Pandas에 대해 알아보자
Pandas의 정의
Pandas는 쉽고 직관적인 관계형 또는 분류된 데이터로 작업 할 수 있도록 설계된 빠르고 유연하며 표현이 풍부한 데이터 구조를 제공하는 Python 패키지이다. Python에서 실용적인 실제 데이터 분석을 수행하기 위한 고수준의 객체 형태를 목표로한다. 또한, 어떤 언어로도 사용할 수 있는 가장 강력하고 유연한 오픈 소스 데이터 분석 / 조직 도구가되는 더 넓은 목표를 가지고 있다.
import pandas as pdPandas로 할 수 있는 일
-
Python 자료구조와의 호환(List ,Tuple, Dict, NumpyArray 등)
큰 데이터의 빠른 Indexing, Slicing, Sorting 하는 기능 -
두 데이터 간의 Join(행,열 방향) 기능
-
데이터의 피봇팅 및 그룹핑
-
데이터의 통계 및 시각화 기능
-
외부 데이터를 입력 받아 Pandas 자료구조로 저장 및 출력(CSV, 구분자가 있는 txt, 엑셀데이터, SQL database, XML 등)
Pandas 사용에 적합한 상황
-
부동 소수점 데이터뿐만 아니라 누락 된 데이터(NaN)를 손쉽게 처리
DataFrame 및 상위 차원 개체에서 열을 삽입하고 삭제할 수 있다. -
입력하고자 하는 내용을 레이블 세트에 이름으로 정렬하거나 사용자가 레이블을 무시하고 Series, DataFrame 등으로 자동으로 데이터를 계산에 사용할 수 있다
-
데이터를 집계 및 변환하기 위해 데이터 세트에 분할 적용 및 유연한 그룹 별 기능 가능
-
다른 Python 및 NumPy 데이터 구조의 비정형 색인 생성 데이터를 DataFrame 객체로 쉽게 변환 할 수 있다.
-
지능형 레이블 기반 슬라이싱, 인덱싱 및 대용량 데이터 세트의 하위 집합 가능
-
직관적인 데이터 병합 및 결합 가능
-
데이터 세트의 유연한 재 형성 및 피벗 가능
-
축의 계층적 레이블링 가능
-
플랫 파일(CSV), Excel 파일, 데이터베이스 및 초고속 HDF5 형식의 저장 / 로드 데이터에서 데이터로드를 위한 견고한 IO 도구 포함
날짜 범위 생성 및 빈도 반환, 이동 창 통계, 이동 윈도우 선형 회귀, 날짜 이동 및 지연 사용 가능
[출처: https://1000yun.tistory.com/2 [SW개발 지식 쌓기]]
Pandas의 세 가지의 데이터 구조
-
시리즈(Series)
-
데이터프레임(DataFrame)
-
패널(Panel)
시리즈(Series)
시리즈 클래스는 1차원 배열의 값(values)에 각 값에 대응되는 인덱스(index)를 부여할 수 있는 구조를 갖고 있습니다.
- List를 시리즈 형태로 변환
import pandas as pd
list_data = ['2019-01-02', 3.14, 'ABC', 100, True]
sr = pd.Series(list_data)
print(sr)
print()
idx = sr.index
val = sr.values
print(idx)
print()
print(val)- 튜플을 시리즈 형태로 변환
import pandas as pd
tup_data = ('파이썬', '2021-01-01', '남', True)
sr = pd.Series(tup_data, index=['이름', '생년월일', '성별', '학생여부'])
print(sr)
데이터프레임(DataFrame)
데이터프레임은 2차원 리스트를 매개변수로 전달합니다. 2차원이므로 행방향 인덱스(index)와 열방향 인덱스(column)가 존재합니다. 다시 말해 행과 열을 가지는 자료구조입니다. 시리즈가 인덱스(index)와 값(values)으로 구성된다면, 데이터프레임은 열(columns)까지 추가되어 열(columns), 인덱스(index), 값(values)으로 구성됩니다. 이 세 개의 구성 요소로부터 데이터프레임을 생성해봅시다.
