boostcamp
1.부스트캠프 3기 Pythonic code (1월 17일)

본 포스팅은 네이버 부스트캠프 3기를 통해 공부한 내용을 기반으로 작성된 글입니다.파이썬에서 많이 사용되는 기법일반적으로 사용되는 for + append 보다 속도가 빠름List를 사용하여 간단히 새로운 List를 만드는 방법list comprehension 방식기존
2.부스트캠프 3기 AI Math 확률론 (1월 21일)
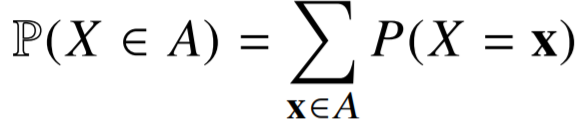
본 포스팅은 네이버 부스트캠프 3기를 통해 공부한 내용을 기반으로 작성된 글입니다.딥러닝은 확률론 기반의 기계학습 이론에 바탕을 둠손실함수(loss)들의 작동 원리도 확률론에서 유도회귀 분석에서 손실함수로 사용되는 L2 Norm : 예측오차의 분산을 가장 최소화하는 방
3.부스트캠프 3기 AI Math 통계학 (1월 21일)

본 포스팅은 네이버 부스트캠프 3기를 통해 공부한 내용을 기반으로 작성된 글입니다.통계학에서 모수는 모 평균, 모 표준 편차, 모 분산 등 모집단의 데이터를 의미함베르누이 분포 : θ = μ이항분포 : θ = ( N, μ )정규분포 : θ = ( μ, σ2 ) 통계적
4.[NLP] Bag of Words
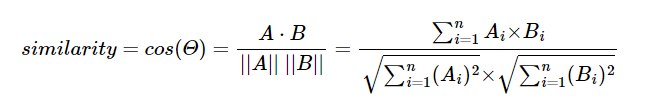
1) 문장에 등장하는 단어들을 포함하는 vocabulary 구성 (중복제거)sentences : "John really really loves this movie", "Jane really likes this song"Vocabulary : {"John","really
