
코랩 기본 세팅
# 배열
import numpy as np
# 데이터 분석
import pandas as pd
# Pandas option 정의
pd.set_option( 'display.max_columns', 20 )
pd.set_option( 'display.max_colwidth', 20 )
pd.set_option( 'display.unicode.east_asian_width', True )
# 시각화
import matplotlib.pyplot as plt
import seaborn as sns
# Jupyter note상에 그래프 결과 포함 매직 명령
%matplotlib inline
# Matplotlib 기본 글꼴 정의
plt.rc('font', size=14)
plt.rc('axes', labelsize=14, titlesize=14)
plt.rc('legend', fontsize=14)
plt.rc('xtick', labelsize=10)
plt.rc('ytick', labelsize=10)
import sys
# 노트북이 코랩에서 실행 중인지 체크합니다.
if 'google.colab' in sys.modules:
!echo 'debconf debconf/frontend select Noninteractive' | debconf-set-selections
# 나눔 폰트를 설치합니다.
!sudo apt-get -qq -y install fonts-nanum
import matplotlib.font_manager as fm
font_files = fm.findSystemFonts(fontpaths=['/usr/share/fonts/truetype/nanum'])
for fpath in font_files:
fm.fontManager.addfont(fpath)
## 나눔바른고딕 폰트로 설정합니다.
import matplotlib.pyplot as plt
plt.rc('font', family='NanumBarunGothic')
## 마이너스 기호 표시 오류 수정
import matplotlib
matplotlib.rcParams['axes.unicode_minus'] = False
# 경고 문제 출력 제한
import warnings
warnings.filterwarnings( 'ignore' )
# Tensorflow
import tensorflow as tf
tf.__version__
# Tensorflow Sequential model
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras import optimizers
from tensorflow.keras.utils import plot_model
# 데이터 분리를 위한 함수
from sklearn.model_selection import train_test_split
def disp_training( history ):
accuracy = history.history["accuracy"]
val_accuracy = history.history["val_accuracy"]
loss = history.history["loss"]
val_loss = history.history["val_loss"]
epochs = range( 1, len( accuracy ) + 1 )
plt.title( '훈련 및 검증 정확도' )
plt.plot( epochs, history.history[ 'accuracy' ], label = 'accuracy' )
plt.plot( epochs, history.history[ 'val_accuracy' ], label = 'val_accuracy' )
plt.grid()
plt.legend()
plt.xlabel( 'Epochs' )
plt.figure()
plt.title( '훈련 및 검증 오차' )
plt.plot( epochs, history.history[ 'loss' ], label = 'loss' )
plt.plot( epochs, history.history[ 'val_loss' ], label = 'val_loss' )
plt.grid()
plt.legend()
plt.xlabel( 'Epochs' )
plt.show()
def disp_loss( history ):
loss = history.history["loss"]
val_loss = history.history["val_loss"]
epochs = range( 1, len( loss ) + 1 )
plt.title( '훈련 및 검증 오차' )
plt.plot( epochs, history.history[ 'loss' ], label = 'loss' )
plt.plot( epochs, history.history[ 'val_loss' ], label = 'val_loss' )
plt.grid()
plt.legend()
plt.xlabel( 'Epochs' )
plt.show()단순 선형 회귀 모델
1. 데이터 준비 / 데이터 이해
# 입력 데이터 (공부시간)
X = np.array([1,2,3,4,5,6,7,8,9])
# 레이블 (점수)
y = np.array([11,22,33,44,53,66,77,87,95])
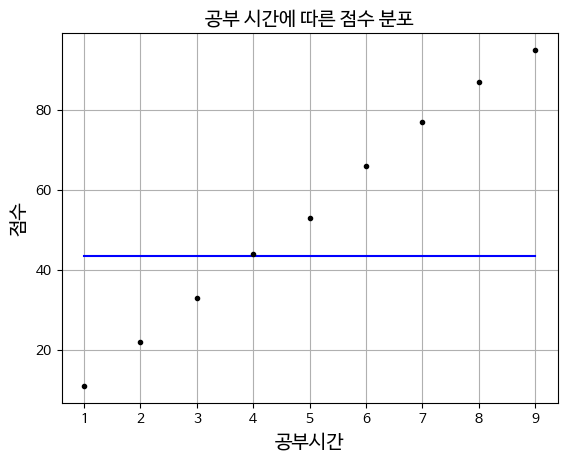
plt.plot (X,y, 'b', X,y, 'k.')
plt.title('공부 시간에 따른 점수 분포')
plt.xlabel('공부시간')
plt.ylabel('점수')
plt.grid()
plt.show()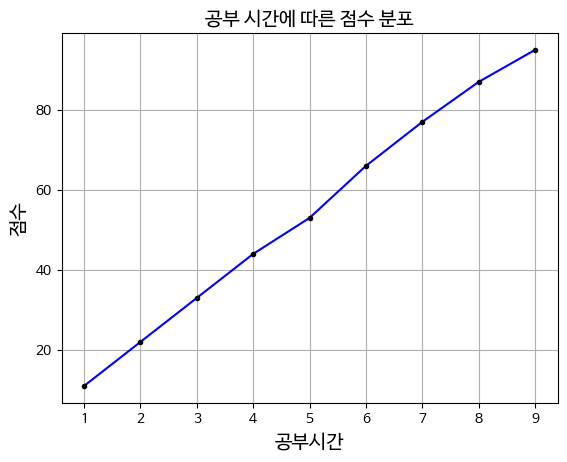
plt.plot (X,y, 'b', X,y, 'k.')
