
⌨ 코드카타
-
Recyclable and Low Fat Products
-
Find Customer Referee
.
.
python 라이브세션
(지난시간 복습(개인실습) 이후 내용만 작성)
🔻🔻🔻
2-4.(컬럼별)테이블 결측치 확인하기
df.isna().sum() 또는
df.isnull().sum()
2-5. 특정 컬럼 1개 가져오기
- 자주 사용하는 방법
df['user id']-> user id 컬럼만 가져와진다.
-iloc 이용하기
df.iloc[4]와df.iloc[:4] 의 차이 ..!
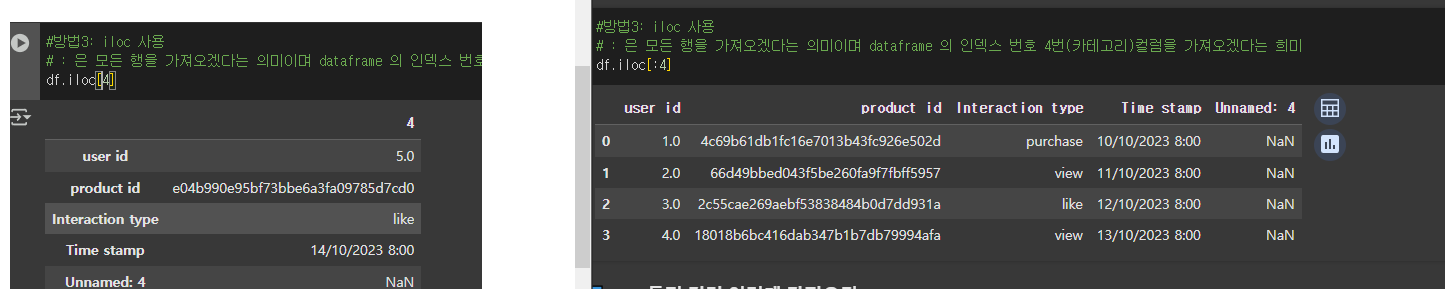
그냥 4번째 인덱스 데이터를 가져올 것인지,
모든 행(가로)을 dataframe의 인덱스 번호 4번까지 가져올 것인지..!
2-6. 특정 컬럼 여러개 가져오기
df[ ]2-5에서 썼던 것 처럼, []를 이용하되, 컬럼명들을 []안에 한번 더 넣어주기.
2.iloc
- : 은 모든 행(가로)을 가져오겠다 =>
df.iloc[:] - dataframe 의 인덱스 번호 4번,7번 컬럼을 가져오겠다 =>
df.iloc[[4,7]]
2-7.특정 컬럼 버리기
df3.drop('Brand Name', axis=1, inplace=True)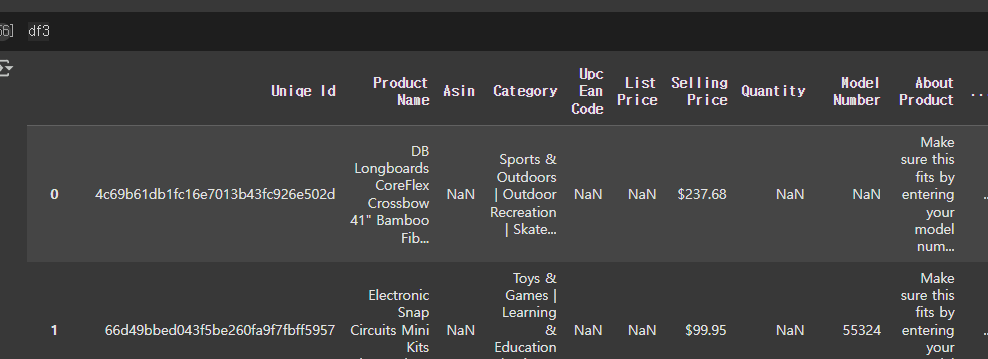
진 짜 컬 럼 버 림
inplace=False로 바꿨어야 했는데...!!! (추후 다시 복구해놓음..)
.
🔻False로 바꾸고 다시 실행한 결과를 원본과 비교해봤다.

2-8.조건에 부합하는 데이터 가져오기 1
- ➰조건에 만족하는 행은 정상출력 ,아닌 행은 NaN 으로 반환
df2.where(df2['Age']>50)
이 코드가 sql이었다면,,?
select *
from df2
where age>50이렇다.
여기서, 궁금증💭
이미 df2.를 처음에 명시했는데도 불구하고, where( ) 안에 df2['Age']라고 df2를 다시 명시해줘야하는 이유가 뭐지..?
먼저, where ()의 동작 방식을 이해할 필요가 있다.
where() 함수는 불리언 마스크(참/거짓으로 이루어진 배열)를 인자로 받아, True인 위치의 값을 유지하고 False인 위치의 값을 NaN으로 변환하는 함수
( ) 괄호 안에 있는, df2['Age'] > 50는 df2의 Age 열에서 각 행이 50보다 큰지 여부를 나타내는 불리언 시리즈를 생성.
