언어 모델을 사용한 문장 생성
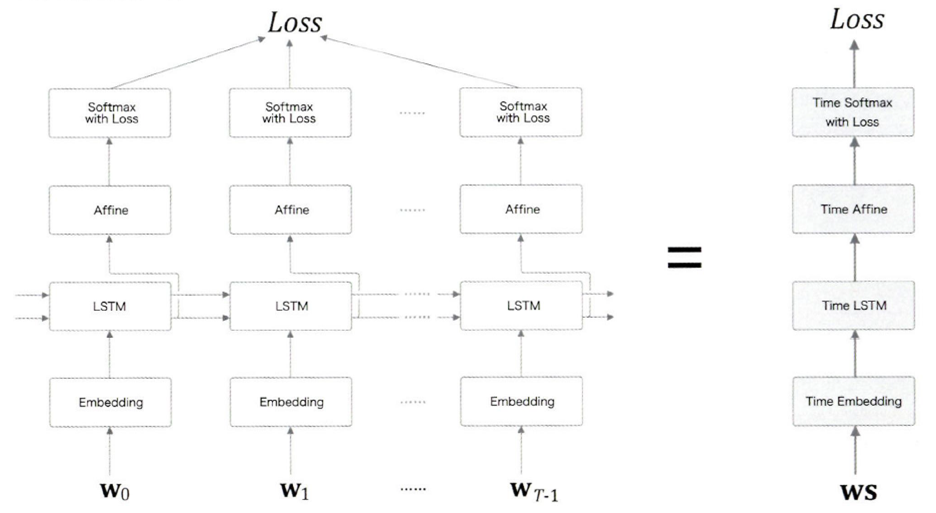
T개의 시계열 데이터를 한번에 처리하는 계층
- Time Embedding 계층: 단어 ID를 단어의 분산 표현으로 변환
- Time LSTM 계층: RNN과 다르게 c(기억 셀)가 있음 - LSTM 계층에서만 사용, 게이트가 추가됨(output, forget, input, 기억셀 추가(게이트 아님))
- Time Affine 계층: LSTM을 거친 은닉 상태가 입력됨
- Time Softmax 계층: 확률분포를 출력
"You say goodbye and I say hello"로 학습 후 I 입력시
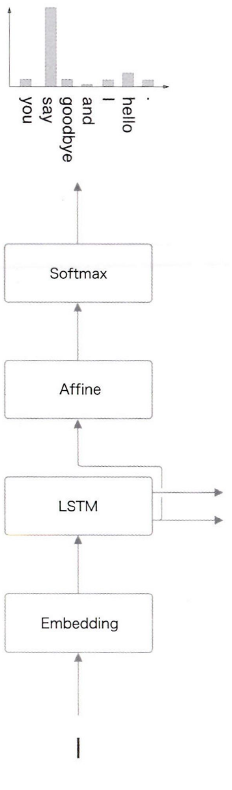
이처럼 Softmax 계층에서 I 다음에 올 단어로 적합한 것을 확률 분포로 출력한다.
문장을 생성하는 모델을 만든다는 것은 다음 단어로 적합한 것을 고르고, 그 단어를 다시 언어 모델에 입력하여 또 적합한 단어를 출력받고 이 과정을 반복하는 과정이다.
