추천 알고리즘을 이용하여 영화를 추천해주는 머신러닝을 작성했다.
영화 '대부'를 바탕으로 유사도를 검사이후 추천한다.
1. 데이터 수집
우선 기본적으로 영화 데이터
는 해당 사이트에서 다운받았다.
import pandas as pd
import numpy as nppandas와 numpy 모듈을 불러온다.
movies = pd.read_csv('https://raw.githubusercontent.com/PinkWink/ML_tutorial/master/dataset/tmdb_5000_movies.csv')
print(movies.shape)movies에는 csv파일을 읽을 수 있겠끔 작성해준다.
이후 movies.head()를 통해 어떤 데이터가 들어가 있는지 확인해준다.

너무 많은 정보가 들어가 있는 것을 볼 수 있다..
그렇기에 내가 필요로 하는 정보들만 다시 뽑아서 확인해보자
movies_df =movies[['id','title','genres','vote_average','vote_count','popularity','keywords','overview']]
movies_df.head()
데이터가 str형태로 되어있는데, 이것을 literal_eval를 통해서 tuple 형태로 변환해준다. 데이터 수집에 더욱 용이하기 때문이다.
from ast import literal_eval
code = """(1,2,{'foo':'bar'})"""
code타입을 확인해보면
type(code)str이라고 뜰 것이다.
literal_eval(code)
type(literal_eval(code))(1, 2, {'foo': 'bar'})
tuple
str 형태의 데이터를 tuple로 변환시켜주는 방법이였다!
2. 데이터 변환
우선 genres와 keywords의 내용을 list와 dict으로 복구시켜준다.
from ast import literal_eval
movies_df['genres'] = movies_df['genres'].apply(literal_eval)
movies_df['keywords'] = movies_df['keywords'].apply(literal_eval)
movies_df.head()
movies_df['genres'][0] [{'id': 28, 'name': 'Action'},
{'id': 12, 'name': 'Adventure'},
{'id': 14, 'name': 'Fantasy'},
{'id': 878, 'name': 'Science Fiction'}]
dict의 value값을 특성으로 사용하도록 변경한다.
movies_df['genres'] = movies_df['genres'].apply(lambda x :[y['name']for y in x])
movies_df['keywords'] = movies_df['keywords'].apply(lambda x :[y['name']for y in x])
movies_df[['genres','keywords']][:2]
genres의 각 단어들을 하나의 문장(띄어쓰기로 구분된)으로 변환해준다.
movies_df['genres_literal'] = movies_df['genres'].apply(lambda x: (' ').join(x))
movies_df.head()
더불어 문자열로 변환된 genres를 countvectorize 수행한다.
머신러닝을 수행하기 위해 sklearn을 import 한다.
from sklearn.feature_extraction.text import CountVectorizer
count_vect = CountVectorizer(min_df=0, ngram_range=(1,2))
genre_mat = count_vect.fit_transform(movies_df['genres_literal'])
print(genre_mat.shape)(4803, 276)
3. 유사도 측정
문장의 유사도 측정을 하는 방법 중 하나인 코사인 유사도 측정을 수행한다.
from sklearn.metrics.pairwise import cosine_similarity
genre_sim = cosine_similarity(genre_mat, genre_mat)
print(genre_sim.shape)
print(genre_sim[:2])
counfusion_matrix와 비슷하게 해석하면 된다.
genre_sim_sorted_ind = genre_sim.argsort()[:,::-1]
print(genre_sim_sorted_ind[:1])[[ 0 3494 813 ... 3038 3037 2401]]값을 얻을 수 있다.
추천 영화를 DATAFRAME으로 반환하는 함수를 만들어서 사용한다.
def find_sim_movie(df,sorted_ind, title_name, top_n=10):
title_movie = df[df['title']== title_name]
title_index = title_movie.index.values
similar_indexes = sorted_ind[title_index, :(top_n)]
print(similar_indexes)
similar_indexes = similar_indexes.reshape(-1)
return df.iloc[similar_indexes]similar_movies = find_sim_movie(movies_df, genre_sim_sorted_ind, 'The Godfather', 10)
similar_movies[['title','vote_average']]
문제점이 몇 가지 확인된다
1. cote_average가 0인 데이터가 있다?
2. 혹은 한명이 평점을 줬는데 만점을 주는 경우
3. 평점과 평점을 매긴 횟수를 보면 문제 데이터를 확인할 수 있다.
