캐시 미스
캐시 정책에서 쓰일 개념들이라 잠깐 짚고 넘어가자
CPU가 필요한 데이터가 생겨서 이를 찾으려고 할 때 DRAM에 가기 전에 캐시 메모리에서 해당 데이터가 있는지를 먼저 확인하는데, 만약 캐시 메모리에 해당 데이터가 있다면 캐시 히트, 없다면 캐시 미스라고 한다!
캐시 미스의 종류
- Compulsory miss(또는 cold miss): 해당 메모리 주소를 처음 불렀기 때문에 나는 미스. 예를 들어 프로그램을 새로 켜거나 하는 경우 발생한다.
- Conflict miss: 캐시 메모리에 A 데이터와 B 데이터를 저장해야 하는데, A와 B가 같은 캐시 메모리 주소에 할당되어서 나는 캐시 미스다. 하나의 캐시 메모리에 둘 이상의 메인 메모리 주소와 그 데이터가 들어갔다면 충돌하지 않겠는가
- Capacity miss: 캐시 메모리에 공간이 부족해서 나는 캐시 미스. 위의 conflict miss는 캐시에 공간이 남아도는데도 불구하고 주소 할당 때문에 나는 미스지만, capacity miss는 주소 할당이 잘 되어있더라도 공간이 부족하면 나는 미스다. 캐시 공간이 작아서 벌어지는 일이므로 캐시 크기를 키우면 해결되지만, 캐시 크기를 키우면 캐시 접근속도가 느려지고 파워를 많이 먹는다는 단점이 생긴다. 게다가 비싸다... cash 메모리인가
캐시 배치 정책
Direct Mapped Cache
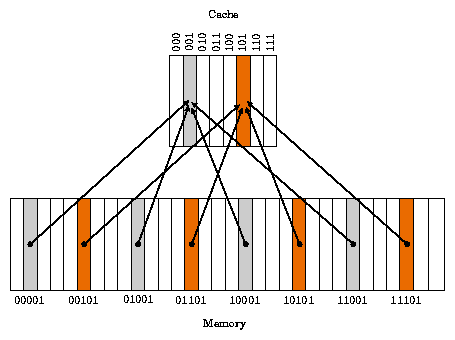
구성
- 가장 기본적인 캐시 배치 정책이다.
- DRAM의 여러 주소가 캐시 메모리의 한 주소에 대응되는 n:1 방식이다
- 그림에서 메모리의 공간은 32개(00000~11111),
캐시 메모리의 공간은 8개(000~111)이기에
32:8 = 4:1 --> 캐시 메모리 한 주소당 DRAM 4 주소에 대응된다 - 00001, 01001, 10001, 11001 --> 001
- 여기서 끝에 001은 공통적으로 들어 있다!
- Index Field: 001
- Tag Field: 00, 01, 10, 11
- Tag와 Index Field 뒤에 데이터를 저장하는 Data Field가 있다
작동 방식
- 캐시 메모리는 비워져 있고 CPU가 메인 메모리의 00001 주소의 데이터를 두 번 연속해서 읽는 상황
- CPU는 먼저 캐시 메모리의 주소 001인 곳에 데이터가 있는지 확인한다
당연히 캐시 메모리가 비워져있으니 캐시 미스 발생(Compulsory miss) - 직접 메인 메모리의 00001 주소를 참조해서 데이터를 읽는다
- 다시 사용될 수 있으므로 캐시 메모리의 001 주소에 00 Tag Bit와 메인메모리의 00001에 해당하는 데이터를 저장한다
- 두번째로 CPU가 메인 메모리의 00001 주소의 데이터를 읽으려고 한다
- 또 캐시 메모리의 주소 001인 곳에 데이터가 있는지 확인한다
- 첫번째 접근했을 때 캐시 메모리에 데이터를 저장했기에 데이터가 들어있다
- 데이터가 CPU가 요구하는 주소의 데이터와 일치하는지 태그 비트 비교 검사를 한다
- 일치한다면 캐시 메모리에서 데이터를 가져와서 읽는다
단점
- Conflict Miss: 캐시 메모리의 동일한 주소에 여러 메인메모리 주소의 데이터가 할당되어서 충돌이 발생하는 경우
ex) 저 그림에서 회색, 00001과 01001 주소의 데이터를 동시에 읽어야 하는 상황에서 충돌한다
Fully Associative Cache
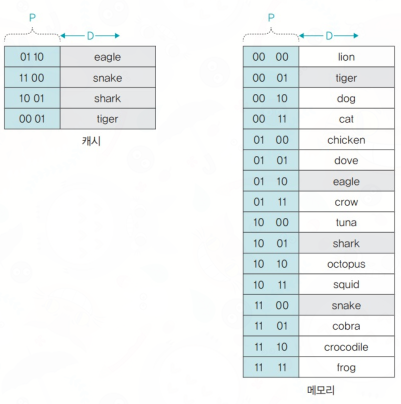
"캐시 메모리 001호 방 비었나요? 순서요? 모르겠고 드갑니다잉~"
: 캐시 메모리의 주소 중 비어있는 곳에 주기억장치의 데이터를 할당한다
장점
- 저장 간단
- 순서, 조건 없음
- 적중률 높음(Direct Mapping과 다르게 Conflict Miss가 나지 않는다)
단점
- 원하는 데이터를 찾을 때 모든 라인을 뒤지며 tag bit를 비교해야 한다
-> 시간 오래 걸림 - 빠른 검색을 위해서 복잡한 회로가 필요하다
CAM(Content Addressable Memory) - 비쌈;;
Set Associative Cache

앞에서 본 두 방식 모두 장단점이 있네
베스트는 뭐다?
