Intro.
이번에 처음으로 Optuna를 사용해보았다. 캐글러(Kaggler)들에겐 익숙한 자동화된 parameter tuning 방법이지만 범위만 지정해주면 빠르게 최적화된 parameter를 찾아준다는 것이 신기하면서도 믿기지 않았다. parameter space가 convex해서 쉽게 최적점을 찾을 수 있는 것도 아니고 굉장히 들쑥날쑥한데? 그래서 이론에 대해 찾아봤더니 Bayesian Optimization, Gauss process... 으아. 당장 공부할 여력이 없어 무작정 Grid Search를 짜서 비교해보았다. 이건 컴퓨터가 대신 해주니깐! 이참에 겸사겸사 찍어보는 XGB의 parameter 값들. parameter 조합을 2000개 쯤? 만들다보니 데이터의 사이즈가 너무 크면 안될 거 같아 sampling을 통해 사이즈를 조절해서 비교해보았으며 모두 cross-validation을 사용하였다.
Figure
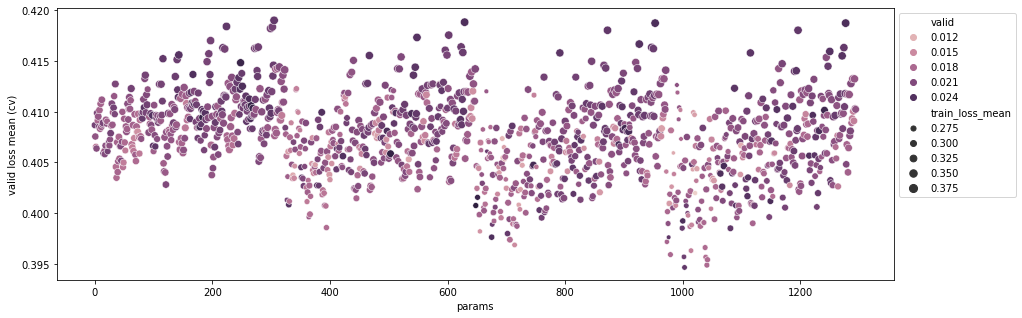
각 점은 하나의 parameter 조합을 나타낸다. 그림에 나타나는 4개의 클러스터는 max_depth의 차이에 의해 나타난다. (max_depth가 boosting에서 왜 중요한 parameter인지 확인할 수 있다.) 특히 가장 왼쪽 클러스터의 경우 점 색이 전체적으로 짙고(validation set의 loss std가 큼) 점의 크기가 큰 것(train set의 loss mean이 큼)을 통해 전체적으로 underfitting이 나타나는 것으로 보인다. 적절한 tree depth에 도달해감에 따라 옅은 색의 작은 점들이 나타나는 것을 확인할 수 있으며 train loss의 평균도 작아지고 validation std도 작아지는 것을 알 수 있다.
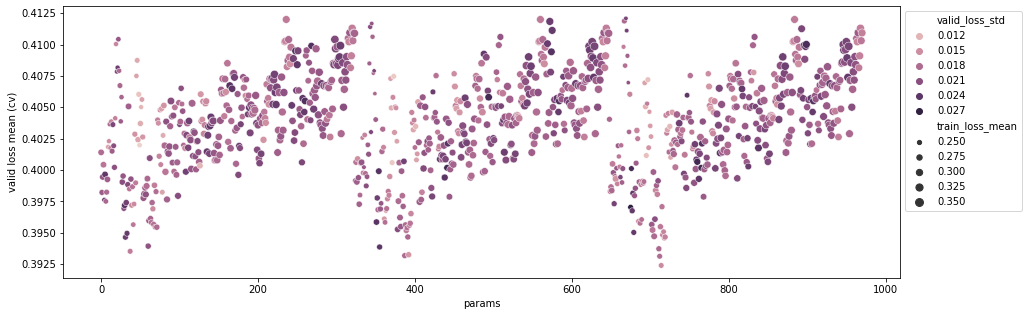
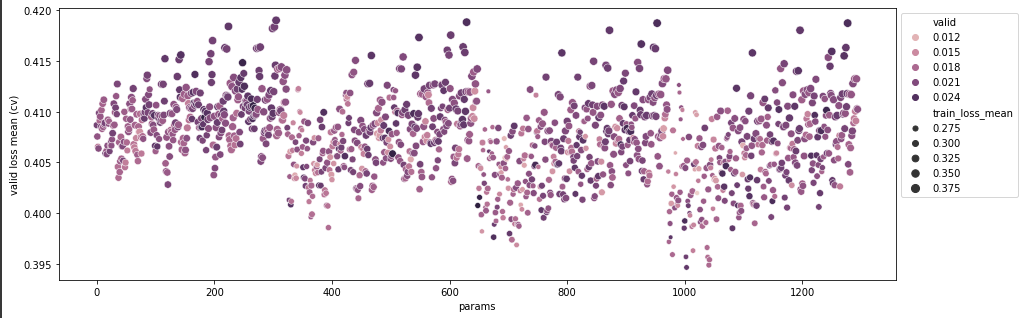
각 클러스터의 앞 부분(x축이 약 50, 400, 700 대)에서 validation loss std와 train loss mean이 작은 것에 비해 validation loss mean이 튀는 현상을 발견할 수 있는데 이는 sampling을 통해 dataset을 줄인 상태에서 subsample parameter를 너무 크게 설정해서 나타난 현상이다. 각 클러스터가 우상향하는 모습은 regularization에 따른 변화로 lamda와 alpha의 조합으로 나타난다. 우측으로 갈 수록 점이 커지는 모습을 통해 적절치 않은 regularization 또한 모델에 영향을 주는 것을 확인할 수 있다.
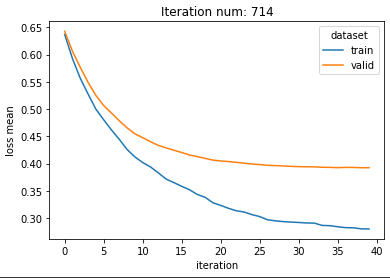
validation loss mean이 가장 작게 나타나는 parameter로 learning curve를 그려보니 iteration에 따라 underfitting이나 overfitting 현상이 나타나지 않는 것을 확인할 수 있다. (early_stopping 사용)
그래서 Optuna는 좋았다? 좋았다!
두 방법에서 최적화된 parameter를 통해 비교해본 결과 모든 sampling dataset에서 결과가 거의 차이 나지 않았다!
XGB는 tuning해 줘야할 parameter가 많다보니 각 파라미터의 값을 3~5개만 지정해도 금방 2천개가 넘어버린다. 그러다보니 sampling을 통해 데이터셋의 크기를 작게 잡아도 전체적인 비교에는 시간이 꽤나 소모된다. 반면 Optuna는 실행 수(n_trials)를 100번 안쪽으로 잡아도 준수한 성능이 나온다. (여기에 callback 함수를 통한 pruning까지 더하면 시간이 많이 줄어든다.) 짧은 경험을 통해 성능과 시간 둘 모두의 측면에서 Optuna가 꽤나 매력적인 선택지라는 생각이 들었다.