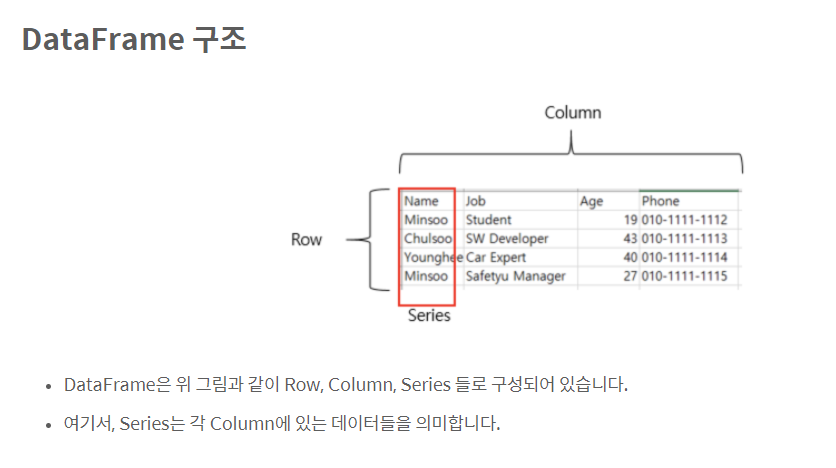
기본 형태
import pandas as pd
df = pd.DataFrame(data, index, columns, dtype, copy)data - DataFrame을 생성할 데이터
index - 각 Row에 대해 Label을 추가 ( 옵션 )
columns - 각 Column에 대해 Label을 추가 ( 옵션 )
dtype - 각 Column의 데이터 타입 명시 ( 옵션 )
생성 예시
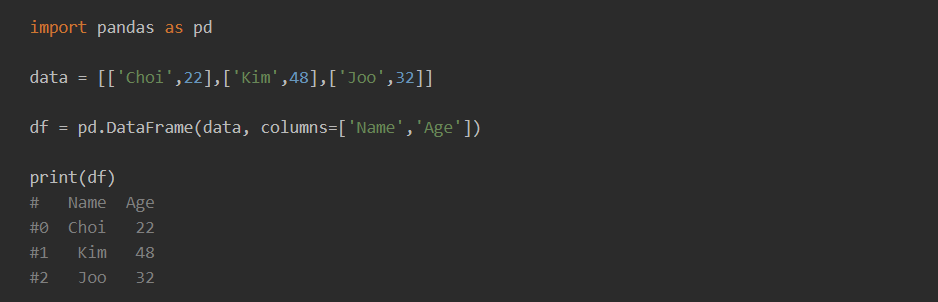
- List를 사용한 DataFrame 생성
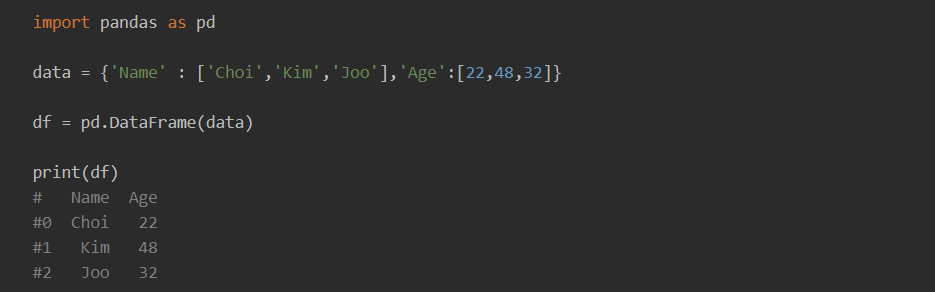
- dictionary를 사용한 DataFrame 생성
-
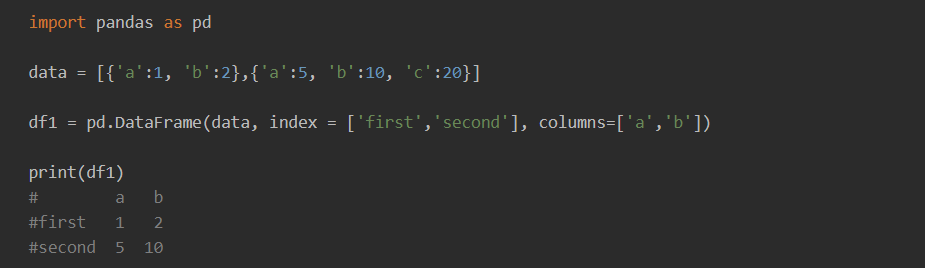
index와 columns을 사용한 DataFrame 생성
-
numpy를 사용한 DataFrame 생성

[이미지 출처 : https://wooono.tistory.com/80]
패널(Panel)
패널은 자주 사용되고 있지 않지만 3차원데이터를 다룰 때 자주 사용된다.
pan (el) -da (ta) -s. 3 축의 이름은 패널 데이터와 관련된 작업, 특히 패널 데이터의 계량 경제 분석을 설명하는 데 의미 적 의미를 부여하기위한 것입니다.
표로 정리