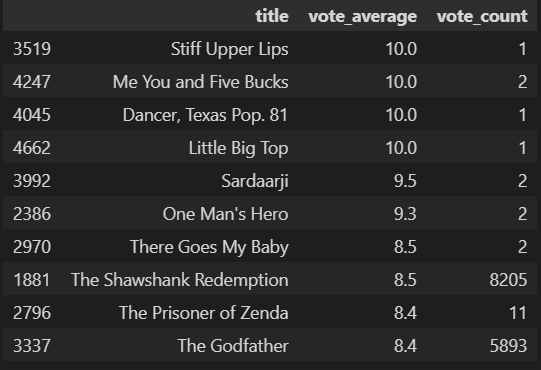
movies_df[['title','vote_average','vote_count']].sort_values('vote_average',ascending=False)[:10]vote_count를 확인해보자
영화 선정을 위한 가중치를 선정
영화 전체 평균평점과 최소 투표 횟수를 60% 지점으로 지정해준다.
c = movies_df['vote_average'].mean()
m = movies_df['vote_count'].quantile(0.6)
print('c :',round(c,3), 'm :', round(m,3))가중치가 부여된 평점을 계산하기 위한 함수
def weighted_vote_average(record):
v = record['vote_count']
r = record['vote_average']
return ((v/(v+m)) * r) + ((m/(m+v)) *c)movies_df['weighted_vote'] = movies_df.apply(weighted_vote_average, axis=1)
movies_df.head()
전체 데이터에서 가중치가 부여된 평점 순으로 정렬한 결과
movies_df[['title','vote_average','weighted_vote','vote_count']].sort_values('weighted_vote',ascending=False)[:10]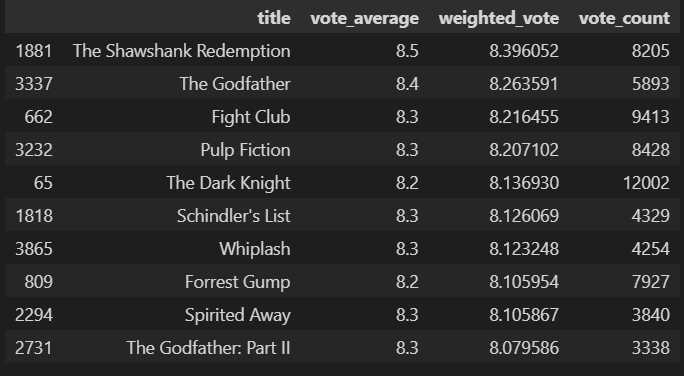
문제점을 해결하는 방법을 정했으니, 유사 영화를 찾는 함수를 다시 변경해주자
def find_sim_movie(df,sorted_ind, title_name, top_n=10):
title_movie = df[df['title']== title_name]
title_index = title_movie.index.values
similar_indexes = sorted_ind[title_index, :(top_n*2)]
similar_indexes = similar_indexes.reshape(-1)
similar_indexes = similar_indexes[similar_indexes != title_index]
return df.iloc[similar_indexes].sort_values('weighted_vote',ascending=False)[:top_n]이후 다시 대부와 유사한 영화 찾기
similar_movies = find_sim_movie(movies_df,genre_sim_sorted_ind,'The Godfather',10)
similar_movies[['title','vote_average','weighted_vote']]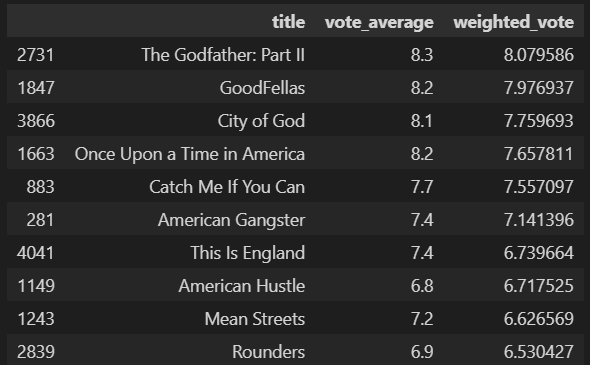
가장 유사도가 높은 영화는 대부2인 것을 볼 수 있다.
이로써 영화 추천시스템을 완성해봤다!