❌ df2 없이 where()만 호출할 경우:
df2 = df2[df2['Age']>50]
TypeError: '>' not supported between instances of 'list' and 'int'가 뜬다.
=>문자열 Age에 대해 > 연산을 수행하려고 해서 비교 연산 오류가 발생💥
df2를 다시 명시해야 하는 이유는 where()가 불리언 마스크(참/거짓 판별용 시리즈)를 기대하기 때문이다.
즉, df2['Age'] > 50을 명시적으로 적어야 where()가 원하는 형태의 데이터를 받을 수 있다.
🔴
df2.query("Age > 50")로도 작성해줄 수 있다
.
.
-
➰조건을 만족하는 행만 필터링 하고 싶다면 ?
#데이터프레임명[조건] 사용 !!!
ex.df2 = df2[df2['Age']>50]
. -
조건에 부합하는 데이터 가져오기2
mask
# 조건에 부합하는 데이터만 가져오고 싶을 때
mask = ((df2['Age']>50) & (df2['Gender']=='Male'))
df2[mask]2-9. 테이블 그루핑
다음과 같은 SQL쿼리를
select Gender, count(Customer ID)
from df2
group by Gender🔻 Python으로 구현한다면~?
이정도는 외워주면 좋음💡💡💡
df2.groupby('Gender')['Customer ID'].count()그룹바이 순서 어떻게 하냐에 따라 결과 달라짐!!💥
df2.groupby(['Gender','Location'])['Customer ID'].count()유일한 값, 고유한 값에 대한 추가 정리
🔹nunique()
:nunique()는 데이터에 고유값들의 수
🔹value_coutns()
:value_counts()는 값별로 데이터의 수를 출력해주는 함수
.
🤷♀️ unique도 있는 것 같던데, nunique랑 뭐가 달라?
🔻🔻🔻
🔹unique()
:데이터에 고유값들이 어떠한 종류들이 있는지 알고 싶을때 사용
2-10. 정렬 (order by 느낌 ~)
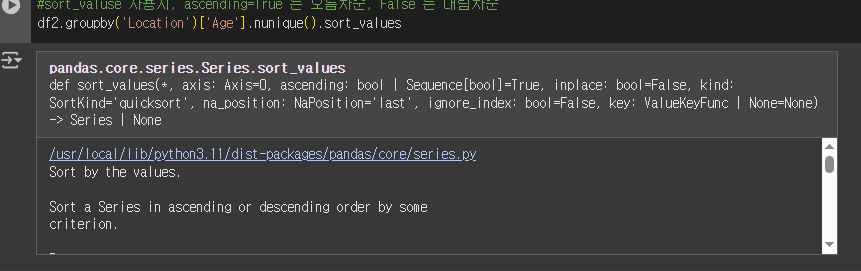
.sort_values(ascending=False)
ascending=True 는 오름차순, False 는 내림차순
(ascending=False) 꼭 써야하나? 해봤는데,
안써도 잘 된다 !
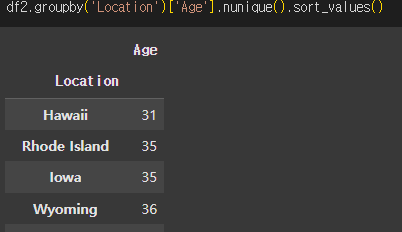
🤔❌근데 처음엔
안됐었다...?!
앞으로도 비슷한 문제가 생긴다면,
1️⃣ Series인지 확인 (type())
type(df2.groupby('Location')['Age'].nunique())Series라면 (pandas.core.series.Series)
→ .sort_values()를 사용할 수 있어야 하고, ascending=True 생략이 가능해야 함.
DataFrame이라면 (pandas.core.frame.DataFrame)
→ .sort_values()가 다르게 동작할 수 있고, 명시적으로 ascending을 넣어야 할 수도 있음.
2️⃣ 데이터가 정상적인지 확인 (print(result))
result = df2.groupby('Location')['Age'].nunique()
print(result)3️⃣ 데이터 타입 체크 (dtype)
print(result.dtype)=> 정수형(int64)이나 실수형(float64)이면 정상적으로 정렬 되어야한다.
.
.
.
데이터 전처리&시각화
- VS Code(Jupytor Notebook, Python) 설치
- 1 & 2주차 수강
느낀점&회고
라이브세션에서 배운 코드들이 꽤나 많고 다양한 시도를 해볼 수 있는 것 같아서 ,
import pandas as pd 부터 새로 쫙 복습해봤다.
의도하지는 않았지만... 그대로 코드를 복붙할 수 없게 파일을 불러와서(😮!!) 손으로 타이핑+여러 Error 구글링 해본게 이해하는데 큰 도움이 된 것 같다. 시간도 많이 썼지만, 아깝지 않다 !
그리고 . . 앞으로도 꾸준히 해서 감 잃지 말아야지ㅣ......감 찾아요 감.......🍅
