ARIMA 모델 훈련
import warnings
warnings.filterwarnings('ignore')
from statsmodels.tsa.arima.model import ARIMA
# Build Model
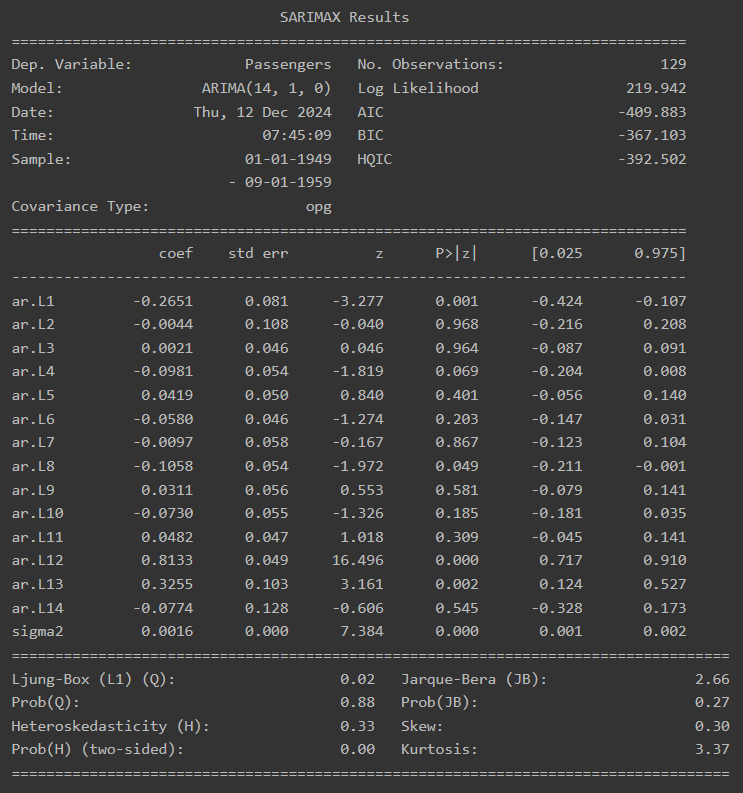
model = ARIMA(train_data, order=(14, 1, 0))
fitted_m = model.fit()
print(fitted_m.summary())
fitted_m = fitted_m.predict()
fitted_m = fitted_m.drop(fitted_m.index[0])
plt.plot(fitted_m, label='predict')
plt.plot(train_data, label='train_data')
plt.legend()
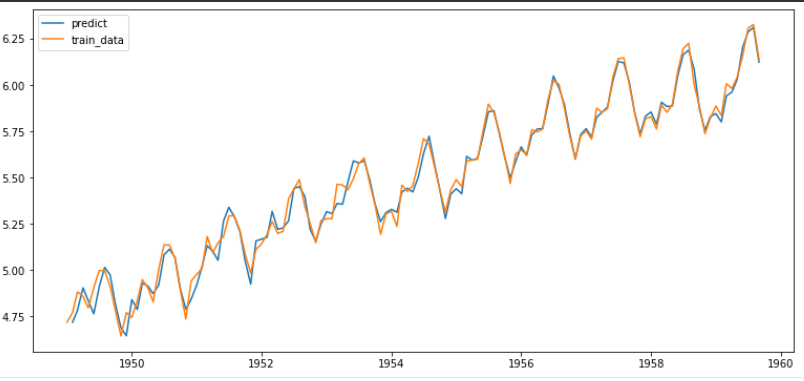
Model Prediction
model = ARIMA(train_data, order=(14, 1, 0)) # p값을 14으로 테스트
fitted_m = model.fit()
fc= fitted_m.forecast(len(test_data), alpha=0.05)
fc_series = pd.Series(fc, index=test_data.index)
# Plot
plt.figure(figsize=(9,5), dpi=100)
plt.plot(train_data, label='training')
plt.plot(test_data, c='b', label='actual price')
plt.plot(fc_series, c='r',label='predicted price')
plt.legend()
plt.show()
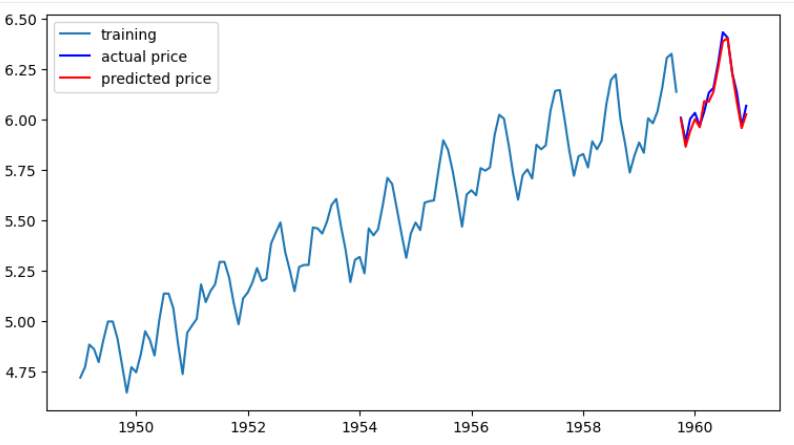
예측을 성공한 모습
Log변환을 하여 사용하였기에 오차 계산을 위해 원본 데이터 복원
from sklearn.metrics import mean_squared_error, mean_absolute_error
import math
mse = mean_squared_error(np.exp(test_data), np.exp(fc))
print('MSE: ', mse)
mae = mean_absolute_error(np.exp(test_data), np.exp(fc))
print('MAE: ', mae)
rmse = math.sqrt(mean_squared_error(np.exp(test_data), np.exp(fc)))
print('RMSE: ', rmse)
mape = np.mean(np.abs(np.exp(fc) - np.exp(test_data))/np.abs(np.exp(test_data)))
print('MAPE: {:.2f}%'.format(mape*100))
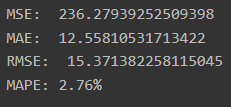
MAPE 기준 2%의 오차율을 나타내고 있음
