-
이번에 예측 모델을 만들면서 Transformer encoder를 코드를 다시 공부하게 되었다. 정리해놓은 Hugging face의 Bert code를 저장한다. Self-attention에 대한 자세한 설명은 Jay Alammar의 Transformer를 참고하면 좋다.
-
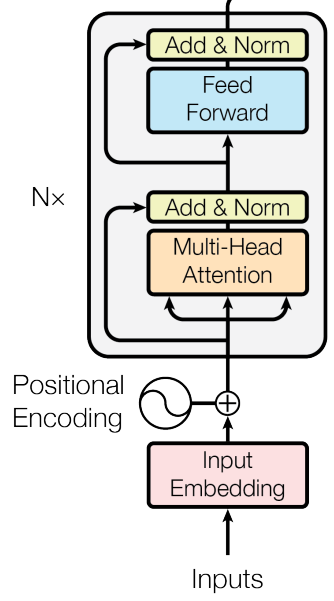
사용한 코드의 모델 구조는 아래 그림과 같다. 여기에서 (Encoder) layer를 1회 사용하고 Multi-Head Attention에 Masking을 추가한다.
-
Hugging Face 코드는 처음 보았을 때 '코드를 왜 이렇게 쪼개 놓았지?' 생각했는데 정리하면서 사용하기는 오히려 좋았다.
Self-Attention
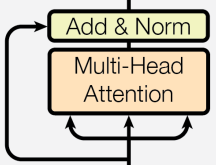
- 아래 SelfAttention 코드는 Multi-Head Attention을 수행한다. 주어진 num_attention_heads개 만큼 Attention 값을 구하고 를 곱해서 원래 차원으로 만드는 과정은 아래 SelfOutput에서 실행한다. (아래에서 사용한 position_embedding과 attention_mask는 개인적인 용도로 추가한 것으로 Transformer에서 사용하는 구조는 아니다.)
class SelfAttention(nn.Module):
def __init__(self, seq_len, hidden_size, num_attention_heads,
attention_probs_dropout_probs=0.1):
super().__init__()
# hidden_size % num_attention_head must be 0
self.seq_len = seq_len
self.hidden_size = hidden_size
self.num_attention_heads = num_attention_heads
self.attention_probs_dropout_probs = attention_probs_dropout_probs
self.attention_head_size = int(self.hidden_size / self.num_attention_heads)
self.all_head_size = self.num_attention_heads * self.attention_head_size
if self.hidden_size % self.num_attention_heads != 0:
raise ValueError(f'The hidden_size {self.hidden_size} is not a multiple of num_attention_head')
# Q = X * W^Q
# X: (batch_size, seq_len, hidden_size)
# W^Q: (hidden_size, hidden_size), same for W^Q, W^K, W^V
# Q: (batch_size, seq_len, hidden_size), same for Q, K, V
self.query = nn.Linear(self.hidden_size, self.all_head_size)
self.key = nn.Linear(self.hidden_size, self.all_head_size)
self.value = nn.Linear(self.hidden_size, self.all_head_size)
self.dropout = nn.Dropout(self.attention_probs_dropout_probs)
self.position_embedding = nn.Parameter(torch.Tensor(self.seq_len, self.hidden_size))
kaiming_normal_(self.position_embedding)
# multi-head attention 연산을 위해 Q, K, V를 num_atten_heads개로 분할하는 함수
# input x: (batch_size, seq_len, hidden_size)
def transpose_for_scores(self, x: torch.Tensor) -> torch.Tensor:
new_x_shape = x.size()[:-1] + (self.num_attention_heads, self.attention_head_size)
x = x.view(new_x_shape) # (batch_size, seq_len, num_atten_heads, atten_head_size)
return x.permute(0, 2, 1, 3) # (batch_size, num_atten_heads, seq_len, atten_head_size)
def forward(
self,
hidden_states: torch.Tensor,
attention_mask = None
) -> Tuple[torch.Tensor]:
# positional encoding
hidden_states = self.position_embedding + hidden_states
# Q, K, V 생성 (batch_size, seq_len, all_head_size)
mixed_query_layer = self.query(hidden_states)
mixed_key_layer = self.key(hidden_states)
mixed_value_layer = self.value(hidden_states)
# attention score을 계산하기 위해 size 변경
query_layer = self.transpose_for_scores(mixed_query_layer)
key_layer = self.transpose_for_scores(mixed_key_layer)
value_layer = self.transpose_for_scores(mixed_value_layer)
# QK^T / sqrt(d_k) 계산 과정
attention_scores = torch.matmul(query_layer, key_layer.transpose(-1, -2))
attention_scores = attention_scores / math.sqrt(self.attention_head_size)
# (batch_size, num_atten_head, seq_len, seq_len)
# Masked Multi-Head Attention에서 t(현재) 시점 이후의 영향력을 0으로 만들기 위한 masking
attention_mask = torch.ones(attention_scores.size())
attention_mask = torch.tril(attention_mask)
attention_mask[attention_mask == 0] = float('-inf')
attention_mask = attention_mask.to(device)
attention_scores = attention_scores + attention_mask
# softmax((QK^T) / sqrt(d_k))
attention_probs = nn.Softmax(dim=-1)(attention_scores)
attention_probs = self.dropout(attention_probs)
# softmax((QK^T) / sqrt(d_k)) * V
context_layer = torch.matmul(attention_probs, value_layer) # (batch_size, num_atten_heads, seq_len, attent_head_size)
context_layer = context_layer.permute(0, 2, 1, 3).contiguous() # (batch_size, seq_len, num_atten_heads, atten_head_size)
new_context_layer_shape = context_layer.size()[:-2] + (self.all_head_size, )
context_layer = context_layer.view(new_context_layer_shape) # (batch_size, seq_len, all_head_size)
# return context_layer
return context_layer- dense 과정(multiply )을 통해 context_layer를 묶어준 후에 Residual connection() & Layer Normalization()을 수행한다.
