클러스터링
1.Hadoop Cluster
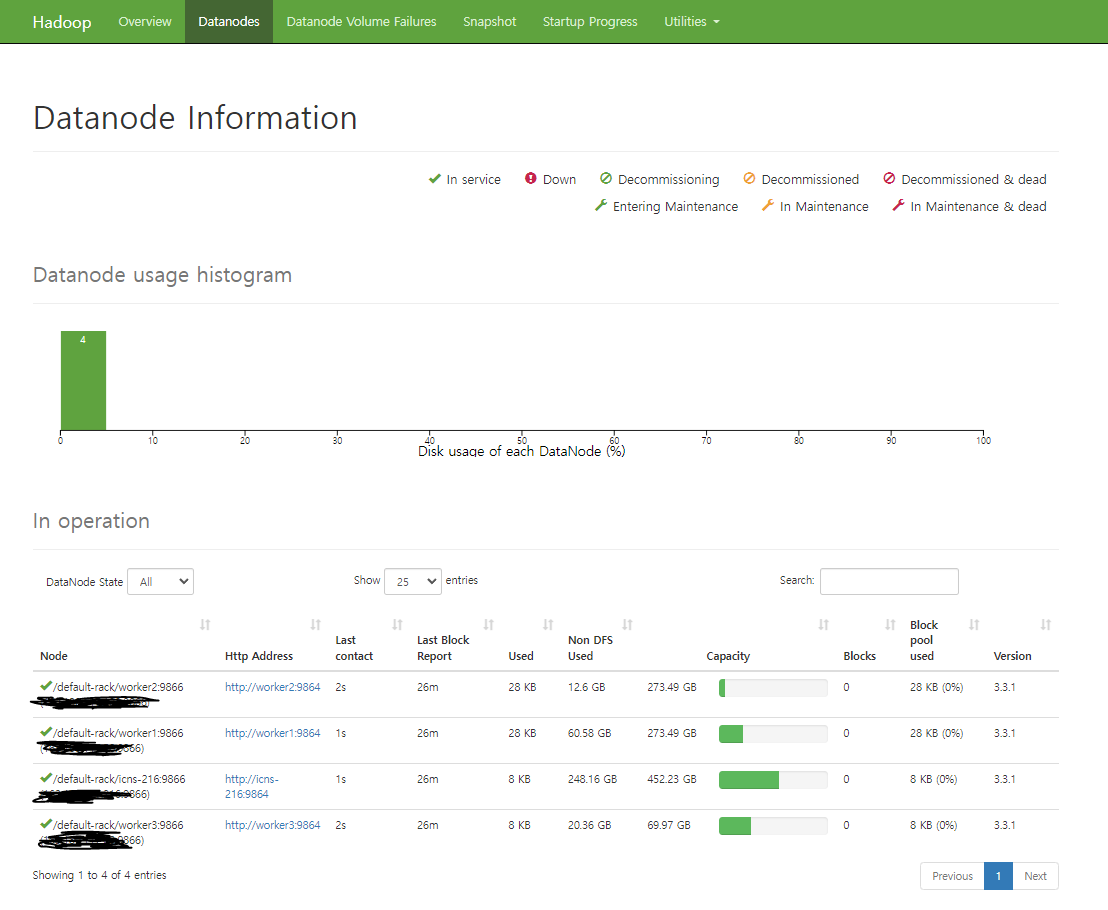
5개의 컴퓨터를 사용해서 Hadoop 클러스터를 해봤다. 1\. Hadoop (3.3.1)2\. Java3\. 환경변수~/.bashrc환경변수 적용4\. hosts 설정/etc/hosts 5\. ssh 접속 설정모든 서버의 ~/.ssh/id_rsa 내용을 다 합쳐서 각
2022년 4월 27일
2.Spark cluster
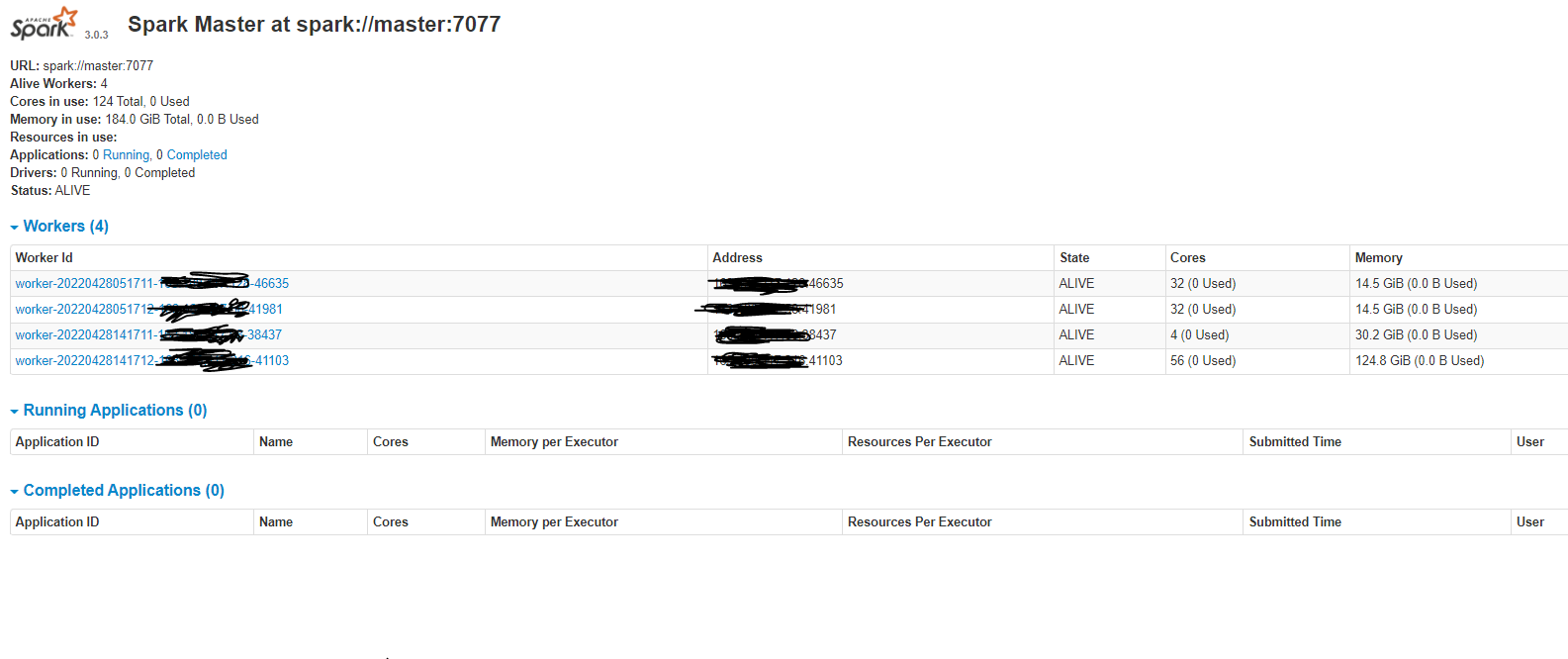
하둡 클러스터링이 완료됬다는 전제하에 진행한다.https://velog.io/@kidae92/Hadoop-Cluster ~/.bashrc환경변수 적용$SPARK_HOME/conf/slaves$SPARK_HOME/conf에 가보면 slaves를 포함한 모든 파일
2022년 4월 28일