- 확률적 선택
Softmax에서 출력되는 확률 분포에 따른 확률적 선택
매 실행마다 생성되는 문장이 달라질 수 있다 - 결정적 선택
확률 분포에서 제일 높은 확률의 단어 선택
매 실행마다 같은 문장이 생성된다
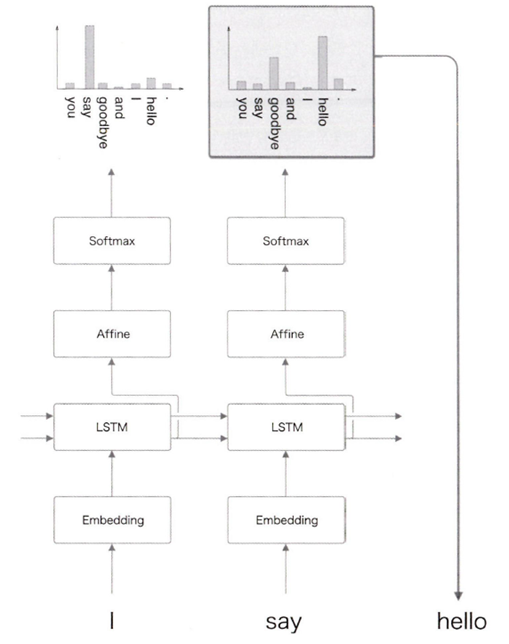
이 과정을 반복한다
원하는 횟수만큼 또는 종결기호 \<eos> 등을 만날 때까지.
- 의의: 생성된 문장은 기존 문장이 아닌 새로 생성된 문장이다. 훈련 데이터를 암기한 것이 아니라 훈련 데이터의 단어 정렬 패턴, 규칙을 학습했기에.
여기서는 한 문장을 학습했기에 그저 단어들의 순서나 개수가 바뀌었다고 생각할 수 있지만 더 큰 말뭉치를 학습할 경우 더 풍부한 표현과 문장이 나올 수 있다
class RnnlmGen(Rnnlm): # Rnnlm 클래스 상속
# generate: 문장 생성을 수행하는 메서드
def generate(self, start_id, skip_ids=None, sample_size = 100):
word_ids = [start_id]
x = start_id
while(len(word_ids) < sample_size):
x = np.array(x).reshape(1, 1) # x는 이차원 배열(predict가 미니배치 처리를 해서)
score = self.predict(x) # 전처리 이전
p = softmax(score.flatten())
sampled = np.random.choice(len(p), size=1, p=p) # 확률 고려하여 단어 선택
# 네거티브 샘플링
if(skip_ids is None) or (sampled not in skip_ids):
# <unk>, N 등 전처리된 단어 샘플링하지 않도록
# <unk>: 희소한 단어 N: 숫자 <eos>: 문장 구분 기호
x = sampled
word_ids.append(int(x))
return word_ids
위와 같이 ch.5에서 만들었던 Rnnlm 클래스를 상속하여 언어 생성 클래스를 만들었다.
이 때 'you'를 start word로 입력했을 때 어떤 문장들이 나올지 살펴보자
from dataset import ptb
corpus, word_to_id, id_to_word = ptb.load_data('train')
vocab_size = len(word_to_id)
corpus_size = len(corpus)
model = RnnlmGen()
#model.load_params('ch06/Rnnlm.pkl')
#시작 문자, skip 문자 설정
start_word = 'you'
start_id = word_to_id[start_word]
skip_words = ['N', '<unk>', '$']
skip_ids = [word_to_id[w] for w in skip_words]
# 문장 생성
word_ids = model.generate(start_id, skip_ids)
txt = ' '.join([id_to_word[i] for i in word_ids])
# join: 리스트의 단어들 합쳐줌
txt = txt.replace(' <eos>', '.\n')
# 종결 기호를 .\n으로 바꾸어줌
print(txt)
param 주석을 해제하면 학습으로 설정된 가중치를 반영했을 때로 문장이 생성되는데, 이 때가 비교해보면 좀 더 문장이 매끄럽고 자연스럽다
you suspect because of a fund that was slowing to the pace of a smaller pay loans.
former richard w. really to hastily door to a major man 's cast came a hat of the first time.
this are widely even complex of half the national intelligence committee are times by the new york judge once out.
it was considering out said in a tower meeting.
mr. bush is n't the aides said.
he warned that he was too convinced.