class SelfOutput(nn.Module):
def __init__(self, hidden_size, hidden_dropout_prob):
super().__init__()
self.hidden_size = hidden_size
self.hidden_dropout_prob = hidden_dropout_prob
self.dense = nn.Linear(self.hidden_size, self.hidden_size)
self.layernorm = nn.LayerNorm(self.hidden_size)
self.dropout = nn.Dropout(self.hidden_dropout_prob)
def forward(self, hidden_states: torch.Tensor, input_tensor: torch.Tensor) -> torch.Tensor:
hidden_states = self.dense(hidden_states)
hidden_states = self.dropout(hidden_states)
hidden_states = self.layernorm(hidden_states + input_tensor)
return hidden_states3. 위의 두 코드를 묶어준다. 여기서는 위 과정을 1회만 수행해서 layer chunk에 관한 코드를 제거했는데 원 방식대로 N회 수행할 경우 Hugging Face Bert의 chunk 관련 코드로 수정해주어야 한다.
class Attention(nn.Module):
def __init__(self):
super().__init__()
self.self = SelfAttention()
self.output = SelfOutput()
def forward(
self,
hidden_states,
attention_mask=None,
):
self_outputs = self.self(
hidden_states,
attention_mask,
)
# encoder block 단일 실행 -> xN 실행인 경우 HF 코드 추가
attention_output = self.output(self_outputs[0], hidden_states)
return attention_outputFFN
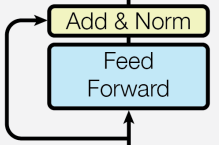
- Intermediate에서는 FeedForward의 과정인 를 수행한다. 차원을 확장시킨 후 다시 차원을 축소시키는 과정은 아래 Output에서 일어나며, 이후 Self-Attention에서 언급한 방법과 같은 Add&Norm을 수행한다.
class Intermediate(nn.Module):
def __init__(self, hidden_size, intermediate_size):
super().__init__()
self.hidden_size = hidden_size
self.intermediate_size = intermediate_size
self.dense = nn.Linear(self.hidden_size, self.intermediate_size)
self.relu = nn.ReLU()
def forward(self, hidden_states: torch.Tensor) -> torch.Tensor:
hidden_states = self.dense(hidden_states)
hidden_states = self.relu(hidden_states)
return hidden_statesclass Output(nn.Module):
def __init__(self, hidden_size, intermediate_size, hidden_dropout_prob):
super().__init__()
self.hidden_size = hidden_size
self.intermediate_size = intermediate_size
self.hidden_dropout_prob = hidden_dropout_prob
self.dense = nn.Linear(self.intermediate_size, self.hidden_size)
self.layernorm = nn.LayerNorm(self.hidden_size)
self.dropout = nn.Dropout(self.hidden_dropout_prob)
def forward(self, hidden_states: torch.Tensor, input_tensor: torch.Tensor) -> torch.Tensor:
hidden_states = self.dense(hidden_states)
hidden_states = self.dropout(hidden_states)
hidden_states = self.layernorm(hidden_states + input_tensor)
return hidden_states- 다시 위의 두 코드 블록을 묶어준다. 이후 Decoder를 추가하거나 FFN, LSTM등 자유롭게 output 과정을 설정해주면 된다.
class Layer(nn.Module):
def __init__(self):
super().__init__()
self.attention = Attention()
self.intermediate = Intermediate()
self.output = Output()
def forward(
self,
hidden_states,
attention_mask=None,
):
attention_output = self.attention(hidden_states)
intermediate_output = self.intermediate(attention_output)
encoder_output = self.output(intermediate_output, attention_output)
return encoder_outputTransformer | Jay Alammar
Hugging Face Github
Attention Is All You Need

까먹지 않기 위한 노트 (ว˙∇˙)ง