앞 과정에서 시계열 분해를 통해 Trend, Seasonality, Residual로 분해 됨
만약 분리가 잘 된경우 Residual가 안정성이 존재하는 데이터가 됨
해당 원리를 이용하여 ARIMA를 통해 시계열 예측 모델을 만들 수 있음
ARIMA
AR + I + MA
AR(자기 회귀)
과거 값들의 대한 회귀로 미래를 예측
Residual 부분 모델링
주식값이 항상 일정한 균형 수준을 유지할 것이라고 예측하는 관점이 바로 주식 시계열을 AR로 모델링하는 관점
I(차분 누적)
이전 데이터와 d차 차분 누적의 합
Seasonlity 부분 모델링
MA(이동 평균)
Trend 부분 모델링
주식값이 최근의 증감 패턴을 지속할 것이라고 보는 관점이 MA로 모델링하는 관점
위의 총 3가지 관점을 통해 2가지의 AR, MA 사이에서 적정한 값을 찾아감
ARIMA Parameter
p : AR(자기 회귀)의 시차
d : I(차분 누적) 횟수
q : MA(이동 평균)의 시차
일반적으로 p or q 하나는 0임
>> 많은 시계열 데이터가 AR, MA중 하나의 특성만 가짐
ARIMA Parameter 적정 값 찾기
적절한 Parameter을 고르기 위한 방법으로 ACF, PACF가 존재
ACF
시차(Lag)에 따른 두 변수 사이의 모든 관련성을 측정
MA모델의 q 결정
PACF
다른 변수의 영향력을 배제하고 두 시차의 변수의 관련성만 측정
AR모델의 p 결정
from statsmodels.graphics.tsaplots import plot_acf, plot_pacf
plot_acf(ts_log) # ACF : Autocorrelation 그래프 그리기
plot_pacf(ts_log) # PACF : Partial Autocorrelation 그래프 그리기
plt.show()
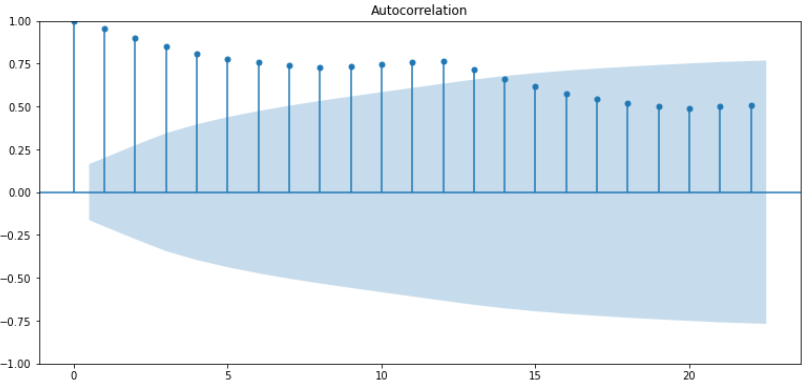
ACF에서 q는 점차 감소하고 있기에 1에 유사하지만 적절하다고는 설명하지 못함
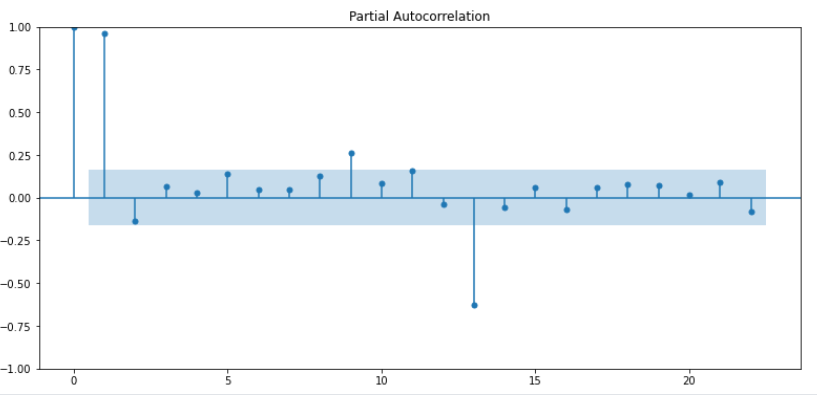
PACF에서 p가 2 이상인 구간에 거의 0에 가까워지고 있기 때문에 p의 경우 1이 적합함
0이면 아무런 상관도 없는 데이터
d차 차분을 구한 이후 안정된 상태인지 확인해야함
# 1차 차분 구하기
diff_1 = ts_log.diff(periods=1).iloc[1:]
diff_1.plot(title='Difference 1st')
augmented_dickey_fuller_test(diff_1)
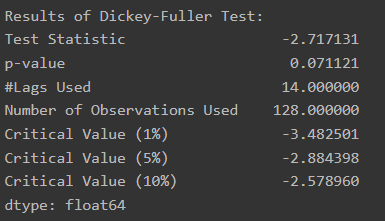
p-value 0.07
# 2차 차분 구하기
diff_2 = diff_1.diff(periods=1).iloc[1:]
diff_2.plot(title='Difference 2nd')
augmented_dickey_fuller_test(diff_2)
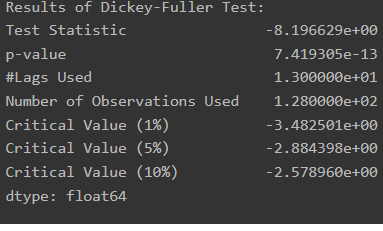
확실히 1차 차분에 비해 안정된 모습이나 d값을 변경해가며 확인해봐야함
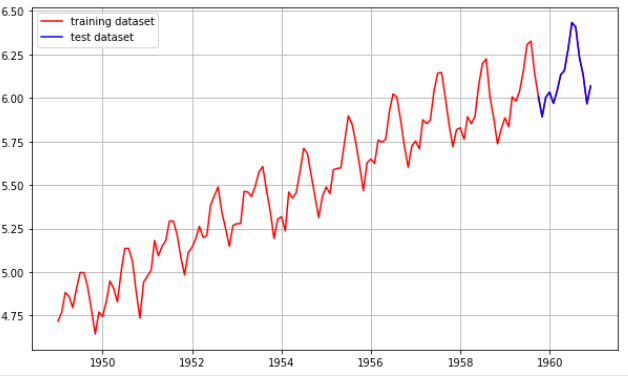
학습 데이터 분리
train_data, test_data = ts_log[:int(len(ts_log)*0.9)], ts_log[int(len(ts_log)*0.9):]
plt.figure(figsize=(10,6))
plt.grid(True)
plt.plot(ts_log, c='r', label='training dataset') # train_data를 적용하면 그래프가 끊어져 보이므로 자연스러운 연출을 위해 ts_log를 선택
plt.plot(test_data, c='b', label='test dataset')
plt.legend()