pima 인디언들이 50년대 이후로 당뇨병 발생률이 50%가 넘었다고 한다. 그렇기에 머신러닝을 통해 무엇이 가장 큰 문제였는지 알아보려고 한다.
데이터
pima 인디언에 대한 데이터는 kaggle에도 있으며 나는 PinkWink github에서 데이터를 따왔다.
import pandas as pd
pima_url = 'https://raw.githubusercontent.com/PinkWink/ML_tutorial/master/dataset/diabetes.csv'
pima = pd.read_csv(pima_url)
pima.head()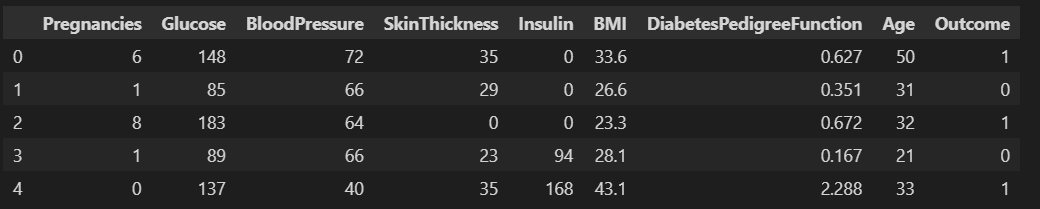
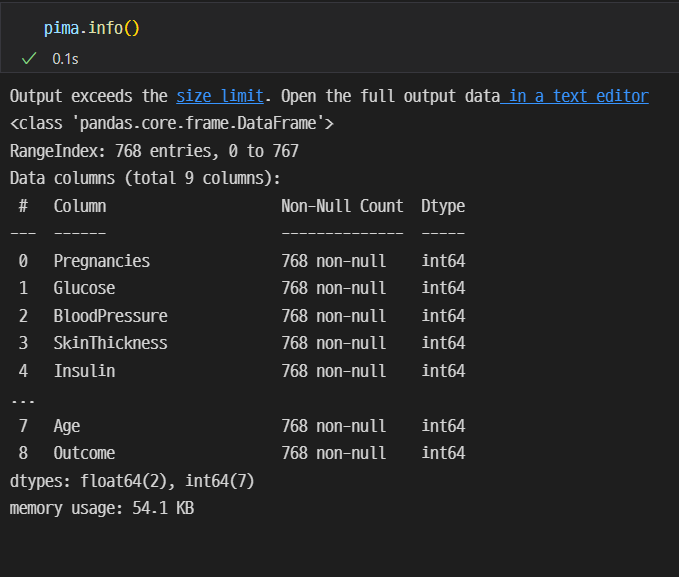
pima 데이터 정보확인
pina.info()를 활용한다.
정수 int형 데이터를 실수형 float형태로 변환해준다..
pima =pima.astype('float')히트맵으로 요인알아보기
import seaborn as sns
import matplotlib.pyplot as plt
%matplotlib inline
plt.figure(figsize=(12,10))
sns.heatmap(pima.corr(),cmap = 'YlGnBu')
plt.show()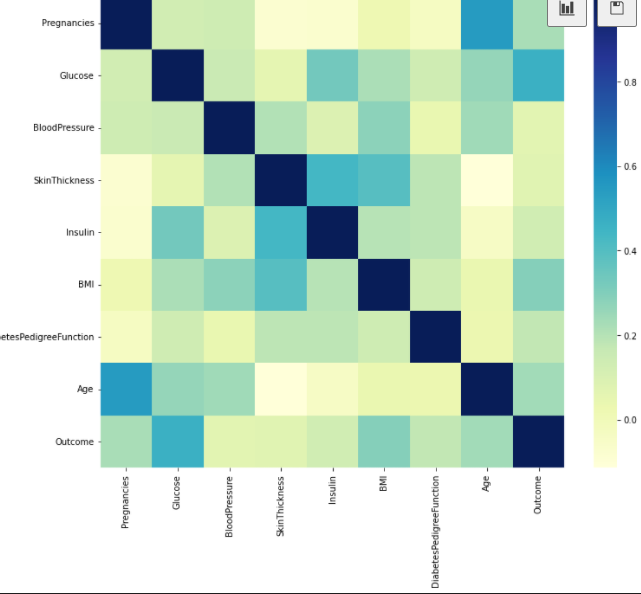
데이터를 확인해보면 혈압이 0인 데이터가 있다. 이건 문제가 된다.
(pima==0).astype(int).sum()왜 이렇게 나올까?