5.[NLP] Word Embedding: Word2Vec, GloVe
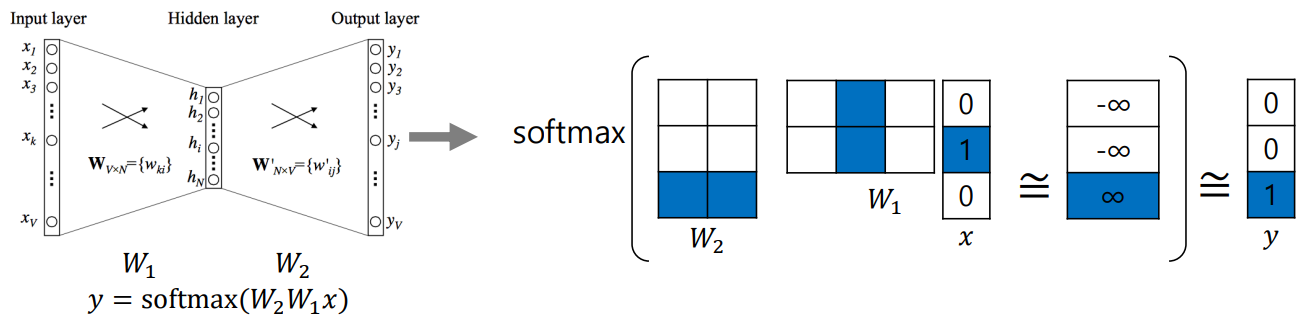
본 포스팅은 네이버 부스트캠프 3기를 통해 공부한 내용을 기반으로 작성된 글입니다."하나의 단어를 하나의 벡터로 표현한 것"비슷한 의미를 가진 단어가 좌표 공간상 비슷한 위치에 mapping 되게 함으로써 단어들의 의미상 유사도를 반영한 벡터 표현가장 유명한 word
6.[NLP] Long Short-Term Memory (LSTM)
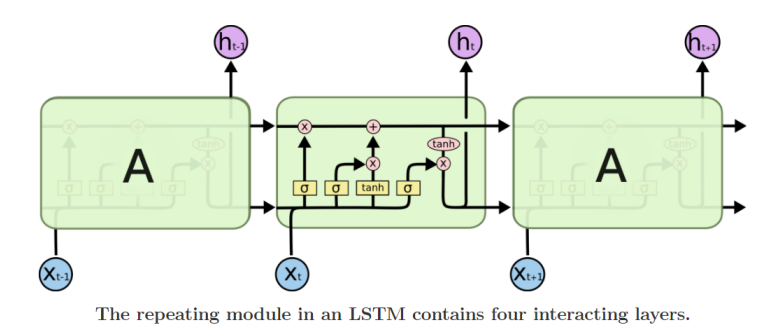
본 포스팅은 네이버 부스트캠프 3기를 통해 공부한 내용을 기반으로 작성된 글입니다.기존 RNN의 gradient vanishing/exploding 문제 해결Long-Term dependency 문제를 개선한 모델Vanilla RNN : $$ht$$ = $$f_w(x_
7.[NLP] BERT (Bi-directional Encoder Representations from Transformers)
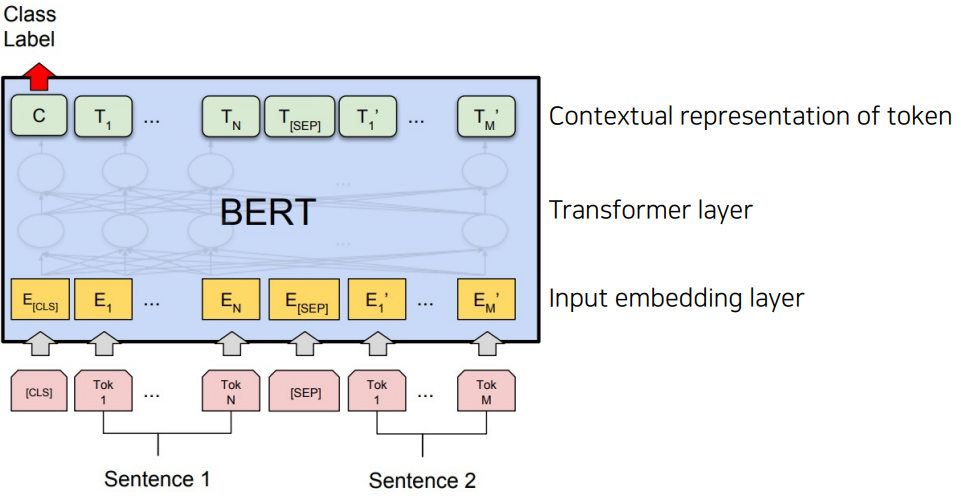
본 포스팅은 네이버 부스트캠프 3기를 통해 공부한 내용을 기반으로 작성된 글입니다.Input : CLS Sentence 1 SEP Sentence 2 CLS : classification 수행에 필요한 정보를 담을 토큰SEP : 문장과 문장 사이를 구분하기 위한 토큰O
8.[NLP] MRC (Machine Reading Comprehension)

