5개의 컴퓨터를 사용해서 Hadoop 클러스터를 해봤다.
🚩 기초 설치, 환경변수 (Java, Hadoop)
1. Hadoop (3.3.1)
curl -o /usr/local/hadoop-3.3.1.tar.gz https://downloads.apache.org/hadoop/common/hadoop-3.3.1/hadoop-3.3.1.tar.gz
mkdir -p /usr/local/hadoop && sudo tar -xvzf /usr/local/hadoop-3.3.1.tar.gz -C /usr/local/hadoop --strip-components 1
rm -rf /usr/local/hadoop-3.3.1.tar.gz
chown -R $USER:$USER /usr/local/hadoop-3.3.12. Java
sudo apt-get install openjdk-8-jdk -y3. 환경변수
- ~/.bashrc
os 또는 개개인에 따라 JAVA_HOME 경로가 다를 수 있음.
필자는 centos 2개랑 ubuntu 3개로 구성되어 있음.
JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
HADOOP_HOME=/usr/local/hadoop
YARN_CONF_DIR=$HADOOP_HOME/etc/hadoop
HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export JAVA_HOME HADOOP_HOME YARN_CONF_DIR HADOOP_CONF_DIR
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:$HADOOP_HOME/lib/native
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin- 환경변수 적용
source ~/.bashrc4. hosts 설정
- /etc/hosts
xxx.xxx.xxx.xxx master
xxx.xxx.xxx.xxx worker1
xxx.xxx.xxx.xxx worker2
xxx.xxx.xxx.xxx worker3
xxx.xxx.xxx.xxx worker45. ssh 접속 설정
> sudo apt-get install openssh-server -y
> sudo service ssh start
> ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
> cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
> chmod 0600 ~/.ssh/authorized_keys모든 서버의 ~/.ssh/id_rsa 내용을 다 합쳐서 각 서버의 ~/.ssh/authorized_keys에 추가해야함
그리고 master서버에서는 ssh worker1 ... ssh worker4 까지 한번씩 다 해야한다. 처음에 yes이런거 뜨는데 두번째부터는 어떤한 입력도 없이 바로 ssh접속이 가능. 그리고 스스로에 대한 접속도 해봐야한다. ssh master(자기자신). 이러고 나면 known_hosts에 기록이 남는다. (자기자신도 한번 접속 해야 하는거 모르고 한참을 ...)
🚩 hadoop 설정
모든 서버에 설정. 하나의 서버에 설정을 끝마치고 일괄 scp 같은 것으로 다른서버에 넘겨주는 방법이 있긴하다.
- $HADOOP_HOME/etc/hadoop/core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
</configuration>- $HADOOP_HOME/etc/hadoop/hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/usr/local/hadoop/data/namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/usr/local/hadoop/data/datanode</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>worker1:50090</value>
</property>
</configuration>- $HADOOP_HOME/etc/hadoop/yarn-site.xml
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce_shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
</configuration>- $HADOOP_HOME/etc/hadoop/mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
</configuration>- hadoop-env.sh
환경변수와 별개로 JAVA_HOME을 못잡는 경우가 있어서 여기에도 추가해준다.
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root- $HADOOP_HOME/etc/hadoop/workers
worker1
worker2
worker3
worker4🚩 Hadoop 실행
- Master에서만 실행하면 된다.
- worker노드에는 datanode 디렉토리를 생성해놔야함 (/usr/local/hadoop/data/datanode)
$HADOOP_HOME/bin/hdfs namenode -format -force
$HADOOP_HOME/sbin/start-dfs.sh
$HADOOP_HOME/sbin/start-yarn.sh
$HADOOP_HOME/bin/mapred --daemon start historyserver첫번째줄 실행명령후에 shutdown 뭐시기가 뜨는데 문제 없는거니 넘어가면된다.
2022-04-27 17:14:49,115 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at master/xxx.xxx.xxx.xxx
************************************************************/
두번째줄 실행명령 후 / icns-216은 필자 설정에 따른 이름이고 위에 대로하면 worker1이 뜰것이다.
$HADOOP_HOME/sbin/start-dfs.sh
Starting namenodes on [master]
Starting datanodes
Starting secondary namenodes [icns-216]
세번째줄 실행 후
HADOOP_HOME/sbin/start-yarn.sh
WARNING: YARN_CONF_DIR has been replaced by HADOOP_CONF_DIR. Using value of YARN_CONF_DIR.
