📚 결정 트리 (Decision Tree)
분류 알고리즘의 하나로, 이해하기가 굉장히 쉽다라는 장점이 있다.
클래스 라벨을 따져서 논리곱을 보여줌으로써,
각 질문을 만족시키는지/만족시키지 못하는지에 따라서 클래스 분류 확률을 보여준다.
백문에 불여일견 ! 일단 해보자.
🤓 실습
실습은 [혼자 공부하는 머신러닝+딥러닝] 에서 가져왔다.
데이터 가져오기
import pandas as pd
wine = pd.read_csv('https://bit.ly/wine-date')
wine.info()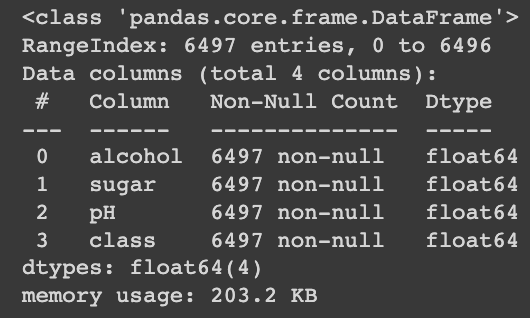
훈련-테스트 데이터 나누기 및 표준화
from sklearn.model_selection import train_test_split
# 테스트 데이터 20%
train_input, test_input, train_target, test_target = train_test_split(data, target, test_size=0.2, random_state=42)
# 확인
print(train_input.shape, test_input.shape)
# 표준화
from sklearn.preprocessing import StandardScaler
ss = StandardScaler()
ss.fit(train_input)
train_scaled = ss.transform(train_input)
test_scaled = ss.transform(test_input)
결정 트리 만들기
결정 트리를 만들고 훈련시켜 훈련 점수와 테스트 점수를 출력해보자.
from sklearn.tree import DecisionTreeClassifier
dt = DecisionTreeClassifier()
dt.fit(train_scaled, train_target)
print(dt.score(train_scaled, train_target))
print(dt.score(test_scaled, test_target))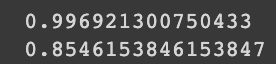
테스트 점수가 훈련 점수에 비해 너무 낮게 나오는 과대적합 현상이 일어난다.
트리 시각화하기
기본적으로 노드에 써있는 정보가 거짓이면 왼쪽을 따라, 참이면 오른쪽을 따라가면 된다.
# 그리기
import matplotlib.pyplot as plt
from sklearn.tree import plot_tree
plt.figure(figsize=(10,7))
plot_tree(dt)
plt.show()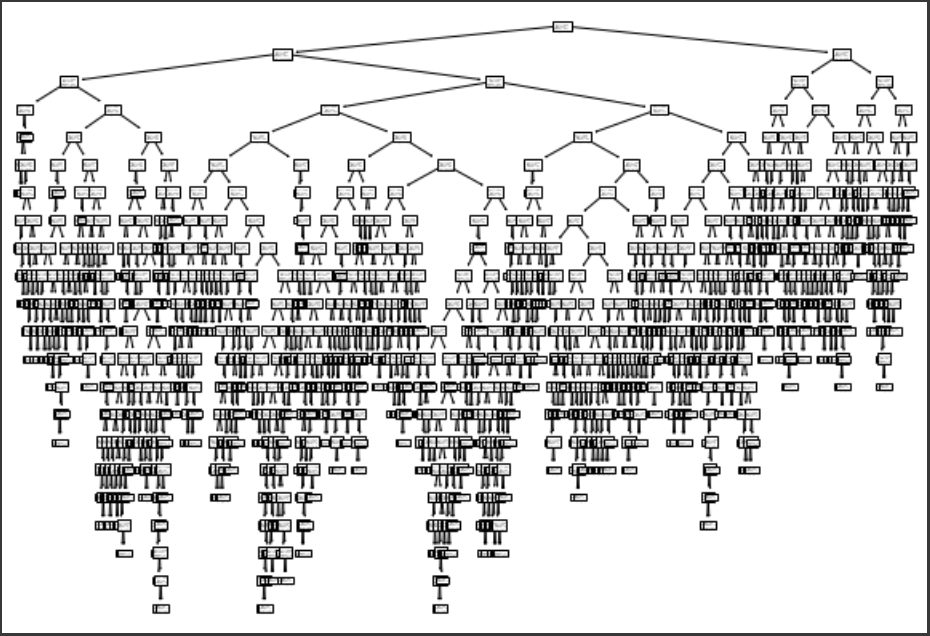
보다시피 트리가 너무 깊다 ! 이를 줄여보자.