하이브리드! 짬짜면!
절충안! 인싸! 대세!
Direct Mapping + Fully Associative Mapping
: 특정 행을 지정해서 그 행 안에 열이 비어있으면 저장하는 방식
장단점
- Direct Mapping 대비 검색은 느리지만 저장 빠름
- Associative Mapping 대비 저장 느리지만 검색 빠름
- 최근 CPU의 캐시 메모리에서 사용됨
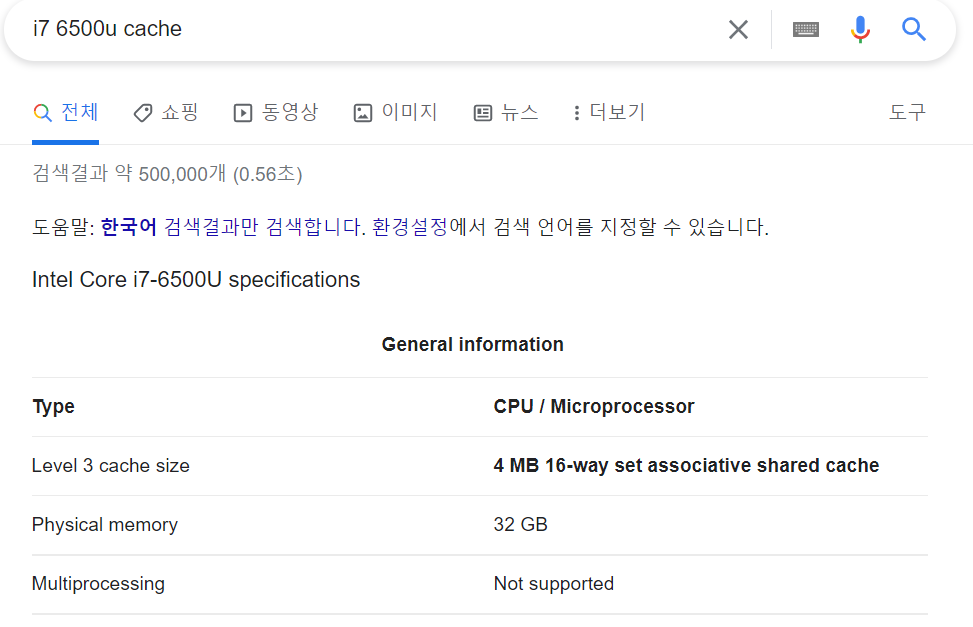
내 labtop cpu 사양이다. 검색하면 캐시의 배치 정책이 무엇인지 확인할 수 있다. 최근 cpu는 대체로 요녀석을 쓴다
캐시 쓰기 정책
정책 내용
리눅스 등에서 파일에 대한 정보를 보거나 파이썬, 자바, C언어 등의 프로그래밍 언어에서 파일 입출력을 다룰 때에 파일의 권한을 살펴보면 쓰기 권한과 읽기 권한이 있다.
읽기 권한은 말 그대로 파일을 읽기만 할 수 있는 권한으로 일반 유저들도 접근할 수 있는 영역이다. 그러나 쓰기 권한은 중요한 파일의 경우 대체로 관리자만 가진다. 값이나 데이터를 변경할 수 있는 권한이다.
