머신러닝
1.머신러닝 Decision Tree
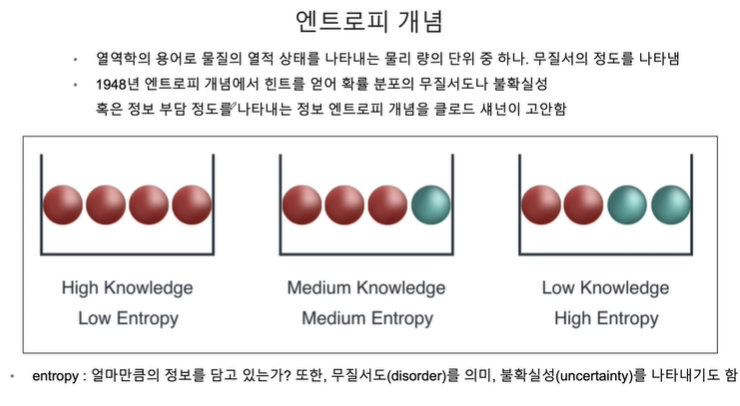
split criterion정보의 가치를 반환하는 데 발생하는 사전의 확률이 작을수록 정보의 가치는 커진다. 정보 이득이란 어떤 속성을 선택함으로 인해서 데이터를 더 잘 구분하게 되는 것.엔트로피 값은 작을수록 데이터를 잘 수집한 모뎀이라고 볼 수 있다. 엔트로피 값을
2.머신러닝을 활용한 타이타닉 탑승자별 생존율
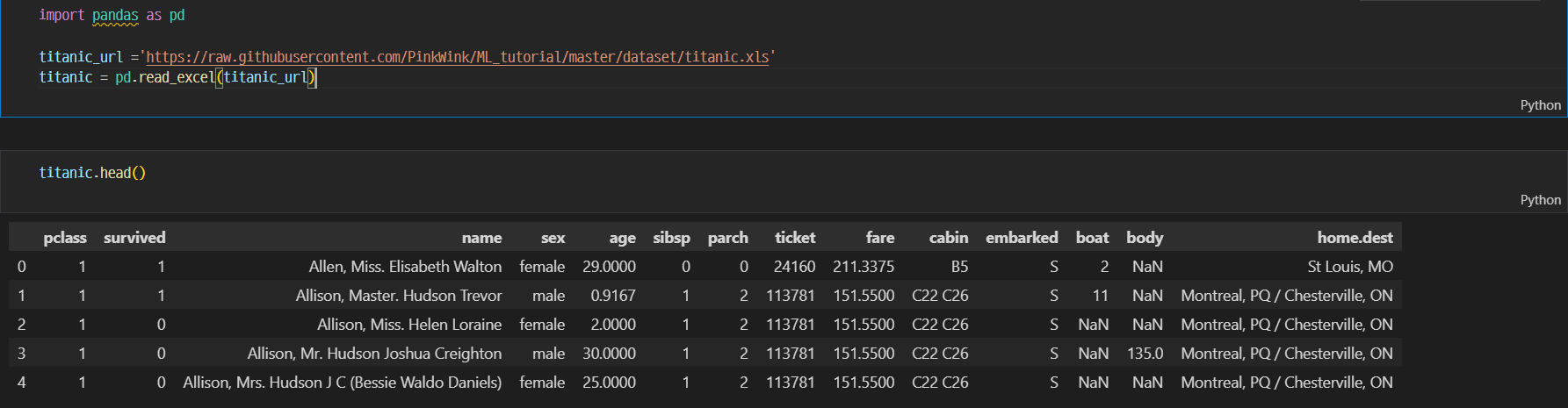
우선 타이타닉의 표본 데이터를 가져온다.PinkWink 내 타이타닉 데이터다운받은 타이타닉 데이터를 vs code를 이용하여 연 이후 pd.read_excel을 통해 타이타닉 데이터가 잘 들어갔는지 확인한다.matplotlib와 seaborn을 사용해야 하기 때문에 i
3.ROC곡선
