논문 제목: Distributed Representations ofWords and Phrases and their Compositionality
저자 : Tomas Mikolov, Ilya Sutskever, Kai Chen, Greg Corrado, Jeffrey Dean
Abstract
앞서 소개된 Skip-gram 모델에 대한 내용을 다루고 있으며, 이 모델은 많은 정확한 구문 및 의미 관계를 포착하는 고품질 분산 벡터 표현을 학습하는 효율적인 방법이며, 본 논문에서는 벡터의 품질과 학습 속도를 모두 향상시키는 몇 가지 확장을 제시하고 있습니다. 빈도가 높은 Word를 서브샘플링(subsampling)하여 학습 속도를 크게 높이고, 더 규칙적인 단어 표현을 학습할 수 있었습니다. 또한, 계층적 소프트맥스(hierarchical softmax)를 대체하는 간단한 대안인 네거티브 샘플링(negative sampling)에 대해 설명합니다.
단어 표현의 고유한 한계 중 하나는 단어 순서에 대한 무관심과 관용구를 표현하지 못하는 점입니다. 예를 들어, "Canada(캐나다)"와 "Air(항공)"의 의미를 결합하여 "Air Canada(에어 캐나다)"라는 의미를 쉽게 얻을 수 없습니다. 이러한 예에서 동기를 얻어, 우리는 텍스트에서 구문을 찾는 간단한 방법을 제시하고, 수백만 개의 구문에 대해 좋은 벡터 표현을 학습할 수 있음을 보여줍니다.
Introduction
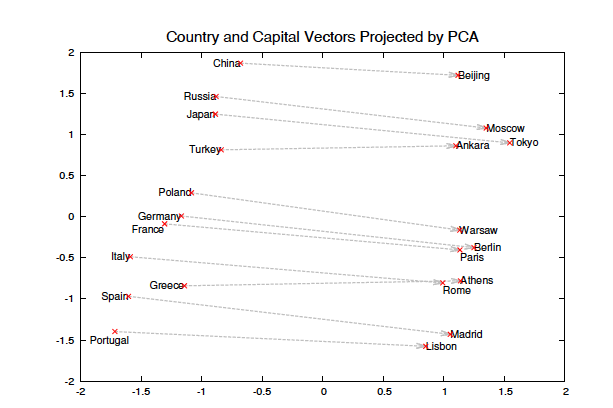
단어의 벡터 분산 표현은 자연어 처리 작업에서 비슷한 단어를 그룹화하여 학습 알고리즘의 성능을 향상시킵니다. Rumelhart, Hinton, Williams가 처음 제안한 이 아이디어는 통계적 언어 모델링과 자동 음성 인식, 기계 번역 등의 다양한 NLP 작업에 성공적으로 적용되었습니다. 최근 Mikolov et al.이 제안한 Skip-gram 모델은 대량의 텍스트 데이터로부터 고품질의 단어 벡터를 효율적으로 학습할 수 있으며, 밀집 행렬 곱셈을 사용하지 않아 학습 속도가 매우 빠릅니다. 또한, 이 모델에서 학습된 벡터는 언어적 규칙과 패턴을 선형 변환으로 나타낼 수 있습니다. 예를 들어, "Madrid" - "Spain" + "France"는 "Paris"에 가까운 벡터를 생성합니다. 논문에서는 기존 Skip-gram 모델의 여러 확장을 다룹니다. 학습 중 자주 사용되는 단어를 서브샘플링하면 속도가 2~10배 빨라지고, 드물게 등장하는 단어의 표현 정확도가 향상됩니다. 또한, 더 복잡한 계층적 소프트맥스 대신 간단한 Noise Contrastive Estimation(NCE)을 사용하여 학습 속도와 자주 등장하는 단어의 벡터 표현을 개선합니다.
Skip-gram 모델은 개별 단어의 조합으로는 표현되지 않는 관용적 구문을 다루지 못하는 한계가 있지만, 구문을 개별 토큰으로 처리함으로써 구문 기반 벡터 표현을 학습할 수 있습니다. 논문에서는 이를 평가하기 위해 단어와 구문을 포함한 유추 추론 작업을 개발했습니다. Montreal": "Montreal Canadiens":: "Toronto": "Toronto Maple Leafs" 입니다. vec("Montreal Canadiens") - vec("Montreal") + vec("Toronto")에 가장 가까운 표현이 vec("Toronto Maple Leafs")일 경우, 이는 정답으로 간주됩니다.또한, 벡터 덧셈이 종종 의미 있는 결과를 낼 수 있음을 발견했으며, 간단한 수학적 연산으로도 단어 벡터를 통해 언어적 이해를 나타낼 수 있음을 보여줍니다. 예를 들어, "Russia" + "river"는 "Volga River"와 가깝고, "Germany" +"capital"은 "Berlin"과 가까운 결과를 제공합니다.
The Skip-gram Model
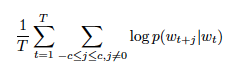
- wT에 대해 Skip-gram 모델의 목표는 평균 로그 확률을 최대화하는 것
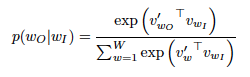
- C 는 training context의 size를 뜻하며, c가 커질수록 학습 결과는 좋아지지만 훈련 소요시간은 커지게 됩니다.
