문서가 가지는 단어를 문맥, 순서 상관 없이 단어에 빈도값을 부여해 feature를 추출하는 모델

But. 순서를 고려하지 않기에 문장의미를 나타낼 수 없음
(n_gram 사용해도 제한적)
But. 100개의 문장을 Bow모델로 처리 한다고 가정을 하면 단어의 개수가 기하급수적으로 늘어남
-> Null값이 많이 발생함(희소행렬 문제)
Bow의 피처 벡터화 방식
1. Count기반 벡터화
각 문서에서 해당 단어가 나타나는 횟수를 부여함
횟수가 높을 수록 중요한 단어로 인식
중요하지 않으나 자주 사용하는 단어까지 중요한 값이라고 인식 할 수 있음
벡터화 방법
1. 데이터 전처리 작업(소문자 변경...)
2. n_gran_range를 반영하여 토큰화
3. 텍스트 정규화(Stop word, lemmatize..)
4. feature 벡터화
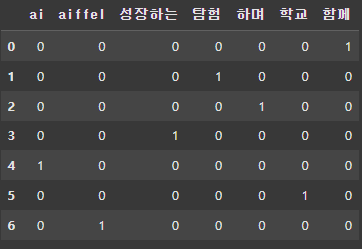
from sklearn.feature_extraction.text import CountVectorizer
text = "함께 탐험하며 성장하는 AI 학교 AIFFEL"
vect = CountVectorizer()
# 단어 토큰화 Okt
words = tokenizer.morphs(text)
# 데이터 학습
vect.fit(words)
# 학습된 어휘
vect.get_feature_names_out()

pd.DataFrame(df_t.toarray(), columns = vect.get_feature_names_out())
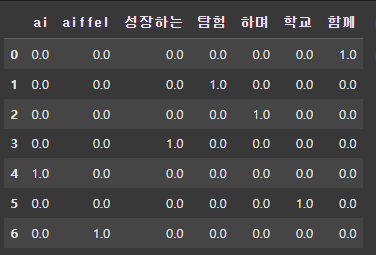
2. TF-IDF
- 개별 문서에서 자주 나타나는 단어 높은 가중치를 부여
- 모든 문서에서 자주 나타나는 단어에는 페널티를 부여함
ex) '분쟁', '종교 대립' 등의 단어가 자주 나타난다면 해당 문서는 지역 분쟁과 관련된 문서일 확률이 존재
ex) '많은', '빈번하게', '업무'등의 단어는 문서의 특징과는 관련이 없으나 보편적으로 많이 사용되기에 해당 단어를 중요도가 높다고 평가하는 경우 무슨 문서인지를 모르게 됨
Bow 벡터화의 경우 필연적으로 많은 feature가 존재(n_gram을 사용하면 더 많아짐)
-> Bow형태를 가진 언어모델의 피처 벡터화는 대부분 희소 행렬임
해당 문제를 해결하기 위해 COO, CSR 사용
from sklearn.feature_extraction.text import TfidfVectorizer
text = "함께 탐험하며 성장하는 AI 학교 AIFFEL"
vect = TfidfVectorizer()
words = tokenizer.morphs(text)
vect.fit(words)
vect.vocabulary_

pd.DataFrame(vect.transform(words).toarray(), columns = vect.get_feature_names_out())
희소 행렬
행렬의 대부분의 값이 0인 경우
COO
0이 아닌 데이터만 별도의 데이터 배열에 저장하고 해당 데이터의 행과 열의 위치를 별도의 배열로 저장하는 방식
ex) [[3, 0 ,1], [0, 2, 0]]
0이 아닌 데이터의 행,열은 (0, 0), (0, 2), (1, 1)
[0, 0, 1], [0, 2, 1]
from scipy import sparse
import numpy as np
dense = np.array( [ [ 3, 0, 1 ], [0, 2, 0 ] ] )
data = np.array([3,1,2])
row_pos = np.array([0,0,1])
col_pos = np.array([0,2,1])
# 희소 행렬 생성
sparse_coo = sparse.coo_matrix((data, (row_pos, col_pos)))
CSR
COO의 문제점을 해결 한 방식
ex) 행 위치 리스트는 0부터 순차적으로 증가 하기에 [0, 0, 1, 1, 1, 1, 1, 2, 2, 3] 반복되는 숫자가 존재함
-> 메모리 낭비
이러한 문제를 줄이고자 반복되는 값의 시작인덱스를 기록 [0, 2, 7, 9]
0의 시작 인덱스 번호 0 / 1의 시작 인덱스 번호 2..
마지막에는 데이터의 총 개수를 추가함
최종 = [0, 2, 7, 9, 10]
from scipy import sparse
dense2 = np.array([[0,0,1,0,0,5],
[1,4,0,3,2,5],
[0,6,0,3,0,0],
[2,0,0,0,0,0],
[0,0,0,7,0,8],
[1,0,0,0,0,0]])
# 0이 아닌 데이터 추출
data2 = np.array([1, 5, 1, 4, 3, 2, 5, 6, 3, 2, 7, 8, 1])
# 행, 열위치 array로 생성
row_pos = np.array([0, 0, 1, 1, 1, 1, 1, 2, 2, 3, 4, 4, 5])
col_pos = np.array([2, 5, 0, 1, 3, 4, 5, 1, 3, 0, 3, 5, 0])
# COO 형식으로 변환
sparse_coo = sparse.coo_matrix((data2, (row_pos,col_pos)))
# 행 위치 배열의 고유한 값들의 시작 위치 인덱스를 배열로 생성
row_pos_ind = np.array([0, 2, 7, 9, 10, 12, 13])
# CSR 형식으로 변환
sparse_csr = sparse.csr_matrix((data2, col_pos, row_pos_ind))
