Machine Learning
1.KNN

K-Nearest Neighbor(KNN): 기존의 데이터 중 가장 가까운 k개를 바탕으로 새로운 데이터를 예측하고 분류하는 알고리즘판별하려는 데이터와 인접한 데이터 k개를 찾아 그중 빈도수가 가장 높은 데이터를 범주로 분류한다.거리를 측정할 때에는 주로 Euclidi
2.Ensemble Learning
앙상블의 사전적 의미: 조화, 통일데이터의 값을 예측할 때 하나의 모델만 사용하지 않고, 여러 개의 모델을 '조화'롭게 학습시켜 예측의 정확도를 높이는 방법이다.모델 결합(model combining)이라고도 한다.하나의 모델로 원하는 성능X -> 앙상블 학습 -> 일
3.Decision Tree
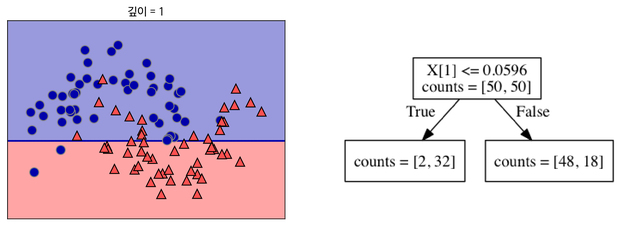
Decision Tree(결정 트리)는 의사결정 트리라고도 하며, 분류(Classification)과 회귀(Regression) 모두 가능한 지도 학습 모델이다. 특정 기준이나 질문에 따라 데이터를 구분하는 모델을 결정 트리 모델이라고 한다.decision tree i
4.Random Forest
나무가 모이면 뭐가 될까요? 숲이 되죠?Decision Tree(결정 트리)가 모이면 뭐가 될까요?Random Forest(랜덤 포레스트)가 됩니다.허허결정 트리 하나로도 학습시킬 수 있지만 이전 포스트에서 언급했듯이 오버피팅이 발생할 수 있다. 여러 결정 트리를 통해
5.K-means Clustering
K-means Clustering(K-평균 군집화)은 비지도 학습의 클러스터링 모델 중 하나이다. 우선 클러스터란 비슷한 특성을 가진 데이터들끼리 묶는 것을 의미한다. 비슷한 특성은 가까운 위치로 해석할 수 있다.cluster위의 그림을 보면 거리가 가까운 데이터들끼리
6.Hierarchical Clustering
Hierarchical Clustering(계층적 군집화)는 계층적 트리 모형을 이용해 개별 개체들을 순차적, 계층적으로 유사한 그룹으로 군집화하는 알고리즘이다.지난 글에서 K-평균 군집화를 다루었는데, 군집화라는 점에서 같지만 K-평균 군집화와 달리 군집의 수(K)를
7.SVM(Support Vector Machine)
SVM(Support Vector Machine)은 주어진 데이터가 어디에 속하는지 분류하는 이진 선형 분류 모델이다. N차원의 공간을 (N-1)차원으로 나눌 수 있는 초평면을 찾는 분류 기법이다. 초평면은 경계를 뜻하며, 특히 2차원 뿐만 아니라 고차원에서도 분류할
8.Metrics
사이킷런에 있는 서브패키지로, 분류문제의 여러 성능평가 명령을 제공한다. 일반적으로 정확도(accuracy_score)를 많이 사용하는데, 이밖에도 여러 종류의 성능평가 지표가 있다.타겟의 정답인 클래스와 모형이 예측한 클래스가 얼마나 일치하는지 세서 표로 나타낸 것이
9.신경망 학습 과정
학습 전 신경망은 크게 입력층, 은닉층, 출력층으로 구성된다. x1, x2는 입력 신호이며, 입력 신호가 다음 노드로 보내질 때에 가중치가 곱해진다. w1, w2는 가중치, b는 편향이다. w1*x1 + b = a y = h(a) 가중치와 입력신호의 곱에 편향이 더
10.ch.7 RNN을 사용한 문장생성
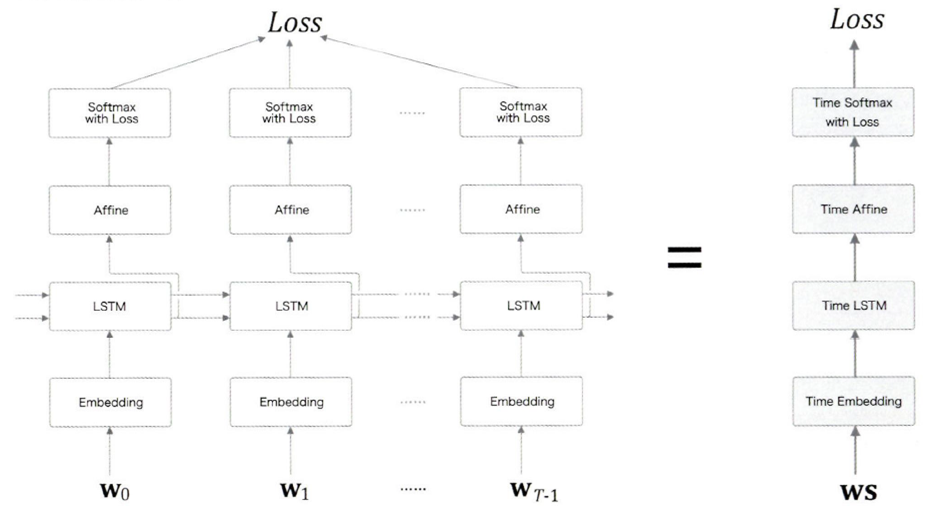
T개의 시계열 데이터를 한번에 처리하는 계층Time Embedding 계층: 단어 ID를 단어의 분산 표현으로 변환Time LSTM 계층: RNN과 다르게 c(기억 셀)가 있음 - LSTM 계층에서만 사용, 게이트가 추가됨(output, forget, input, 기억