본 포스팅은 네이버 부스트캠프 3기에서 공부한 내용을 기반으로 작성된 글입니다.
Passage Retrieval?
질문(query)에 맞는 문서(passage)를 찾는 task로 문서들 중 질문과 가장 관련있는 문서를 찾는 방식으로 해결합니다.
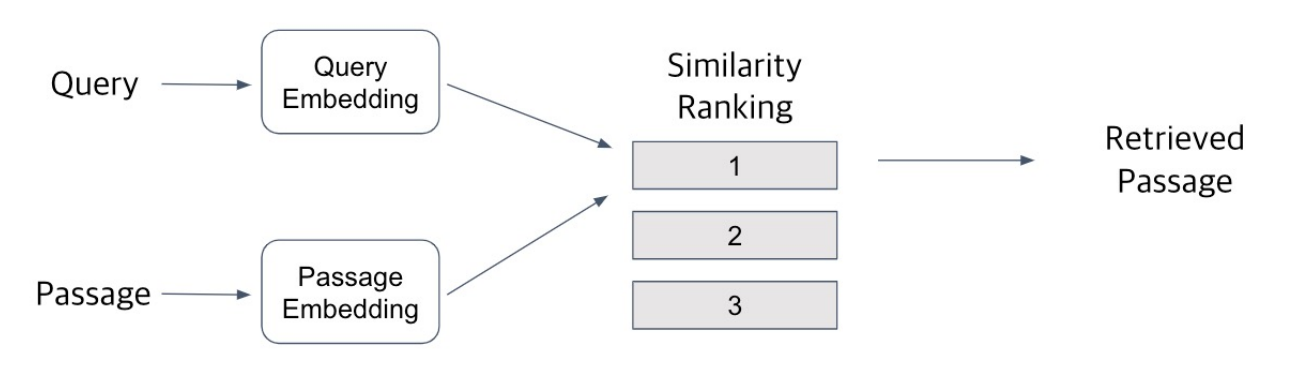
Query와 Passage를 embedding 한 후, 유사도로 랭킹을 매기고 가장 높은 passage 선택
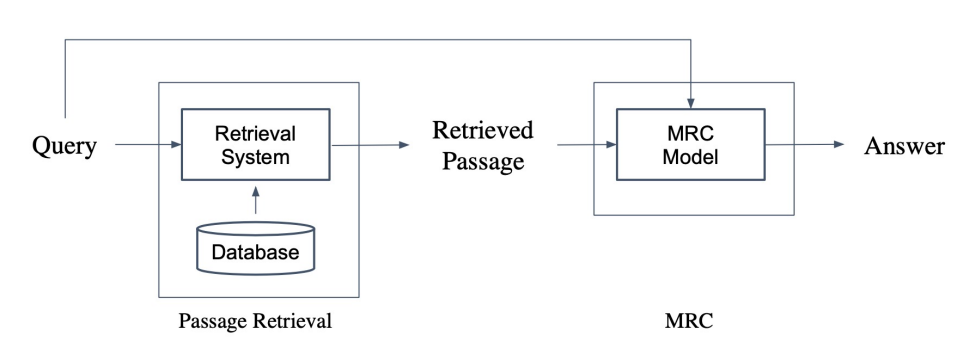
아래 그림과 같이 Passage Retrieval과 MRC를 이용하여 Open-domain Question Answering을 수행할 수 있습니다.
Sparse Embedding
TF-IDF
TF-IDF(t,d) =
-
Term Frequency (TF): 문서 내 단어의 등장 빈도
-
Inverse Document Frequency (IDF): 단어가 제공하는 정보의 양
'a', 'the'와 같이 자주 등장하지만 정보량이 적은 단어들은 낮은 TF-IDF 값을 가지고, 고유명사(이름, 지명)과 같은 자주 등장하지 않지만 정보량이 많은 단어들은 높은 TF-IDF 값을 가지게 됩니다.
-
TF-IDF를 이용하여 유사도 계산하기
각 문서의 TF-IDF와 질의의 TF-IDF를 계산하여 질의와 가장 관련있는 문서를 찾을 수 있습니다.
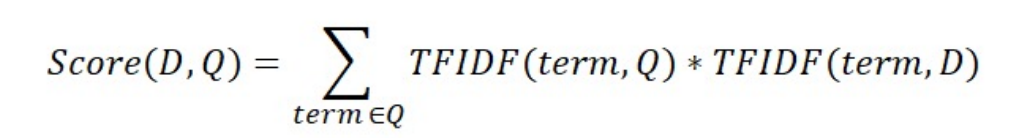
- 질의 토큰화
- 기존 단어 사전에 없는 토큰들은 제외
- 질의에 대한 TF-IDF 계산
- 질의 TF-IDF 값과 각 문서별 TF-IDF 값을 곱하여 유사도 계산
- 가장 높은 점수를 가지는 문서 선택
BM25
TF-IDF 기반으로 문서의 길이를 고려하여 점수를 매기는 방식입니다.
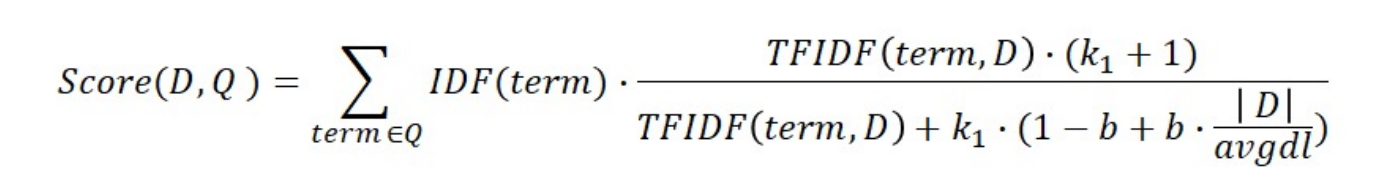
-
평균적인 문서 길이 보다 작은 무서에서 단어가 매칭되는 경우, 해당 문서에 가중치 부여
-
실제 검색엔진, 추천 시스템 등에서 많이 사용되는 알고리즘
Dense Embedding
Sparse Emedding 단점
Sparse embedding은 벡터의 차원이 매우 크지만 대부분이 0으로 채워져 있고, 유사성을 고려하지 못한다는 문제점이 존재합니다.