여기서의 쓰기 정책 역시 데이터를 CPU가 사용하며 메모리에 접근하는 경우에 대한 내용이다.
- CPU가 데이터를 찾을 때 캐시 메모리를 먼저 확인한다
- 캐시 메모리에 데이터가 있다면 이에 접근하여 캐시 메모리 값을 변경한다
- 이 경우 캐시 메모리는 임시적인 메모리이므로 그 근원인 메인 메모리의 값도 변경되어야 한다
캐시 쓰기 정책은 "언제 메인 메모리의 값을 변경"할거냐 에 대한 정책이다!
-
캐시 Hit 시 쓰기 정책: Write Through, Write Back
-
캐시 Miss시 캐시 쓰기 정책: Write-Allocate, No Write-Allocate
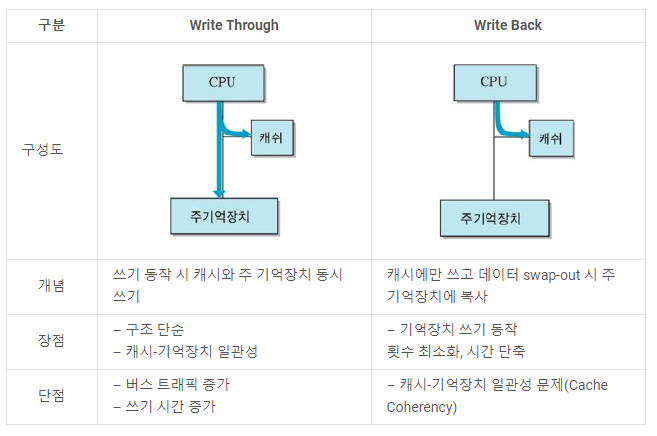
Write Through
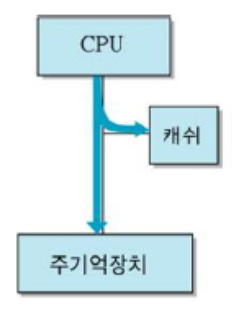
- 부지런한 개미!
- 쓰기 동작 시 캐시와 주 기억장치의 메모리 값 동시에 변경
장점
구조 단순, 캐시와 기억장치 일관성
단점
항상 메인 메모리에 접근해야 함 - 속도 감소, 시간 오래 걸림
--> 캐시의 이점 감소
Write Back
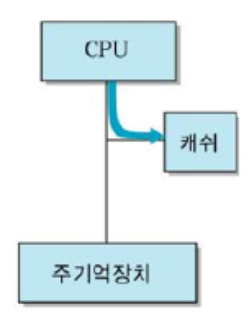
- 게으름, 효율 끝판왕 베짱이!
- 캐시에서만 메모리 값 변경하고 변경한다는 표시를 한다
- 이후 해당 주소의 데이터가 바뀔 때에만 메인 메모리에 복사한다
비유하자면 Write Through는 교실에 휴대폰 수거함이 열리는 즉시 휴대폰을 반납하는 학생, Write Back은 휴대폰 수거함이 열려도 선생님이 반납하라고 말하기 전까지는 하지 않는 학생
장점
기억장치 쓰기 동작 횟수 최소화 --> 시간 단축
단점
캐시-기억장치 일관성 문제
Write-Allocate, No Write-Allocate
-
Write-Allocate: 캐시 Miss 발생 시 캐시에만 기록
-
No Write-Allocate: 캐시 Miss 발생시 메모리에만 기록
- 하나에만 기록하여 효율적
캐시 교체 정책
정책 내용
- 캐시 메모리는 매우 제한적이고 유한하다
--> 효율적 사용이 중요하다 - 빠른 연산을 위해서는
"어떤 정보를 오래 저장할거냐"에 대한 알고리즘이다 - 캐시 메모리보다 넓은 범주로 "페이지 교체 알고리즘"이 있다
정보처리기사나 각종 코딩테스트에서도 등장하는 녀석~ - Direct Mapping에서는 저장위치가 지정되기 때문에 필요X
LRU(Least Recently Used)
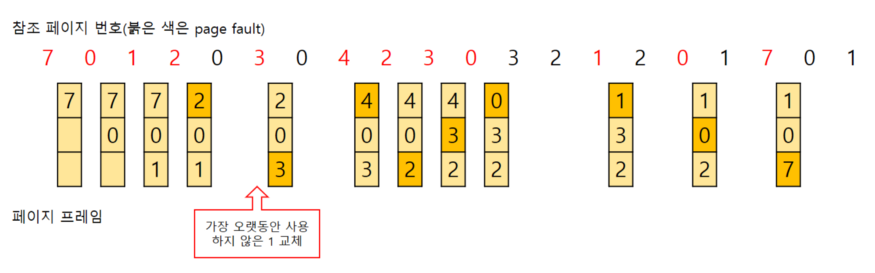
캐시 메모리에서 가장 오랫동안 사용하지 않은 데이터 순으로 제거하는 알고리즘
- 오랫동안 안썼다? --> 앞으로도 그러겠지~
- 구현이 간단하고 가장 보편적인 방식이다!