in the judge was u.s. activities as stability fees through this year was demanded
이런 문장들이 나왔다
이번에는 ch.6에서 만든 BetterRnnlm을 사용해서 문장을 생성해보자
class BetterRnnlmGen(BetterRnnlm): # BetterRnnlm 클래스 상속
# generate: 문장 생성을 수행하는 메서드
def generate(self, start_id, skip_ids=None, sample_size = 100):
word_ids = [start_id]
x = start_id
while(len(word_ids) < sample_size):
x = np.array(x).reshape(1, 1) # x는 이차원 배열(predict가 미니배치 처리를 해서)
score = self.predict(x) # 전처리 이전
p = softmax(score.flatten())
sampled = np.random.choice(len(p), size=1, p=p) # 확률 고려하여 단어 선택
# 네거티브 샘플링
if(skip_ids is None) or (sampled not in skip_ids):
# <unk>, N 등 전처리된 단어 샘플링하지 않도록
# <unk>: 희소한 단어 N: 숫자 <eos>: 문장 구분 기호
x = sampled
word_ids.append(int(x))
return word_idsyou like to consider new york and reporters care in the problem.
mr. roman said the fate mr. pediatric says i remember much of those loans about one of the local interbank required even again.
mr. bergsma sent down slightly to a jury he took over the committee and will meet its warning to a criminal contract.
but mr. honecker has about taxes.
mr. stone the top meeting mr. stone played the secretary of mr. freeman.
in his reputation game mr. senator already is entering individual and the potential of mr. krenz 's chair.
첫 문장에서도 s+V and s+v 형태로 완벽한 문장이 나왔다. 좀 더 매끄러운 느낌이다.


the meaining of life is 뒤에 출력되도록 했을 때 나온 내용 중 마음에 드는 것을 가져와보았다.
7.2 seq2seq
시계열 데이터를 다른 시계열 데이터로 변환하는 문제를 살펴보자.
예를 들면 기계 번역, 음성 인식, 챗봇 등이 있다. 기계 번역의 경우 자연어 문장이 들어오면 이를 해석해서 다른 언어의 자연어 문장으로 바꾸어야 하기에 시계열 데이터를 시계열 데이터로 바꾸는 과정이다.
seq2seq: RNN 2개를 사용하는 Encoder-Decoder 모델이다
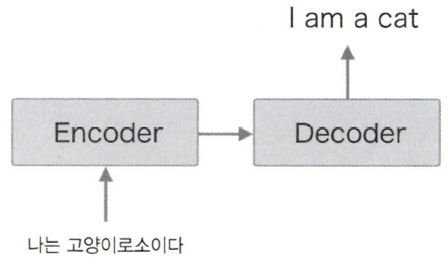
Encoder, Decoder에 RNN을 사용한다!
Encoder
Encoding: 부호화 - 정보를 특정 규칙에 따라 변환
ex) 'A' -> 1000001
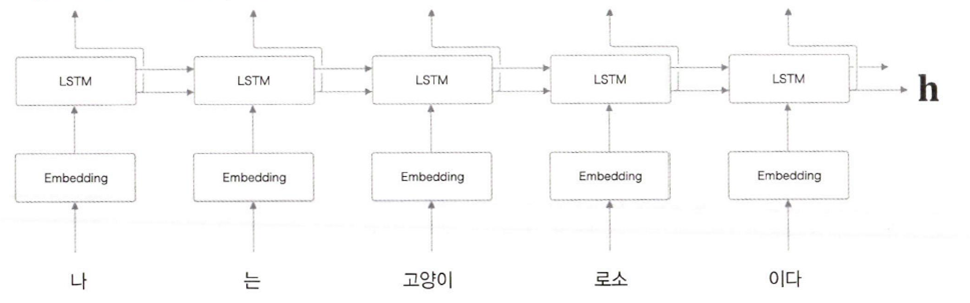
이 그림에서 Encoder은 LSTM계층을 통해 h(은닉 상태 벡터)를 반환하는데, 여기에 입력된 문장을 번역하고 변환하는 데에 필요한 정보가 인코딩된 것이다
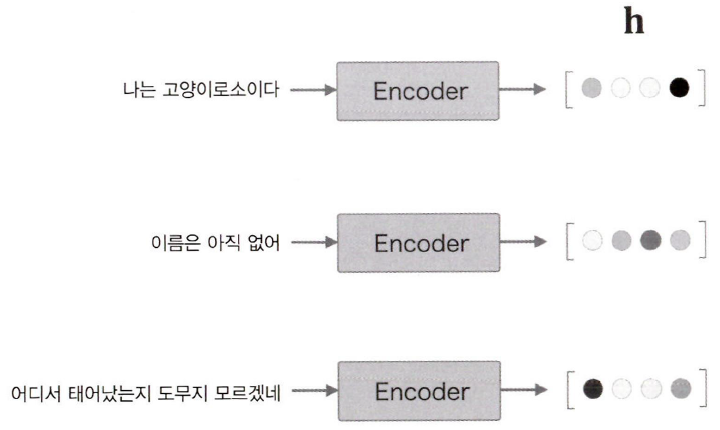
이 그림에서 볼 수 있듯이 h는 고정 길이 벡터이다. 따라서 입력 문장의 길이가 달라도 동일한 길이의 h가 출력된다.
