본 포스팅은 네이버 부스트캠프 3기에서 공부한 내용을 기반으로 작성된 글입니다.
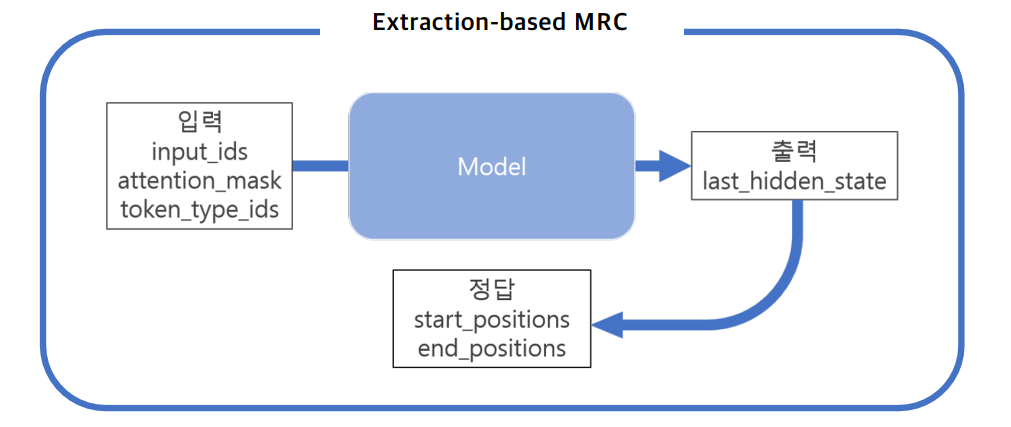
Extraction-based MRC?
MRC : 지문(context)을 이해하고 질의(question)의 답변을 추론하는 문제
Extraction-based MRC : 질의에 대한 답변이 항상 지문에 segment(or span)으로 존재하여 답변의 위치(start/end)를 추론하는 문제
필요한 라이브러리 설치
!pip install datasets==1.4.1
!pip install transformers==4.5.0
!pip install tqdm==4.48.0
!git clone https://github.com/huggingface/transformers.git
import sys
sys.path.append('transformers/examples/question-answering')데이터셋, 평가지표 불러오기
Huggingface를 이용하여 편리하게 데이터셋을 이용할 수 있습니다.
from datasets import load_dataset
from datasets import load_metric
# KorQuAD 1.0 dataset load
datasets = load_dataset("squad_kor_v1")
metric = load_metric('squad')Pre-trained model 불러오기
Huggingface를 이용하여 필요한 모델을 불러올 수 있습니다.
-
.from_config() : pre-training을 하지 않은 모델을 불러오는 method
-
.from_pretrained() : pre-trained model을 불러오는 method이고, 스스로 학습한 모델을 불러오려면 model_name 부분에 model이 저장된 directory를 입력해야 함
Model type
- hidden state가 출력되는 기본 모델
AutoModel.from_pretrained("bert-base-cased")- downstream task 모델
AutoModelForQuestionAnswering.from_pretrained("bert-base-cased")QA를 위한 KLUE BERT base 모델 불러오기
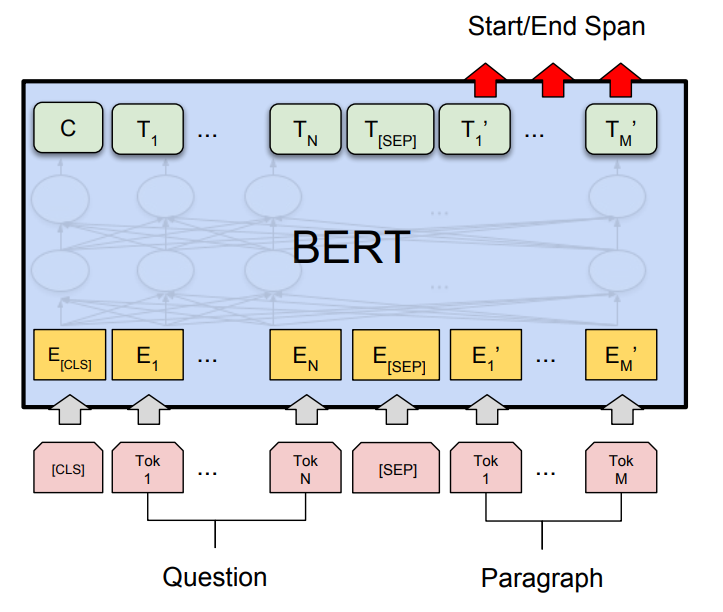
QA를 위한 BERT의 마지막 layer는 다음 그림과 같습니다.