# 최대 깊이 설정
plt.figure(figsize=(10, 7))
plot_tree(dt, max_depth=1, filled=True, feature_names=['alcohol', 'sugar', 'pH'])
plt.show()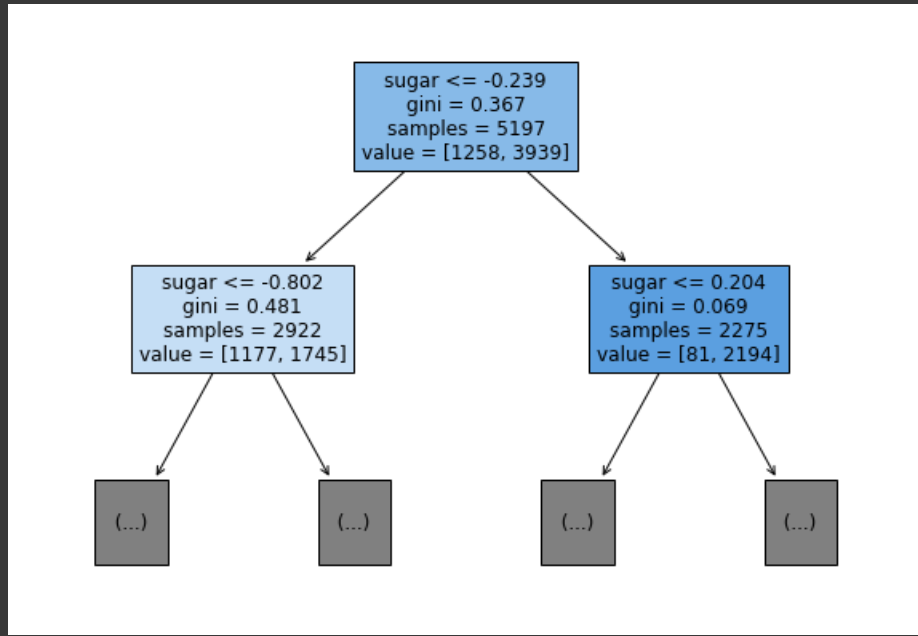
plot_tree 함수에서 max_depth 옵션을 지정해주니까 깊이 1 초과 노드들은 생략되었다.
filled 옵션은 노드의 색을 칠해주는데, 양성 클래스의 비율이 높을수록 진한 색이 된다.
feature_names 옵션은 노드에서 특성의 이름을 볼 수 있게 해준다.
지니 불순도
불순도 (gini)
DecisionTreeClassifier 클래스의 criterion 매개변수의 기본값.
5:5 클래스 비율이면 최악인 0.5,
단일 클래스로 이루어져 있는 노드면 최상인 0.
노드를 하나 내려갈 때마다 불순도의 차이는 다음과 같이 구한다.
이 수치를 정보 이득이라고 하고, 이 정보 이득이 최대가 되도록 클래스를 나누는 것이 트리 알고리즘이다.
criterion='entropy'를 이용해 엔트로피 불순도도 활용이 가능하다. 엔트로피 불순도는 제곱이 아니라 밑이 2인 로그를 취해 불순도를 구한다.
가지치기 (깊이 제한하기)
# 가지치기
dt = DecisionTreeClassifier(random_state=42, max_depth=3)
dt.fit(train_scaled, train_target)
print(dt.score(train_scaled, train_target))
print(dt.score(test_scaled, test_target))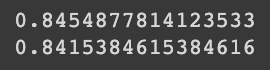
아까 있었던 과대적합 문제는 해소된 것 같다! 한 번 그려보자.