X와 y 데이터를 이용하여 그래프를 그리는 함수로 'b'는 파란색 선을 의미하고
'k.'는 검은색 점을 의미합니다
한번에 선과 점을 같이 그리는 코드입니다plt.grid()
그리드를 추가하여 그래프의 배치를 명확히 한다
2. 신경망 모델링
신경망 모델 생성 단계
model = Sequential()
model.add( Dense( 32, activation = 'relu', input_dim = 1 ) )
model.add( Dense( 1, activation = 'linear' ) )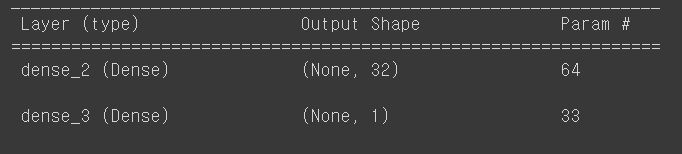
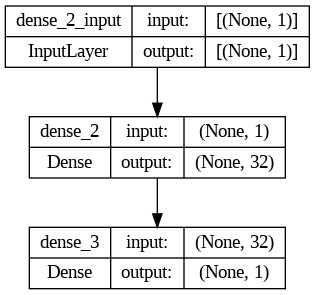
model.add()
모델에 레이어를 추가
Dense( 32, activation = 'relu', input_dim = 1 )
첫번째 인자는 뉴런의 갯수, activation은 활성화 함수를 의미
input_dim=1은 입력 데이터의 차원이 1임을 나타낸다
3. 모델 컴파일 및 훈련
sgd = optimizers.SGD(learning_rate=0.01)
model.compile(loss='mse', optimizer=sgd, metrics=['mse','accuracy'])
history = model.fit(X, y, epochs=100, batch_size=1,validation_split=0.2)
sgd = optimizers.SGD(learning_rate=0.01)
optimizer를 확률적 경사 하강법 (SGD)를 선택하여 가중치를 업데이트 한다
model.compile(loss='mse', optimizer=sgd, metrics=['mse','accuracy'])
model.compile()은 모델을 학습시키기 위해 컴파일하는 과정으로
loss ='mse'는 손실 함수로 평균제곱오차(MSE)를 의미한다
optimizer=sgd는 앞서 정의한 확률적 경사 하강법을 사용한다는 의미이고
metrics=['mse','accuracy']는 모델 평가 시 사용할 측정 지표를 지정합니다
model.fit(X, y, epochs=100, batch_size=1,validation_split=0.2)
model.fit은 모델을 학습시키는 함수로 X,y는 각각 입력 데이터와 레이블입니다
epochs은 학습시키는 횟수를 의미하고
batch_size=1가중치 업데이트마다 사용할 데이터 샘플의 수를 의미합니다
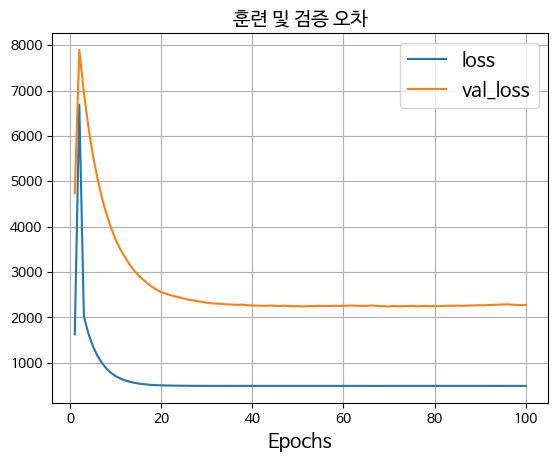
학습의 과정을 보면 overfitting이 많이 일어난 것을 볼 수 있다
학습이 잘 안되었다는 것인데
데이터의 수가 적어서 그런 것 같다overfitting : 그래프가 차이가 난다
4. 모델 평가
loss,mse,accuracy = model.evaluate(X,y)
print(f'평균 제곱 오차 :{mse:.3f}')
5. 예측
model.predict([0])
총평
훈련데이터로는 숫자 (실수,정수)만 사용할 수 있다
문자는 사용하지 못한다
직선을 이용하여 합격과 불합격을 구분하는데는 한계가 있다데이터를 섞을 때는 잘 섞어야 한다
데이터를 분리를 할 때는 처음 분리한 데이터를 그대로 사용해야 한
데이터 양이 많으면 overfitting 가능성이 줄어든다
적으면 데이터를 암기해버린다
검증정확도와 훈련정확도 중 보통 훈련정확도가 검증정확도보다 높다
또한 무조건 훈련횟수가 많다고 결과가 좋지는 않다

Shine like a star, Just like a star