본 포스팅은 네이버 부스트캠프 3기를 통해 공부한 내용을 기반으로 작성된 글입니다.
Why?
딥러닝은 확률론 기반의 기계학습 이론에 바탕을 둠
손실함수(loss)들의 작동 원리도 확률론에서 유도
- 회귀 분석에서 손실함수로 사용되는 L2 Norm : 예측오차의 분산을 가장 최소화하는 방향으로 학습 유도
- 분류 문제에서 사용되는 Cross-entropy : 모델 예측의 불활식성을 최소화하는 방향으로 학습 유도
이산확률변수 vs 연속확률변수
모든 확률 변수가 둘로 구분되는 것은 아님
- 이산(discrete)확률변수
이산형 확률변수는 확률변수가 가질 수 있는 경우의 수를 모두 고려하여 확률을 더해서 모델링
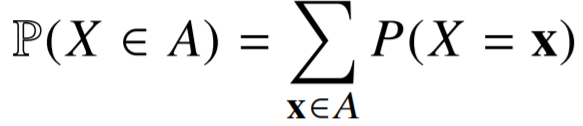
- 연속(continuous)확률변수
연속형 확률변수는 데이터 공간에 정의된 확률변수의 밀도 위에서의 적분을 통해 모델링
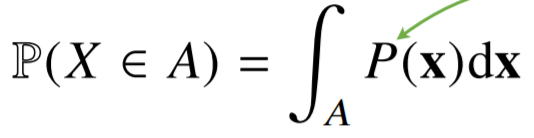
조건부확률과 기계학습
P(y|x) : 입력변수 x에 대해 정답이 y일 확률
연속확률분포의 경우, 확률이 아니고 밀도로 해석!
- task에 따라 사용하는 estimator가 달라짐
-
logistic regression에서 사용하는 선형모델과 softmax 함수의 결합은 데이터에서 추출된 패턴을 기반으로 확률을 해석하는데 사용
-
분류 문제에서 softmax(Wϕ+b)은 데이터 x로부터 추출된 특징패턴 ϕ(x)과 가중치 행렬 W를 통해 조건부 확률 P(y|x)을 계산
-
회귀 문제의 경우 조건부 기대값 E[y|x]을 추정
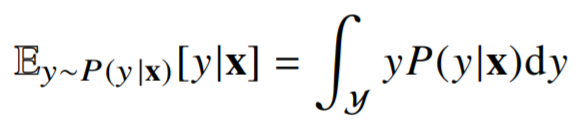
기대값(expectation)은 데이터를 대표하는 통계량이면서 동시에 확률분포를 통해 다른 통계적 범함수를 계산하는데 사용

- 딥러닝은 다층 신경망을 사용하여 데이터로부터 특징패턴 ϕ 추출
Monte-Carlo Sampling
머신러닝의 문제들은 확률분포를 명시적으로 모를 때가 많음 -> 데이터를 이용하여 기대값을 계산하려면 몬테카를로 샘플링 방법을 사용
몬테카를로는 이산형이든 연속형이든 상관없이 성립
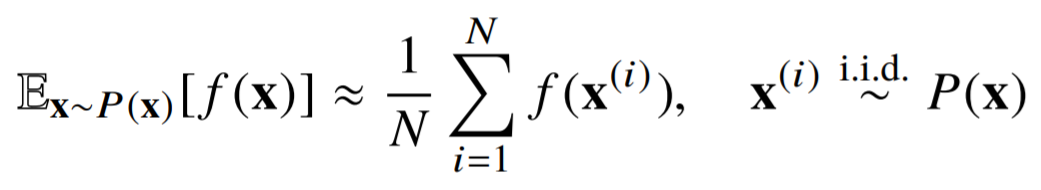
독립추출만 보장된다면 대수의 법칙에 의해 수렴성 보장

머신러닝 엔지니어를 꿈꾸는 부스트캠퍼입니다🙏