본 포스팅은 네이버 부스트캠프 3기에서 공부한 내용을 기반으로 작성된 글입니다.
Long Short-Term Memory (LSTM)
기존 RNN의 gradient vanishing/exploding 문제 해결
Long-Term dependency 문제를 개선한 모델
Vanilla RNN : =
LSTM : =
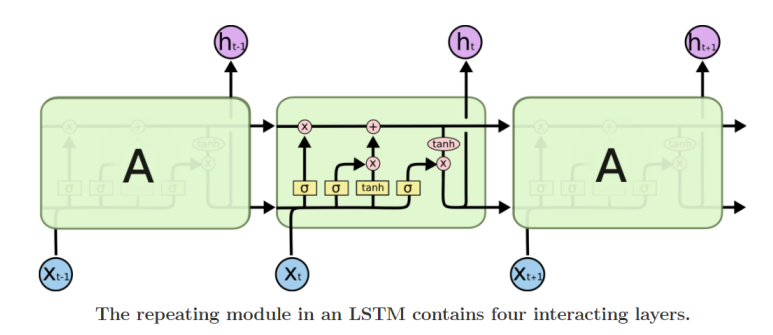
Long short-term memory
i : Input gate (cell에 쓸지 말지 결정)
f : Forget gate (cell에서 지울지 말지 결정)
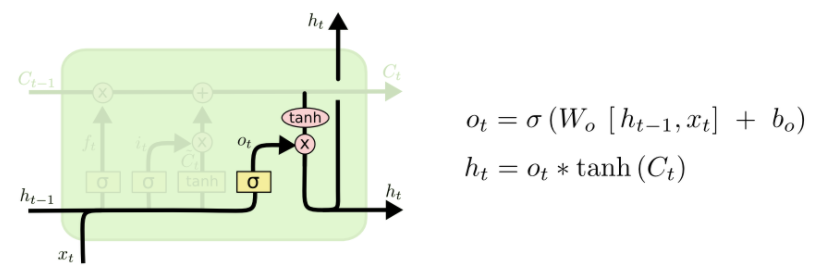
o: Output gate (cell에 얼마나 노출시킬 지 결정)
g : Gate gate (cell에 얼마나 쓸지 결정)
: cell state (gate들이 작용하며 필요한 정보를 선택적으로 담고 있는 vector)
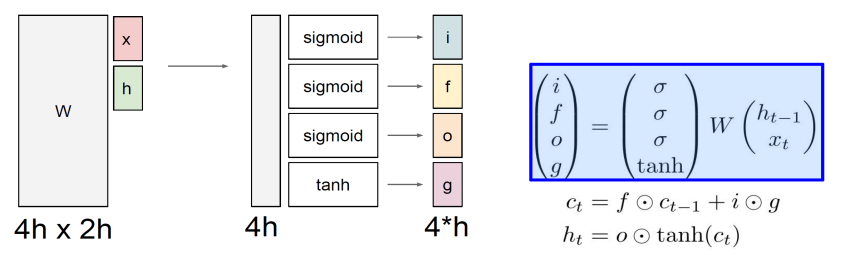
x와 h의 차원이 동일하다고 가정하면, w의 shape은 4hx2h(x+h)
행렬곱 수행 후, 4hx1 행렬의 행을 4개로 나누어 각 gate에 사용됨
input, forget, output gate는 sigmoid를 사용하여 0-1 값(확률)이 출력되고, 이를 벡터와 곱하면서 원래 값의 일부를 취함
gate gate는 tanh를 사용하여 -1-1 값이 출력되고, 현재 time step에서 계산되는 유의미한 정보를 추출하기 위해 사용
- Forget gate
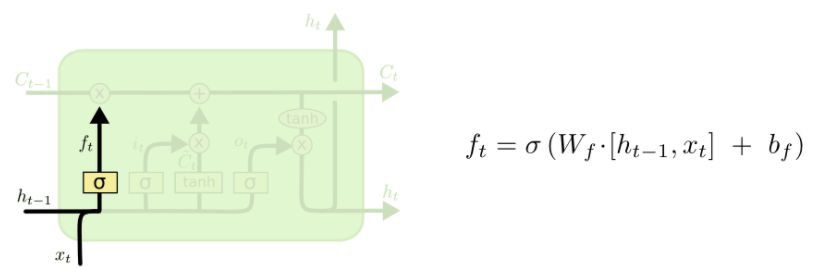
- Input gate
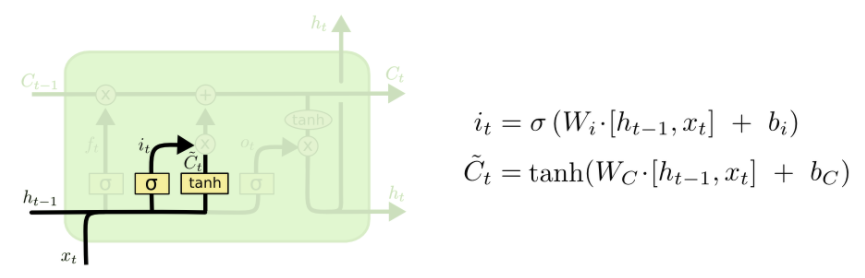
- Output gate

머신러닝 엔지니어를 꿈꾸는 부스트캠퍼입니다🙏