Starting resourcemanager
Starting nodemanagers
worker3: WARNING: YARN_CONF_DIR has been replaced by HADOOP_CONF_DIR. Using value of YARN_CONF_DIR.
그러고 나서 <master server의 ip>:9870 로 가서 위쪽에 Datanodes를 들어가면 총 4개의 Datanode가 떠 있는 것을 확인할 수 있다. 안뜨면 설정이 잘못된것이니 확인해야한다.
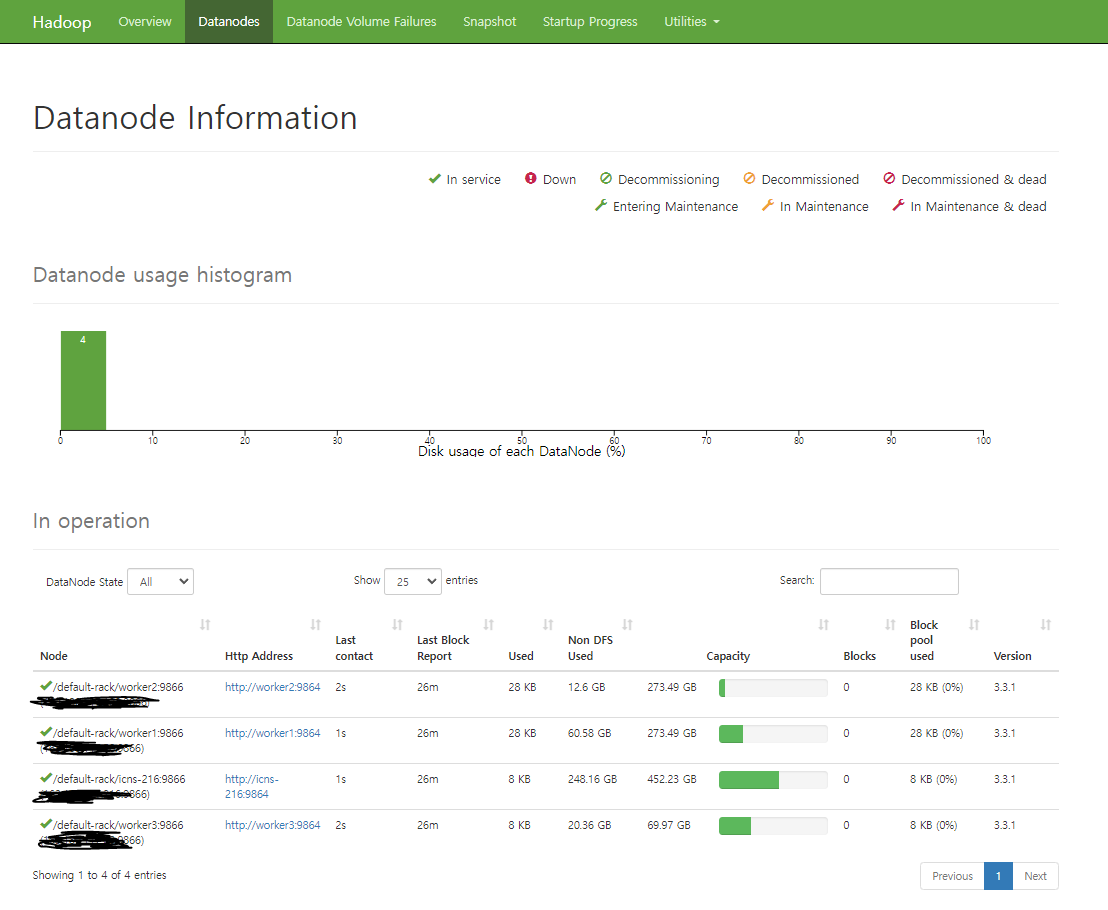
NameNode (http://master:9870)
ResourceManager (http://master:8088)
MapReduce JobHistory Server (http://master:19888)
🚩 Hadoop 종료
Master 노드에서만 수행하면 된다.
$HADOOP_HOME/sbin/stop-dfs.sh
$HADOOP_HOME/sbin/stop-yarn.sh
$HADOOP_HOME/bin/mapred --daemon stop historyserver
rm -rf $HADOOP_HOME/data/namenode/*모든 Datanode에서는
rm -rf $HADOOP_HOME/data/datanode/*