dense embedding은 대부분의 요소가 non-zero 값을 갖도록 작은 차원의 고밀도 벡터로 임베딩하는 방식입니다. sparse embedding 처럼 각 차원이 특정 단어에 대응되는 것이 아니고, 벡터 공간에서의 위치가 의미를 나타내도록 복합적으로 임베딩 됩니다.
- Sparse embedding vs Dense embedding

-
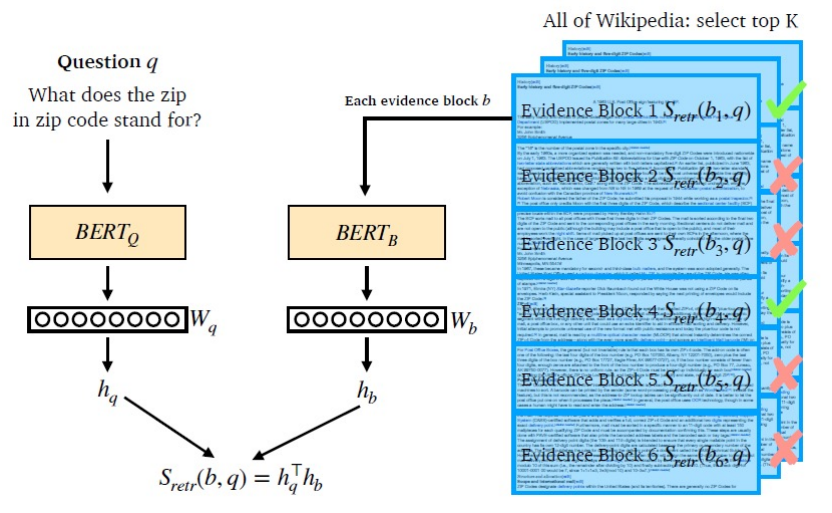
Dense Embedding with BERT
인코더로 BERT와 같은 Pre-trained language model(PLM)이 자주 사용되고, 다양한 neural network 구조도 사용 가능합니다.
-
Query를 위한 인코더와 Passage를 위한 인코더를 각각 학습시켜 임베딩 수행 (CLS token 사용)
일반적으로 다른 인코더를 사용하지만, 동일한 인코더를 사용하는 경우도 있다.
-
Query와 Passage를 비교하여 가장 관련있는 문서 추출
연관된 query와 passage의 embedding 간 거리를 좁히도록 학습 (두 임베딩 벡터의 내적값을 높이도록 학습)
-
Dense Encoder를 위한 학습 데이터
Positive sample
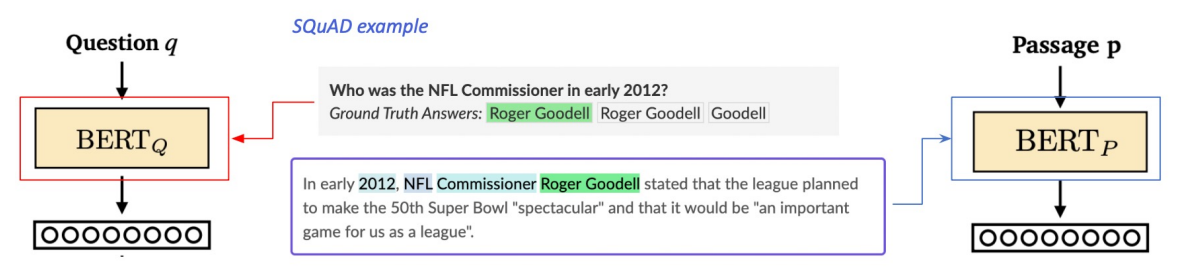
SQuAD와 같은 기존 MRC dataset을 활용하여 연관된 query와 passage를 얻을 수 있습니다.
Negative samples
Corpus 내에서 랜덤으로 뽑거나 헷갈리는 샘플들을 뽑아 연관되지 않은 query와 passage를 얻을 수 있습니다.
헷갈리는 negative samples은 답을 포함하지 않지만 TF-IDF 값이 높은 것을 의미합니다.
Objective function
Positive passage에 대한 negative log likelihood (NLL) loss를 사용합니다.

"query와 positive passage 사이 유사도"를 "query와 positive passage 사이 유사도 + query와 negative passages 사이 유사도의 합"으로 나눈 것을 -log 취한 것이 loss 값으로 계산됩니다.