plt.figure(figsize=(20, 15))
plot_tree(dt, filled=True, feature_names=['alcohol', 'sugar', 'pH'])
plt.show()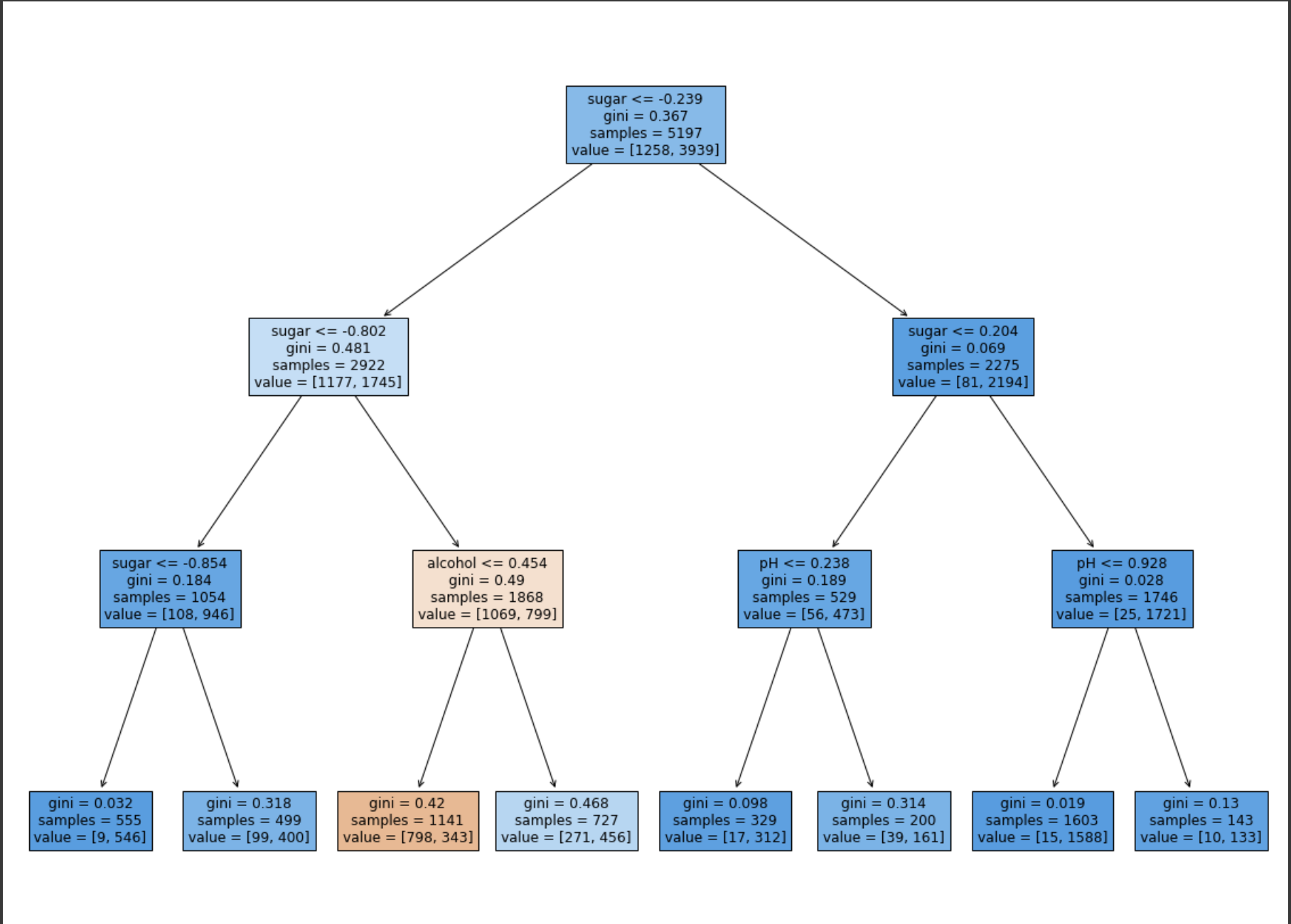
잘 보면 sugar 특성의 적정값이 음수가 나온다! 왜? 표준화 전처리를 했으니까. 따라서 트리 알고리즘에서는 표준화를 할 필요가 없다!
특성 중요도
그렇다면 특성 중에서 분류에 가장 큰 영향을 미치는 것은 무엇일까.
이 또한 코드로 알아볼 수 있다.
# 특성 중요도
print(dt.feature_importances_)
두 번째 특성인 당도가 화이트와인과 레드와인의 분류에 가장 큰 영향을 미친다는 것을 알 수 있다.