구현 방식
- 캐시에 저장된 데이터가 언제 사용됐는지 알 수 있도록 타임 스탬프를 사용
- 시간 느려짐, 오버헤드 발생
- Doubly Linked List 사용 - 데이터는 tail로 추가되기에 head에 가까울수록 least recently used data이다
- head의 캐시 지우고 tail에 추가하는 방식 - 시간복잡도: O(1)
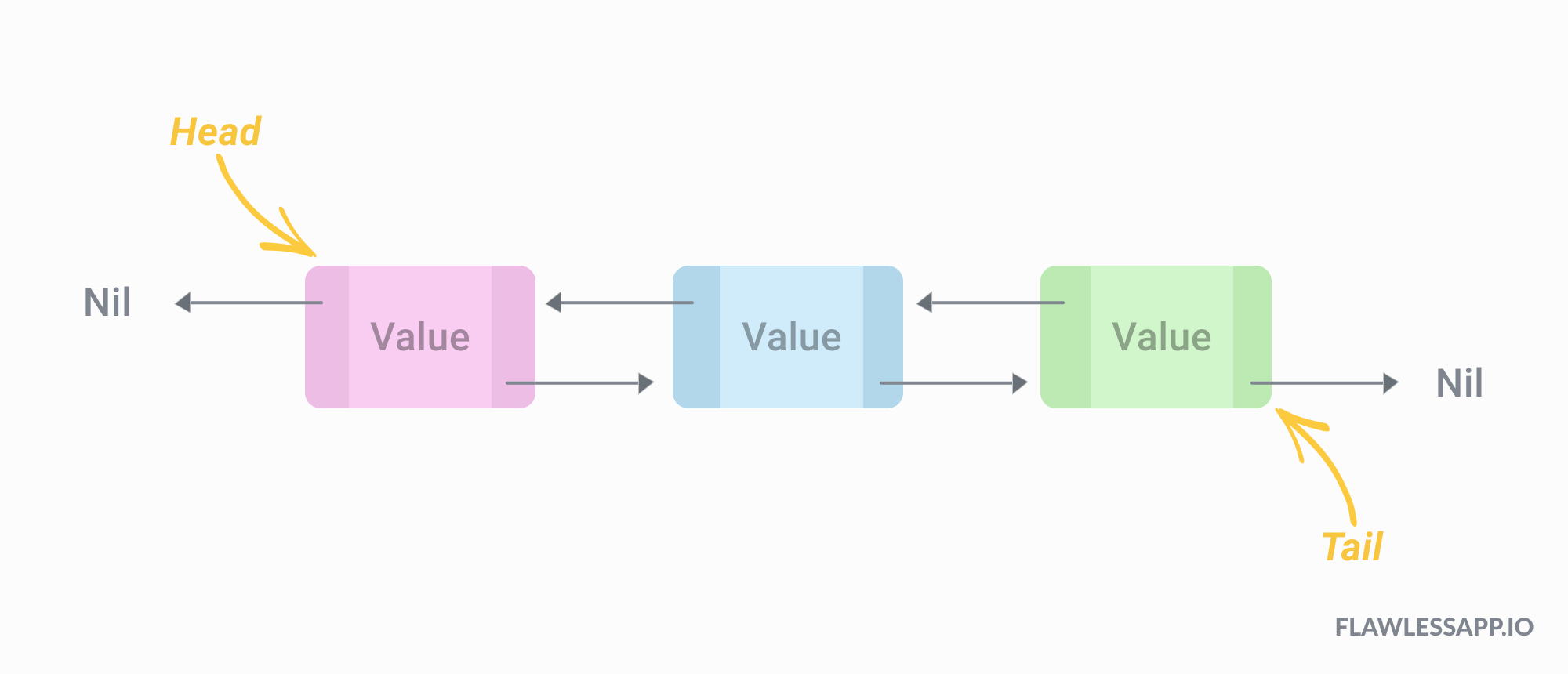
- head의 캐시 지우고 tail에 추가하는 방식 - 시간복잡도: O(1)
LFU(Least Frequently Used)
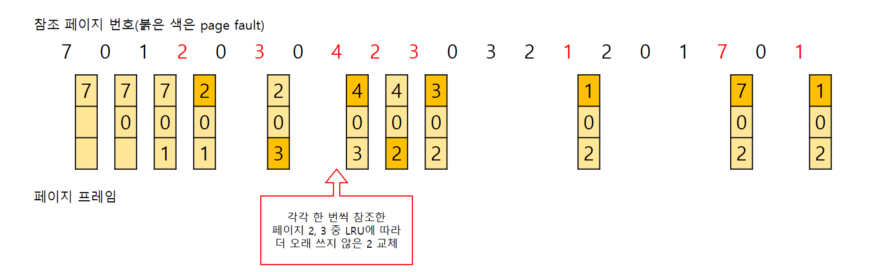
사용 횟수가 가장 적은 데이터부터 교체한다
- 교체 대상이 여럿이면 LRU 알고리즘에 따른다
단점
- 최근 적재된 데이터가 교체될 수도 있다
- 초반에 집중적으로 쓰이고 이후 안쓰인 데이터가 잔존해 메모리 낭비 가능성
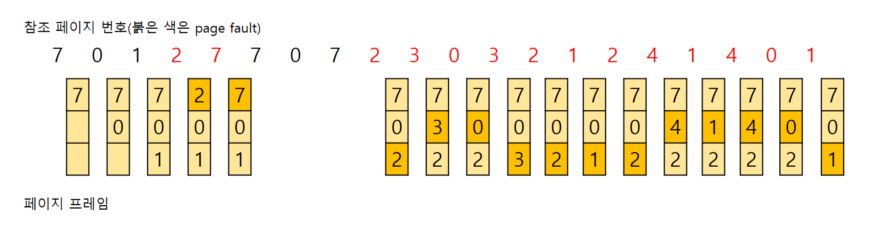
위의 예시에서 7이 초반에는 많이 쓰였지만 이후에는 거의 안쓰이면서 메모리에 남아있어서 비효율적이게 된다