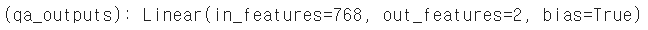
토큰 별로 start, end position을 예측해야 하기 때문에 out_features가 2입니다.
from transformers import (
AutoConfig,
AutoModelForQuestionAnswering,
AutoTokenizer
)
model_name = "klue/bert-base"
config = AutoConfig.from_pretrained(
model_name
)
tokenizer = AutoTokenizer.from_pretrained(
model_name,
use_fast=True # Whether or not to try to load the fast version of the tokenizer.
)
model = AutoModelForQuestionAnswering.from_pretrained(
model_name,
config=config
)BERT Config 살펴보기
변경하지 않아야 하는 config
Pretrained model 사용시 hidden dim등 이미 정해져 있는 모델의 아키텍쳐 세팅은 수정하면 안됩니다. 이를 수정해버릴 경우 에러가 발생하거나, 잘못된 방향으로 학습 될 수 있습니다.
변경해도 되는 config
vocab의 경우 special token을 추가한다면 config를 추가한 vocab의 개수만큼 추가하여 학습해야합니다. downstream task를 위해 몇가지 config를 추가할 수도 있습니다.
BertConfig {
"_name_or_path": "klue/bert-base",
"architectures": [
"BertForMaskedLM"
],
"attention_probs_dropout_prob": 0.1,
"gradient_checkpointing": false,
"hidden_act": "gelu",
"hidden_dropout_prob": 0.1,
"hidden_size": 768,
"initializer_range": 0.02,
"intermediate_size": 3072,
"layer_norm_eps": 1e-12,
"max_position_embeddings": 512,
"model_type": "bert",
"num_attention_heads": 12,
"num_hidden_layers": 12,
"pad_token_id": 0,
"position_embedding_type": "absolute",
"transformers_version": "4.4.1",
"type_vocab_size": 2,
"use_cache": true,
"vocab_size": 32000
}-
gradient_checkpointing
메모리의 부족으로 원하는 batch size로 학습시키지 못할 때, gradient를 누적시켜 업데이트 하는 방식을 이용합니다. 하지만, 큰 모델을 사용할 때 메모리 부족 문제, 오버헤드 문제가 존재합니다.
Gradient checkpointing은 계산 그래프 전체에 전략적으로 선택된 활성화를 저장하므로 활성화의 일부만 그라디언트에 대해 다시 계산하면 됩니다. 이런 방식은 더 많은 메모리를 절약하지만 동시에 학습이 약간 느려졌음을 알 수 있습니다. 일반적으로 그래디언트 체크포인트는 학습 속도를 약 20% 늦춥니다.
fp16을 이용하여 속도를 개선시킬 수 있음
https://huggingface.co/docs/transformers/main/en/performance#gradient-checkpointing
필요한 변수 설정하기
max_seq_length = 384 # 질문과 컨텍스트, special token을 합한 문자열의 최대 길이
pad_to_max_length = True
doc_stride = 128 # 컨텍스트가 길어서 나눴을 때 오버랩되는 시퀀스 길이
max_train_samples = 16
max_val_samples = 16
preprocessing_num_workers = 4
batch_size = 4
num_train_epochs = 2
n_best_size = 20 # 질문 당 예측하는 답의 개수
max_answer_length = 30Preprocessing
train dataset 전처리
정답의 시작위치와 끝위치를 저장하고, 정답이 지문을 벗어나는 예외를 처리해줍니다.
def prepare_train_features(examples):
# 주어진 텍스트를 토크나이징 한다. 이 때 텍스트의 길이가 max_seq_length를 넘으면 stride만큼 슬라이딩하며 여러 개로 쪼갬.
# 즉, 하나의 example에서 일부분이 겹치는 여러 sequence(feature)가 생길 수 있음.
tokenized_examples = tokenizer(
examples["question"],
examples["context"],
truncation="only_second", # max_seq_length까지 truncate한다. pair의 두번째 파트(context)만 잘라냄.