Decoder
decoding: 복호화 - 인코딩된 정보를 원래 정보로 변환
ex) 1000001 -> 'A'
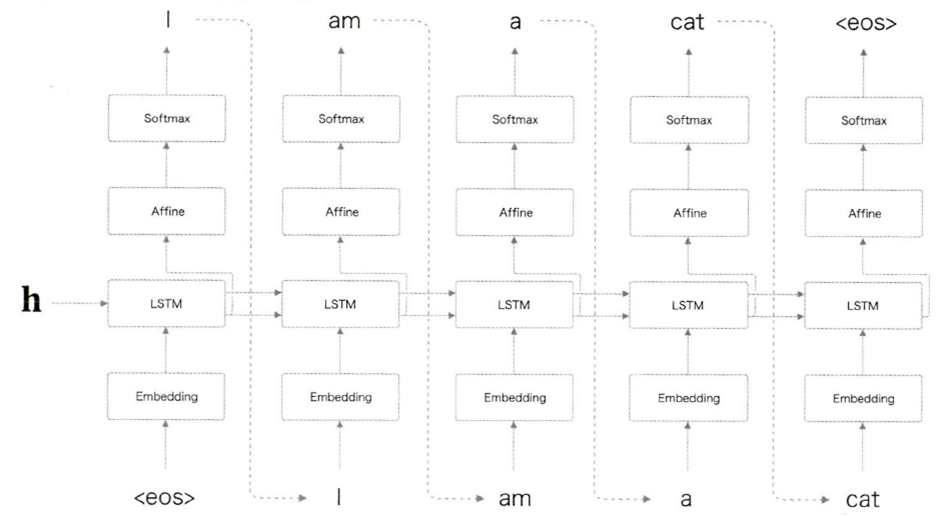
굉장히 형태가 익숙한데, 앞에서 다룬 문장 생성 모델과 유사하기 때문.
처음에 <eos>라는 구분자를 입력했을 때 번역이 이루어지며 한글이었던 입력 문장이 영어로 하나하나 출력됨을 볼 수 있다.
한가지 다른 것은 LSTM 계층에서 h를 입력받는다는 점.
이 h는 Encoder에서 나온 은닉 상태 벡터 h이다.
전체 계층
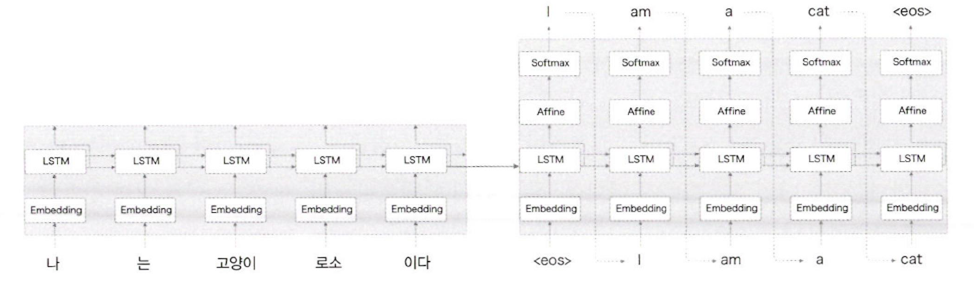
전체 계층을 한 눈에 보면 위와 같다.