FIFO(First in First out)
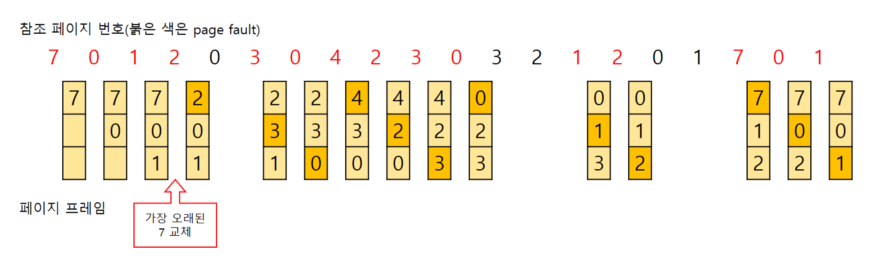
- FIFO? --> Queue!!!
- 메모리에 올라온 가장 오래된 데이터를 교체한다
- 이해 쉽고 구현 간단!
단점
- 잦은 교체의 가능성
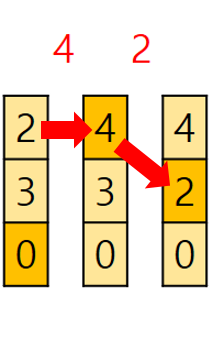
FIFO 그림에서 중간 부분을 확대해보면 2->4 이후에 2가 다시 등장한다. 이처럼 잦은 교체가 발생해서 부재율을 높이고 실행속도를 떨어뜨릴 가능성이 있다
마무리
지금까지 캐시 메모리에서 주 기억장치의 메모리 주소를 배치하고 데이터를 변경하고 교체하는 데에 있어서 효율적으로 처리할 수 있는 다양한 정책(알고리즘)을 살펴보았다. 이밖에도 많은 정책들이 있는데, 이는 CPU가 빠르고 효울적으로 작업하기 위해서 매우 중요한 방법들이다. 또한 특히 교체 알고리즘의 경우는 캐시에만 국한되지 않은 페이지 교체 알고리즘으로 자격증 시험이나 코딩테스트에도 나오는 유형이기에 집중해서 이해했으면 한다. 이상!
출처
