본 포스팅은 네이버 부스트캠프 3기에서 공부한 내용을 기반으로 작성된 글입니다.
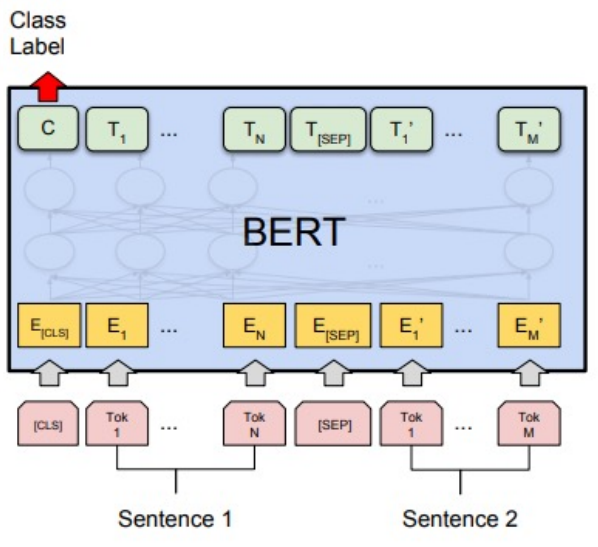
Model Architecture
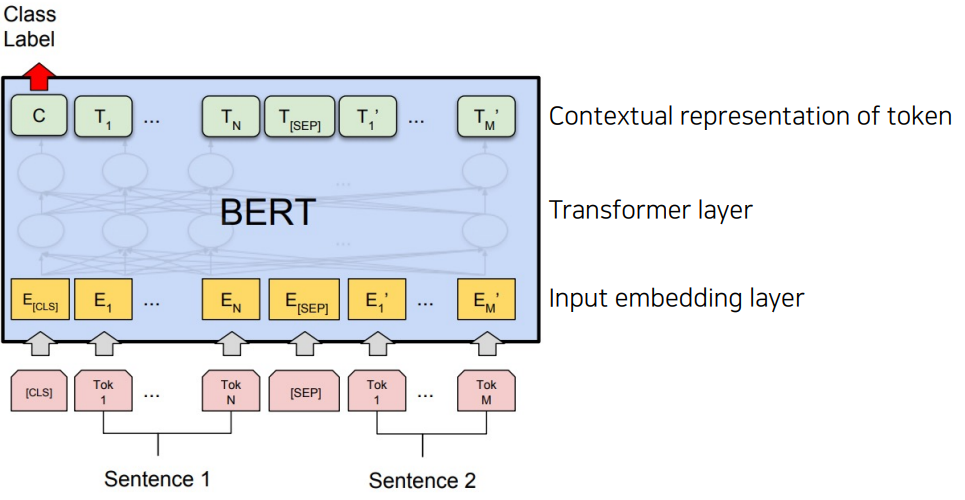
Input : [CLS] Sentence 1 [SEP] Sentence 2
[CLS] : classification 수행에 필요한 정보를 담을 토큰
[SEP] : 문장과 문장 사이를 구분하기 위한 토큰
Output : Class Label
Sentence1과 Sentence2가 연속되는 문장인지 아닌지 분류 (IsNext or NotNext)
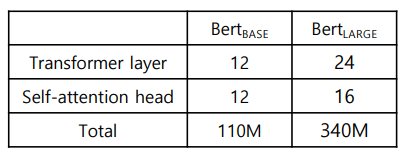
BERT vs BERT
Dataset
- BooksCorpus (800M words)
- English Wikipedia (2,500M words without lists, tables and headers)
- 30,000 token vocabulary
Tokenizing
-
WordPiece tokenizing
Byte Pair Encoding (BPE) 알고리즘 이용
빈도수에 기반해 단어를 의미 있는 패턴(Subword)으로 잘라서 tokenizing
Masked Language Model
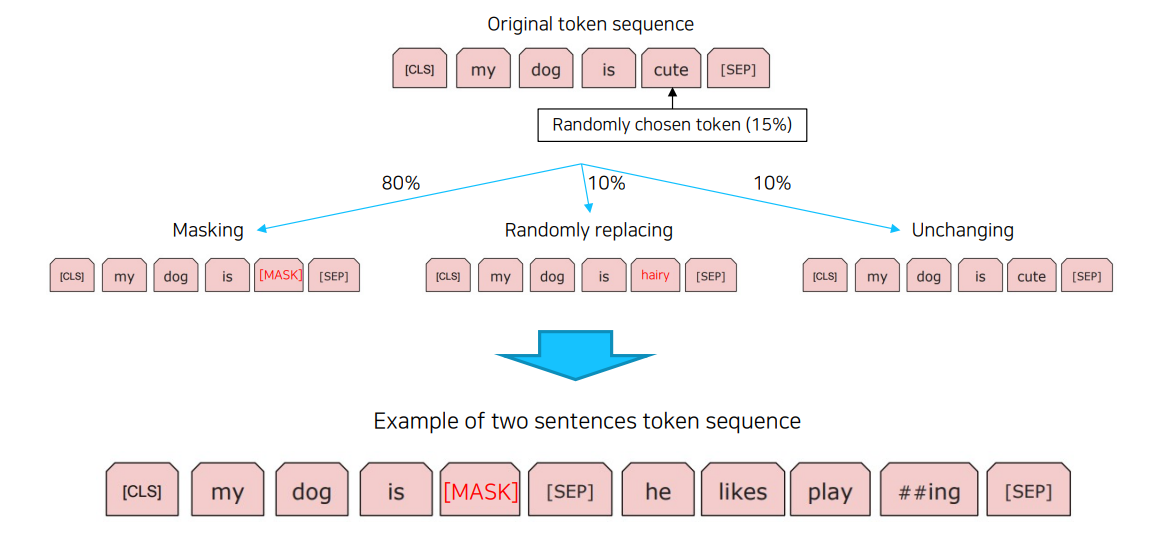