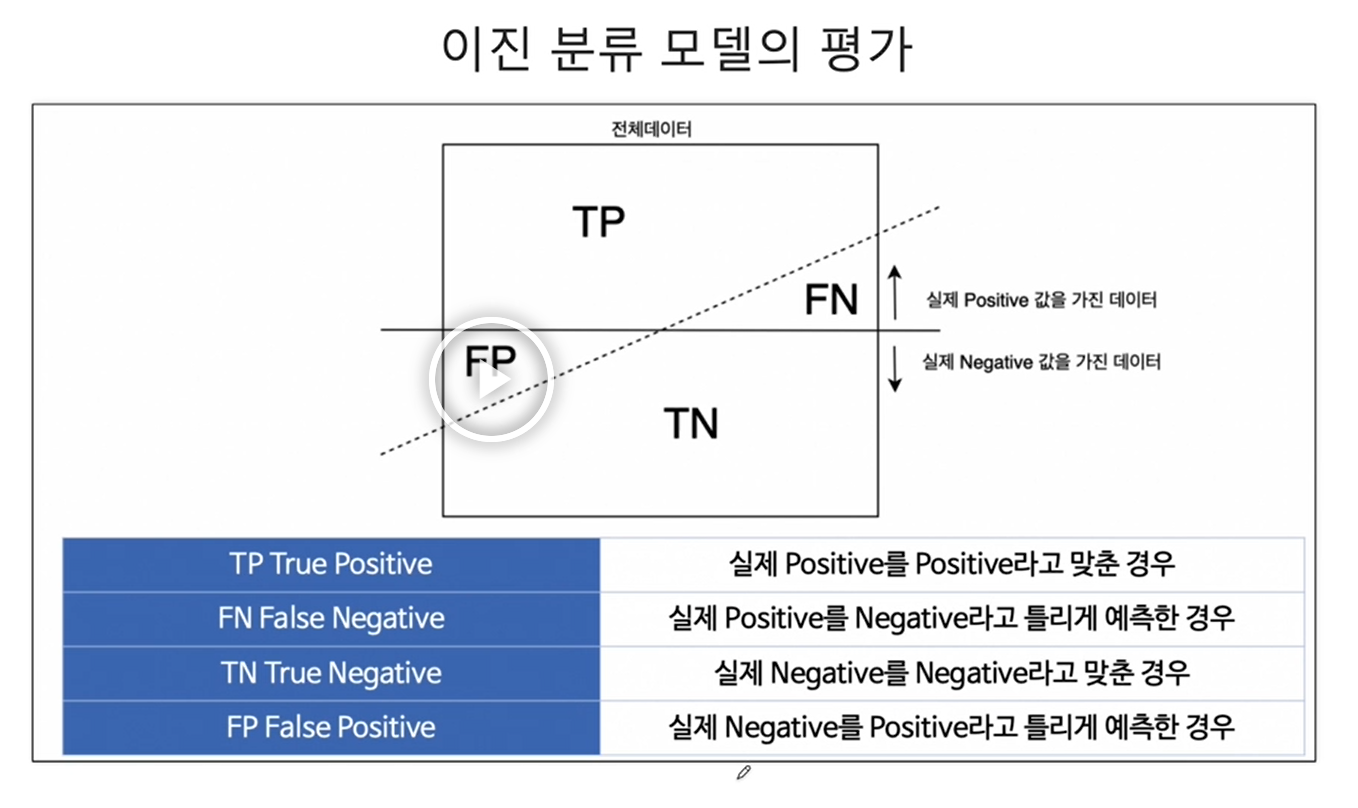
: 전체 데이터 중 맞힌 비율(TP + TN + FP + FN) / (TP + TN): 참이라고 예측한 것 중에 실제 참의 비율(TP + FP) / TP: 참인 데이터 중에서 참이라고 예측한 것(TP + FN) / TP: 실제 참이 아닌데, 잘못 예측한 경우(FP +
4.화이트 와인과 레드 와인 비교
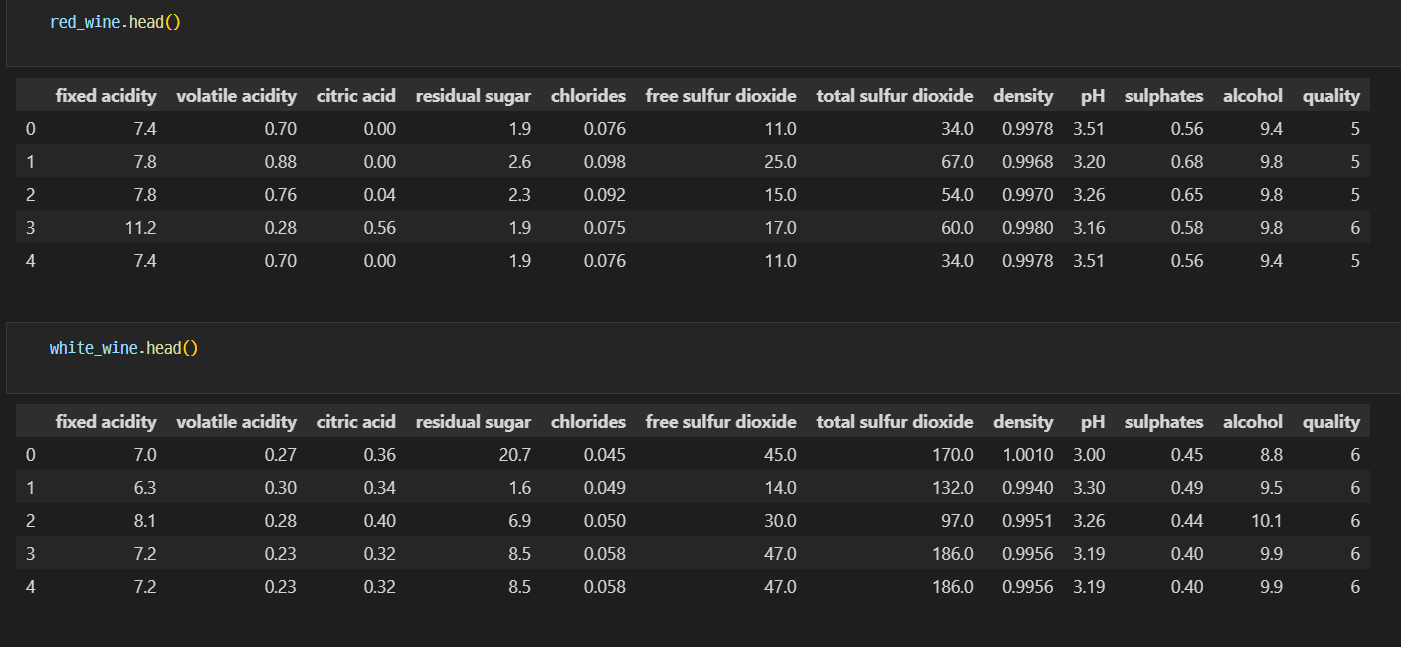
화이트 와인과 레드 와인을 맛과 퀄리티에 따라 비교해보려고 한다.우선 화이트,레드 와인의 정보는 pinkwink님의 사이트에서 추출했다.import pandas as pd를 기본으로 기입해주고 시작했다.우선 vs code에서 읽을 수 있도록 각 데이터를 pd.read_
5.PIMA 인디언 당뇨병 예측
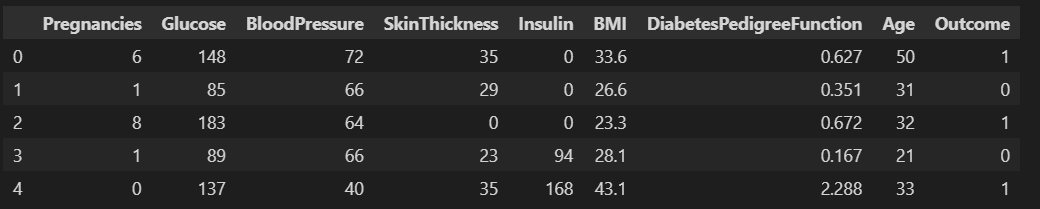
pima 인디언들이 50년대 이후로 당뇨병 발생률이 50%가 넘었다고 한다. 그렇기에 머신러닝을 통해 무엇이 가장 큰 문제였는지 알아보려고 한다.pima 인디언에 대한 데이터는 kaggle에도 있으며 나는 PinkWink github에서 데이터를 따왔다.pina.inf
6.영화 추천시스템

추천 알고리즘을 이용하여 영화를 추천해주는 머신러닝을 작성했다.영화 '대부'를 바탕으로 유사도를 검사이후 추천한다.우선 기본적으로 영화 데이터는 해당 사이트에서 다운받았다. pandas와 numpy 모듈을 불러온다.movies에는 csv파일을 읽을 수 있겠끔 작성해준다
7.운동 분석 AI 경진대회

프로젝트 노션기본 사전 정보:3축 가속도계3축 자이로스코프(스마트 헬스케어 산업에 적용 가능한 데이터 분석 방법 제시운동 분석 데이터를 통해 머신러닝 구현!\[](https://velog.velcdn.com/images/kim_haesol/post/251483