max_length=max_seq_length,
stride=doc_stride,
return_overflowing_tokens=True, # 길이를 넘어가는 토큰들을 반환할 것인지
return_offsets_mapping=True, # 각 토큰에 대해 (char_start, char_end) 정보를 반환한 것인지
padding="max_length",
)
# example 하나가 여러 sequence에 대응하는 경우를 위해 매핑이 필요함.
overflow_to_sample_mapping = tokenized_examples.pop("overflow_to_sample_mapping")
# offset_mappings으로 토큰이 원본 context 내 몇번째 글자부터 몇번째 글자까지 해당하는지 알 수 있음.
offset_mapping = tokenized_examples.pop("offset_mapping")
# 정답지를 만들기 위한 리스트
tokenized_examples["start_positions"] = []
tokenized_examples["end_positions"] = []
for i, offsets in enumerate(offset_mapping):
input_ids = tokenized_examples["input_ids"][i]
cls_index = input_ids.index(tokenizer.cls_token_id)
# 해당 example에 해당하는 sequence를 찾음.
sequence_ids = tokenized_examples.sequence_ids(i)
# sequence가 속하는 example을 찾는다.
example_index = overflow_to_sample_mapping[i]
answers = examples["answers"][example_index]
# 텍스트에서 answer의 시작점, 끝점
answer_start_offset = answers["answer_start"][0]
answer_end_offset = answer_start_offset + len(answers["text"][0])
# 텍스트에서 현재 span의 시작 토큰 인덱스
token_start_index = 0
while sequence_ids[token_start_index] != 1:
token_start_index += 1
# 텍스트에서 현재 span 끝 토큰 인덱스
token_end_index = len(input_ids) - 1
while sequence_ids[token_end_index] != 1:
token_end_index -= 1
# answer가 현재 span을 벗어났는지 체크
if not (offsets[token_start_index][0] <= answer_start_offset and offsets[token_end_index][1] >= answer_end_offset):
tokenized_examples["start_positions"].append(cls_index)
tokenized_examples["end_positions"].append(cls_index)
else:
# token_start_index와 token_end_index를 answer의 시작점과 끝점으로 옮김
while token_start_index < len(offsets) and offsets[token_start_index][0] <= answer_start_offset:
token_start_index += 1
tokenized_examples["start_positions"].append(token_start_index - 1)
while offsets[token_end_index][1] >= answer_end_offset:
token_end_index -= 1
tokenized_examples["end_positions"].append(token_end_index + 1)
return tokenized_examplescolumn_names = datasets["train"].column_names
train_dataset = datasets["train"]
train_dataset = train_dataset.map(
prepare_train_features,
batched=True,
num_proc=preprocessing_num_workers,
remove_columns=column_names,
load_from_cache_file=True,
)Post processing
원하는 형태로 예측값 추출하기 위해 후처리를 진행합니다.
def post_processing_function(examples, features, predictions):
# Post-processing: we match the start logits and end logits to answers in the original context.
predictions = postprocess_qa_predictions(
examples=examples,
features=features,
predictions=predictions,
version_2_with_negative=False,
n_best_size=n_best_size,
max_answer_length=max_answer_length,
null_score_diff_threshold=0.0,
output_dir=training_args.output_dir,
is_world_process_zero=trainer.is_world_process_zero(),
)
# Format the result to the format the metric expects.
formatted_predictions = [{"id": k, "prediction_text": v} for k, v in predictions.items()]
references = [{"id": ex["id"], "answers": ex["answers"]} for ex in datasets["validation"]]
return EvalPrediction(predictions=formatted_predictions, label_ids=references)Train model
Arguments를 정의하고 학습을 진행합니다.
training_args = TrainingArguments(
output_dir="outputs",
do_train=True,
do_eval=True,
learning_rate=3e-5,
per_device_train_batch_size=batch_size,
per_device_eval_batch_size=batch_size,
num_train_epochs=num_train_epochs,
weight_decay=0.01,
)trainer = QuestionAnsweringTrainer(
model=model,
args=training_args,
train_dataset=train_dataset,
eval_dataset=eval_dataset,
eval_examples=datasets["validation"],
tokenizer=tokenizer,
data_collator=default_data_collator,
post_process_function=post_processing_function,
compute_metrics=compute_metrics,
)
train_result = trainer.train()학습시킨 모델 불러오기
finetuned_model = AutoModelForQuestionAnswering.from_pretrained('모델저장경로')