입력 문장에서 랜덤으로 선택된 토큰에 대하여 80% 확률로 Masking하고, 10% 확률로 랜덤하게 선택된 다른 단어로 대체하고, 10% 확률로 변경시키지 않음
NLP Experiments
단일 문장 분류
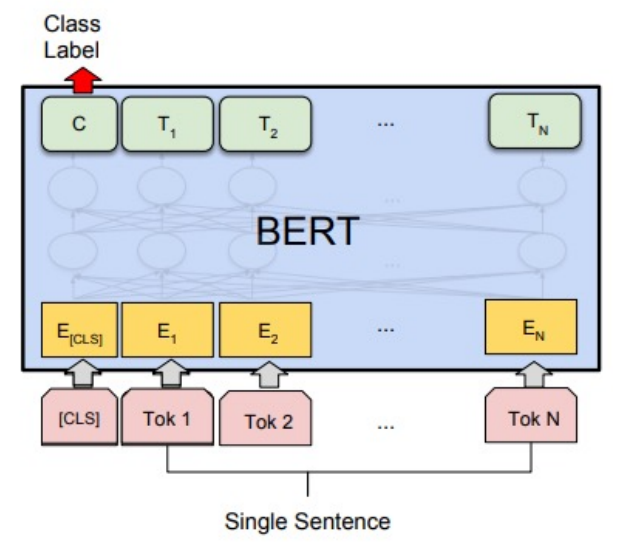
감정 분석 : 영화 리뷰를 보고 긍정인지 부정인지 분류하기
관계 추출 : sentence와 sbj entitiy, obj entity가 주어졌을 때, entity 간 관계 예측
두 문장 관계 분류
의미 비교 : 두 문장이 서로 유사한지 유사하지 않은지 분류
유사하지 않은 문장 pairs에 대한 학습 데이터가 서로 너무 연관성이 없기 때문에, 실제 활용되기 어렵다는 문제점이 존재
문장 토큰 분류
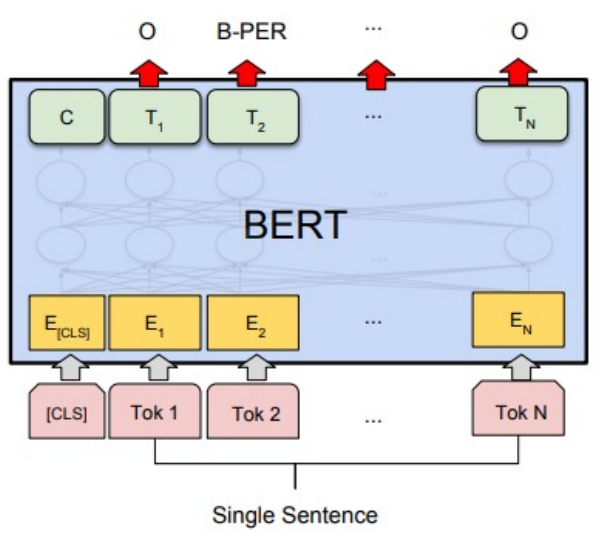
개체명 인식 : 비정형 텍스트의 개체명을 인명, 단체, 장소, 의학 코드, 시간 표현, 양, 금전적 가치, 퍼센트 등 미리 정의된 분류로 위치시키고 분류시키는 정보 추출의 하위 태스크
https://ko.wikipedia.org/wiki/%EA%B0%9C%EC%B2%B4%EB%AA%85_%EC%9D%B8%EC%8B%9D
기계 독해 정답 분류
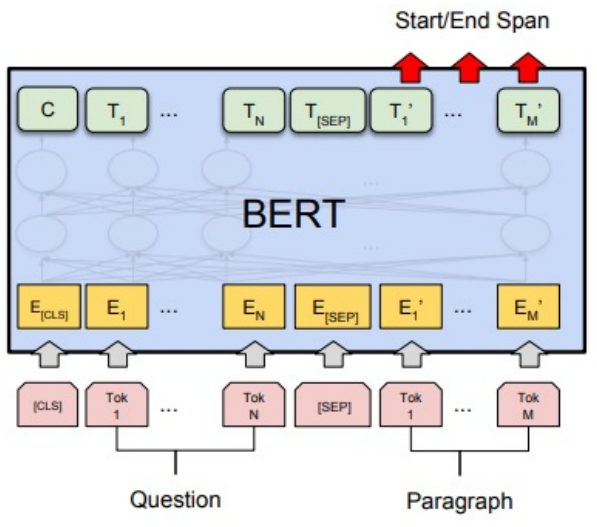
질문과 문단을 입력으로 받아서 정답의 위치(Start/End)를 예측
음절 단위 tokenizer를 사용하는 것이 어절 단위 tokenizer를 사용하는 것 보다 높은 성능을 보임