본 포스팅은 네이버 부스트캠프 3기에서 공부한 내용을 기반으로 작성된 글입니다.지문(context)을 이해하고 질의(question)의 답변을 추론하는 문제Extractive Answer Datasets질의에 대한 답변이 항상 지문에 segment(or span)으로
9.[NLP] Extraction-based MRC tutorial
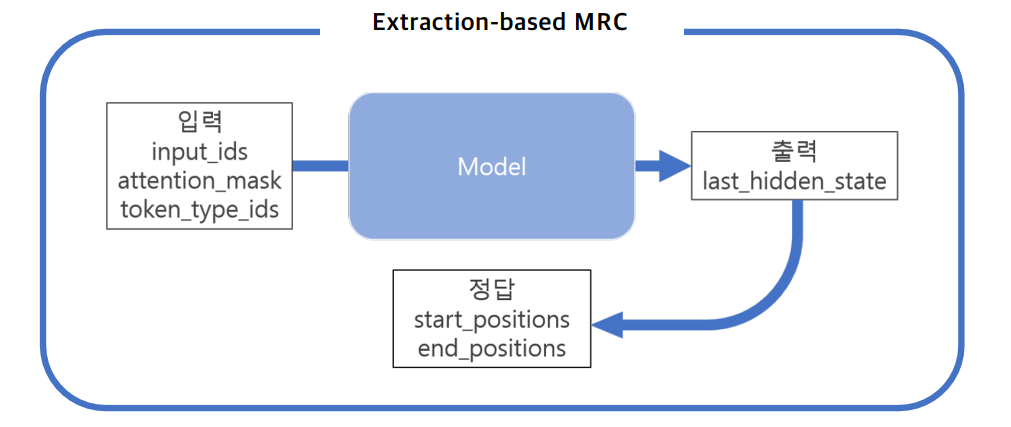
필요한 라이브러리 설치 데이터셋, 평가지표 불러오기 Huggingface를 이용하여 편리하게 데이터셋을 이용할 수 있습니다. Pre-trained model 불러오기 Huggingface를 이용하여 필요한 모델을 불러올 수 있습니다. .from_config()
10.[NLP] Generation-based MRC tutorial
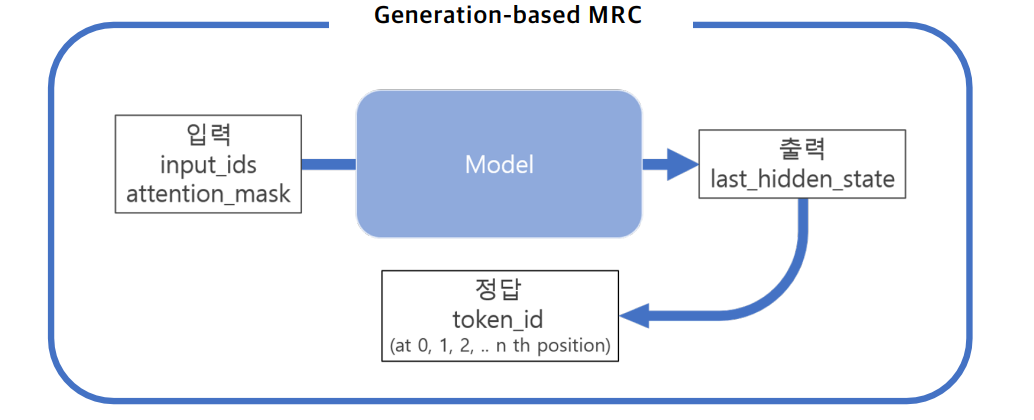
본 포스팅은 네이버 부스트캠프 3기에서 공부한 내용을 기반으로 작성된 글입니다.MRC : 지문(context)을 이해하고 질의(question)의 답변을 추론하는 문제Generation-based MRC : 주어진 질의를 보고 답변을 생성하는 문제Huggingface를
11.[NLP] Passage Retrieval
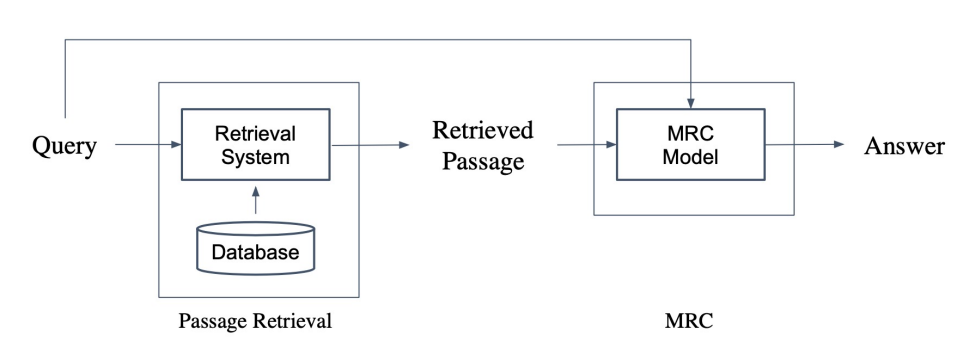
본 포스팅은 네이버 부스트캠프 3기에서 공부한 내용을 기반으로 작성된 글입니다.질문(query)에 맞는 문서(passage)를 찾는 task로 문서들 중 질문과 가장 관련있는 문서를 찾는 방식으로 해결합니다.Query와 Passage를 embedding 한 후, 유사도