왼쪽이 Encoder, 오른쪽이 Decoder이고 각각이 RNN 중 LSTM으로 구성된다.
여기서 h가 둘을 연결하는 '가교' 역할을 한다. 순전파일 때는 Encoder의 은닉상태가 Decoder에 전달되고 역전파일 때는 Decoder에서 Encoder로 가중치나 기울기가 전달된다
장난감 문제(toy problem)
지금까지 알아봤던 seq2seq을 통해 간단한 자연어처리 문제를 해결해보려고 한다.
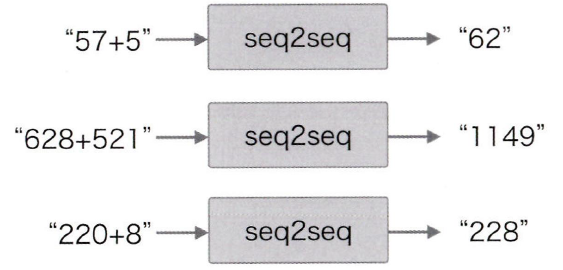
이처럼 더하기 연산을 문자열로 입력했을 때 올바른 정답이 나오는지를 살펴볼 것이다. 여기서 중요한 점은 컴퓨터는 문자열로 입력되는 +의 논리적인 의미를 모른다는 점이다.
print(12+34)처럼 파이썬에서 작성한다면 바로 덧셈을 해주겠지만
"12+34"라는 문자열을 동일하게 인식하지 못한다. 결국 컴퓨터는 많은 데이터로 학습을 하면서 문자들의 규칙을 파악해야 한다.
가변 길이 시계열 데이터
이 장난감 문제에서는 단어가 아닌 문자 단위로 데이터를 분할한다
ex) "12+34" -> ['1','2','+','3','4']
이 때 자릿수에 따라 문제와 답의 길이가 달라진다. 즉 샘플마다 데이터의 시간 방향 크기가 달라진다. 미니배치 학습을 할 때에는 샘플들의 데이터 길이나 형상이 같아야 하므로 이 때 "패딩(Padding)"을 해주어야 한다
Padding
기존의 데이터에 의미없는 값을 채워서 길이를 균등하게 만드는 방법
이 책에서는 공백을 채운다.
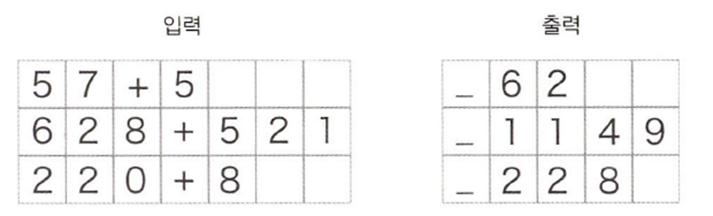
이 그림에서 "_"은 입력과 출력을 구분하는 구분자이며, Decoder에게 문자열을 생성하도록 하는 역할을 한다.
추가적으로 정확도를 높이려면 padding 용으로 추가한 공백은 손실의 결과에 영향을 주지 않도록 조치를 취해야 한다. 그 예로 Softmax with Loss 계층에 '마스크' 기능을 추가하는 방법이 있다고 한다.

데이터 셋을 확인해 보았다. 패딩이 잘 이루어져서 각 문장의 길이가 일정함을 알 수 있다.
sequence.py라는 모듈에서 이전에 CBOW할 때 word_to_id, id_to_word 라는 딕셔너리를 반환했듯이 char_to_id, id_to_char을 반환해주며 char_id를 생성하고 train, test데이터로 나누는 것까지 해준다
이상