: 방법이 없기에 의학적 지식과 pima인디언에 대한 정보가 없으므로 일단 평균값으로 대체해준다.!
zero_features = ['Glucose','BloodPressure','SkinThickness','BMI']
pima[zero_features]=pima[zero_features].replace(0, pima[zero_features].mean())
(pima ==0).astype(int).sum()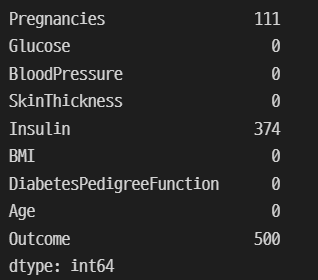
머신러닝 구현하기 위한 사전 단계
x = pima.drop(['Outcome'],axis =1)
y = pima['Outcome']
x_train,x_test,y_train,y_test = train_test_split(x,y,test_size=0.2,
stratify= y,
random_state=13
)from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
estimators = [('scaler', StandardScaler()),
('clf',LogisticRegression(solver='liblinear',random_state=13))]
pipe_lr = Pipeline(estimators)
pipe_lr.fit(x_train,y_train)
pred = pipe_lr.predict(x_test)이를 통해 accuracy,recall,precision,acu score,f1 score의 각각의 수치를 확인해보자.
from sklearn.metrics import accuracy_score,recall_score,precision_score,roc_auc_score,f1_score그러기 위해서는 각 코드를 import로 불러 사용할 수 있게끔 만든다.
print('accuracy :',accuracy_score(y_test,pred))
print('recall :',recall_score(y_test,pred))
print('precision :',precision_score(y_test,pred))
print('acu score :',roc_auc_score(y_test,pred))
print('f1 score :',f1_score(y_test,pred))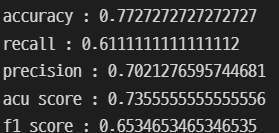
생각보다 높은 값이 나왔다.
다변수 방정식의 각 계수 값을 확인해보자.
coef = list(pipe_lr['clf'].coef_[0])
labels = list(x_train.columns)labels를 확인해보면
['Pregnancies',
'Glucose',
'BloodPressure',
'SkinThickness',
'Insulin',
'BMI',
'DiabetesPedigreeFunction',
'Age']
확인할 수 있다.
데이터프레임으로 쉽게 알아보도록 만들기.
features = pd.DataFrame(
{'Features': labels,'importance':coef}
)
features.sort_values(by=['importance'], ascending=True, inplace=True)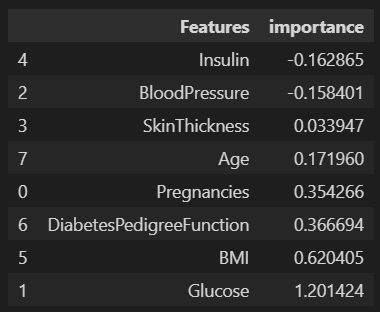
features['positive'] = features['importance']>0
features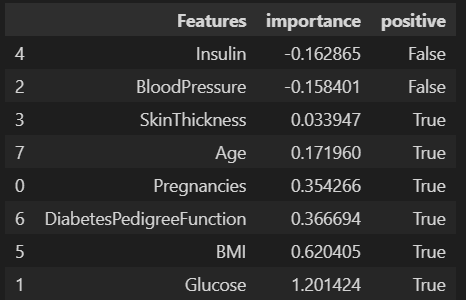
필요한 정보를 얻었으니 무엇이 가장 높은 요인이였는지 살펴보자.
features.set_index('Features', inplace=True)
features['importance'].plot(kind='barh',figsize=(11,6),color =features['positive'].map({True:'blue', False:'red'}))
plt.xlabel('importance')
plt.show()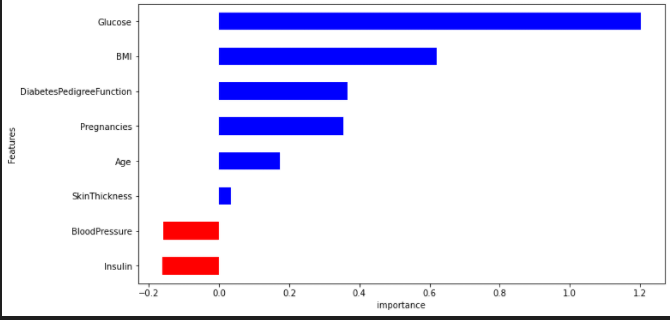
가장 높은 요인은 Glucose인 것을 확인할 수 있었다.

문과생 데이터사이언티스트되기 프로젝트