📚 교차 검증
훈련 데이터와 테스트 데이터로 데이터를 나누어 모델을 훈련시키다 보면, 우리 모델의 성능 지표는 테스트 점수와 훈련 점수 밖에 없다.
따라서 실전에 잘 맞는 모델이 아니라 테스트 세트에 맞춰진 모델이 만들어질 수 있다.
이를 해결하기 위해서 교차 검증이라는 개념이 존재한다.
- 테스트 세트를 제외한 나머지 데이터를 다시 쪼개 검증 세트를 만든다.
- 남은 데이터로 훈련을 하고, 검증 세트로 점수를 본다.
- 검증 세트를 다시 훈련 데이터에 섞고, 다른 검증 세트를 이용한다.
- 반복한다.
- 마지막에만 테스트 세트를 써서 점수를 얻는다.
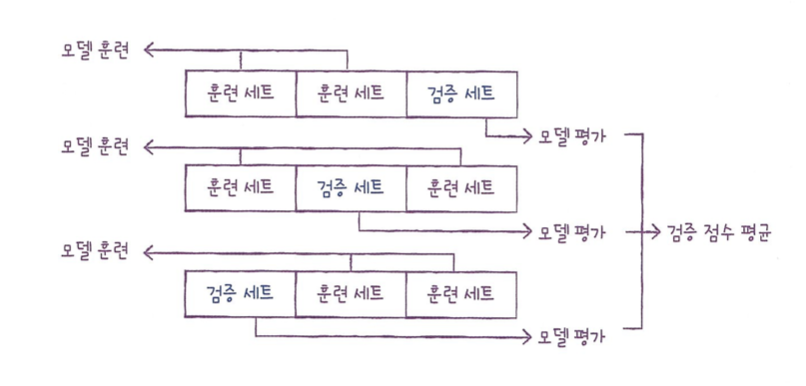
위 그림을 보면 이해에 도움이 될 것이다.
이 때 데이터를 나누는 단위를 폴드라고 한다. 위 그림의 경우 3-폴드 교차검증이 된다.
📊 실습
우선 데이터를 가져오자.
import pandas as pd
wine = pd.read_csv("https://bit.ly/wine-date")세트를 나누는 것은 cross_validate에 숫자를 주면 된다.
cross_validate 함수는 모델이 회귀면 KFold, 분류면 클래스가 동일하게 나눠져야 하므로 StratifiedKFold 함수를 이용해서 폴드를 나눈다.
간단한 트리를 만들어 교차검정을 해보자.
from sklearn.tree import DecisionTreeClassifier
dt = DecisionTreeClassifier(random_state=42)
from sklearn.model_selection import cross_validate
# cv 파라미터에 따라 k-겹 설정 가능
scores = cross_validate(dt, train_input, train_target, cv=5)
# 최종 점수 예상
import numpy as np
print(np.mean(scores['test_score']))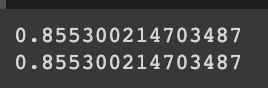
이 때 StratifiedKFold는 기본적으로 shuffle=False인데, 모든 데이터를 섞어서 폴드를 분할하고 싶으면 아래처럼 shuffle=True 옵션을 주면 된다.
splitter = StratifiedKFold(n_splits=10, shuffle=True, random_state=42)참고
[ 혼자 공부하는 머신러닝+딥러닝]
