Random Forest
같은 알고리즘으로 여러개의 분류기(배깅)를 만들어서 최종 결정
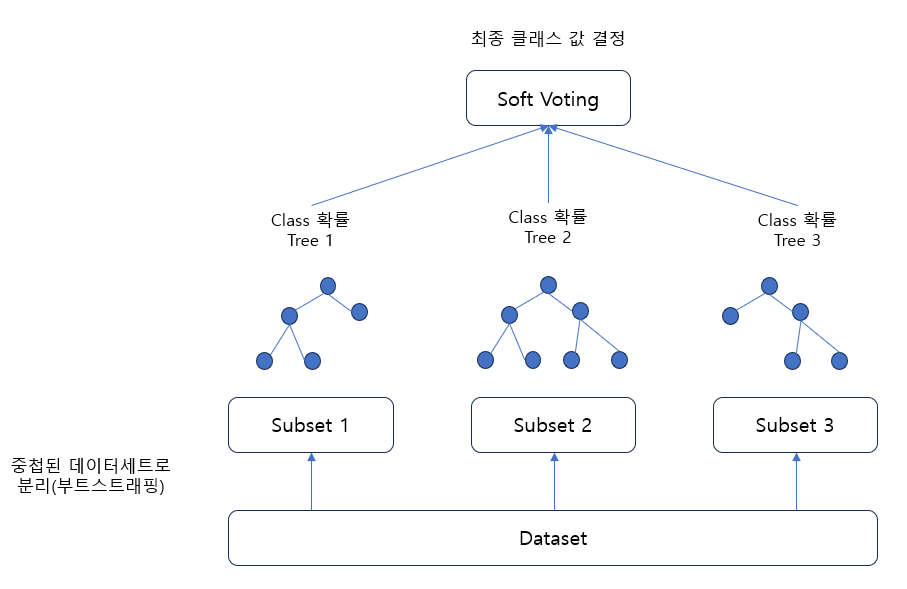
분류기에 제공하는 데이터 세트를 중첩되게 분리(부트스트래핑)
- CPU 병럴 처리가 효과적이기에 빠른 학습이 가능함
parameter
n_estimators(Default = 100) : 트리 개수
criterion(Default : gini) : 불순도 지표(다른방식 : 엔트로피 이용 정보 지수)
max_depth(Default : None) : 최대 깊이
min_samples_split(Default : 2) : 자식 노드를 갖기 위한 최소 데이터 수
min_samples_leaf(Default : 1) : 리프 노드가 되기 위한 최소 샘플 수
예제
from sklearn.ensemble import RandomForestClassifier
model = RandomForestClassifier(
n_estimators = 200,
max_depth = 3,
random_state = 0
)
model.fit(x_train, y_train)
pred = model.predict(x_test)
accuracy_score(y_test, pred)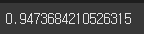
번외(GridSearchCV적용)
from sklearn.model_selection import GridSearchCV
params = {
'n_estimators':[100],
'max_depth' : [6, 8, 10, 12],
'min_samples_leaf' : [8, 12, 18 ],
'min_samples_split' : [8, 16, 20]
}
# RandomForestClassifier 객체 생성 후 GridSearchCV 수행
rf_clf = RandomForestClassifier(random_state=0, n_jobs=-1)
grid_cv = GridSearchCV(rf_clf , param_grid=params , cv=2, n_jobs=-1 )
grid_cv.fit(X_train , y_train)
print('최적 하이퍼 파라미터:\n', grid_cv.best_params_)
print('최고 예측 정확도: {0:.4f}'.format(grid_cv.best_score_))