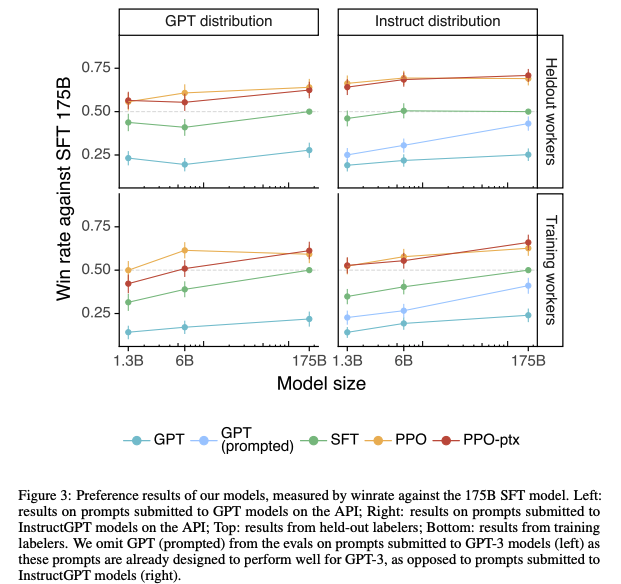
-
Labeler들은 GPT-3보다 InstructGPT를 더 선호함 (Heldout workers : 학습 데이터 생성에 참여하지 않음)
-
175B GPT보다 1.3B InstructGPT가 훨씬 선호도가 높음
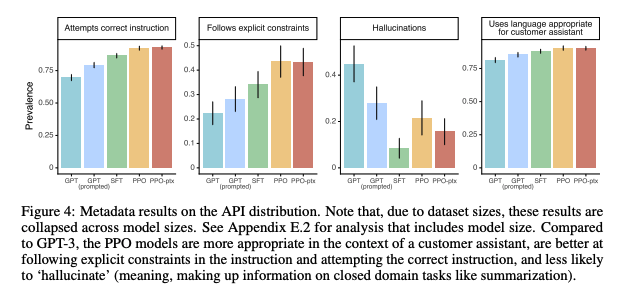
- 응답의 정확성, 통제를 잘 따르는 정도, 환각 증상, 사용자를 위한 적절한 언어 사용 등의 지표에서도 대부분 InstructGPT가 높은 지표를 보여주고 있음
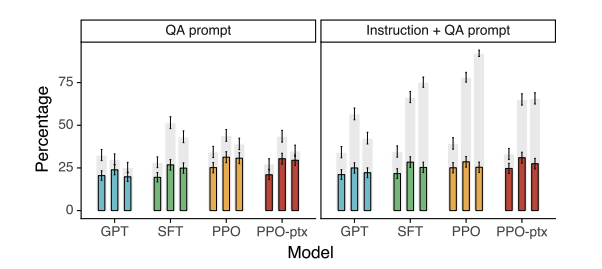
- TruthfulQA dataset으로 정직성을 평가한 결과에서도 개선된 지표를 보여줌.
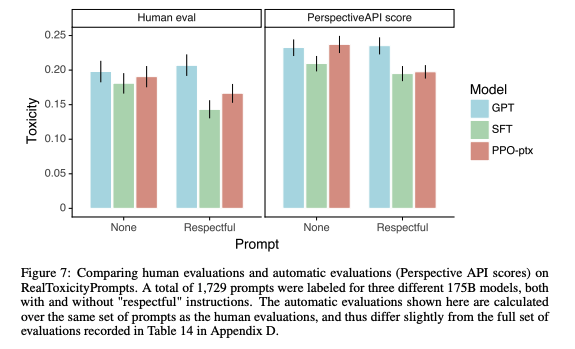
- RealToxicityPrompts dataset으로 평가를 진행하였으며, Respectful하게 답변하라는 prompt를 제공할 시 GPT-3보다 더 좋은 성능을 보여줌

- 학습 과정에서 거의 보지 못한 지시사항에도 응답을 잘함. 이는 "following instructions"의 개념을 인지하는 것으로 해석 가능
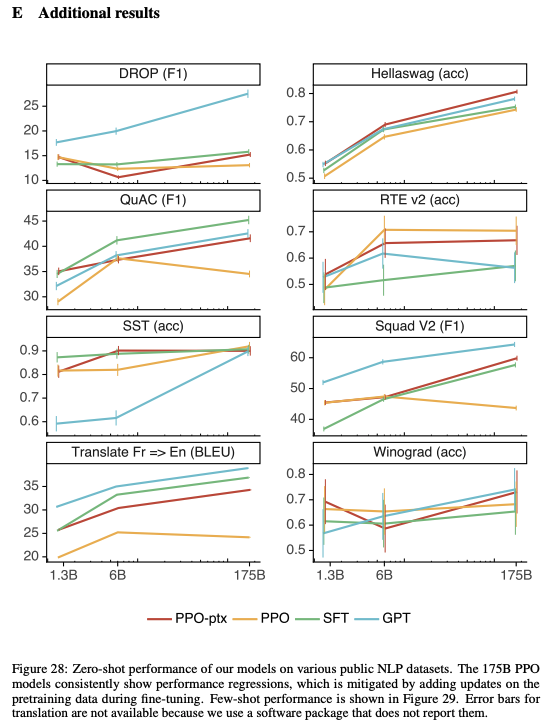
- 추가적인 결과로 보았을 때, GPT-3보다 낮은 성능을 보여주는 task들이 존재하며 이를 한계점으로 볼 수 있음
Conclusion
-
훗날 chatGPT의 전신이 되는 모델링 기법인 강화학습을 통해 GPT-3를 넘어선 InstructGPT를 소개함
-
하지만 데이터셋을 구축하는 labeler들이 모든 사람들을 대변할 수 없음
-
결과를 보더라도 성능이 뛰어난 것을 알 수 있지만, InstructGPT도 여전히 사용자 의도를 따르지 않거나 유해한 결과물을 응답하거나 간단한 질문에도 장황하게 답변을 하거나 실수를 하는 등의 한계가 있음