- 기본 Skip-gram model은 softmax를 이용하여 확률을 계산합니다.
Hierarchical Softmax
계층적 소프트맥스(Hierarchical Softmax)는 전체 소프트맥스를 효율적으로 계산하는 방법으로, W개의 출력 노드를 평가하는 대신, 약 𝑙𝑜𝑔2(𝑊)개의 노드만 평가하여 확률 분포를 계산할 수 있으며, 계층적 소프트맥스는 출력층을 이진 트리로 구성하고, 각 노드는 자식 노드들의 상대적 확률을 나타내어 단어에 확률을 할당하는 방식입니다.
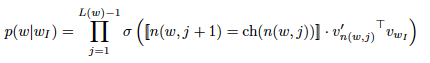
계층적 소프트맥스에서는 각 단어가 트리의 루트에서 해당 단어로 이어지는 경로를 따라 도달하며, 이 경로의 길이를 𝐿(𝑤)로 정의합니다. 이를 통해 단어의 확률 𝑝(𝑤𝑂∣𝑤𝐼)를 계산하며, 계산 비용은 𝐿(𝑤𝑂)에 비례하고 평균적으로 log𝑊보다 크지 않습니다. 또한, 계층적 소프트맥스는 각 단어에 대해 하나의 벡터 표현 𝑣𝑤와 트리의 내부 노드마다 하나의 벡터 𝑣′𝑛을 할당하여 효율적으로 학습을 수행합니다.
Negative Sampling
Noise Contrastive Estimation(NCE)는 계층적 소프트맥스의 대안으로, 로지스틱 회귀를 사용해 데이터와 노이즈를 구분하는 방식입니다. NCE는 소프트맥스의 로그 확률을 대략적으로 최대화하지만, Skip-gram 모델의 목표는 고품질의 벡터 표현을 학습하는 것이므로, NCE를 단순화해도 벡터의 품질만 유지되면 문제없습니다. 이를 바탕으로 Negative sampling(NEG)이 정의되었습니다.
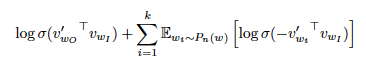
각 데이터 샘플마다 (k)개의 음성 샘플을 사용하여 목표 단어를 노이즈 분포로부터 구별하는 작업을 로지스틱 회귀로 수행하며, 작은 데이터셋에서는 5~20개, 큰 데이터셋에서는2~5개가 효과적이다. NEG와 NCE의 차이점은 NCE가 샘플과 함께 노이즈 분포의 수치 확률을 사용하지만, NEG는 샘플만 사용한다는 점입니다.
✏️ Word2Vec 성능은 아래와 같습니다.
CBOW < Skip-gram < Skip-gram with Negative Sampling(SGNS)
그렇기에 흔히 Word2Vec에서 Skip-Gram방법을 사용한다고 하면 Negative sampleing이 적용된 SGNS를 사용한다고 생각하시면 됩니다.
Subsampling of FrequentWords
큰 말뭉치에서 자주 등장하는 단어들은 정보 가치가 낮고, 드문 단어들에 비해 학습 효과가 적습니다.(예: "in", "the", "a") "France"와 "Paris"의 동시 발생은 Skip-gram 모델에 유익하지만, "France"와 "the"의 관계의 관계성이 낮지만 빈도는 더 큽니다.
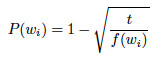
드문 단어와 자주 등장하는 단어의 불균형을 해결하기 위해, 자주 등장하는 단어를 적극적으로 제거하는 서브샘플링 방법을 사용했습니다. 이 방식은 빈도가 특정 임계값을 초과하는 단어들을 더 자주 제외하면서도 빈도 순서는 유지됩니다. 서브샘플링은 학습 속도를 가속화하고 드문 단어의 벡터 정확도를 크게 향상시키는 데 효과적입니다.

Empirical Results
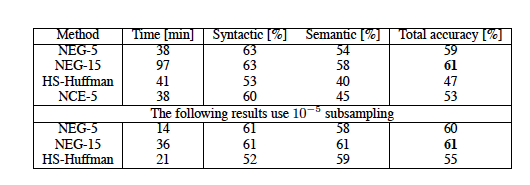
계층적 소프트맥스(HS), Noise Contrastive Estimation(NCE), Negative Sampling, 그리고 자주 등장하는 단어의 서브샘플링을 평가합니다. 유추 추론 작업을 통해, "Germany: Berlin :: France: Paris"와 같은 문제를 해결하는 방식으로 모델의 성능을 측정했습니다. 실험 결과, Negative Sampling이 계층적 소프트맥스(HS)보다 더 높은 성능을 보였고, NCE보다도 약간 더 나았습니다. 자주 등장하는 단어를 서브샘플링하면 학습 속도가 크게 향상되고, 단어 표현의 정확도도 높아졌습니다. Skip-gram 모델의 선형성 덕분에 선형 유추에 더 적합하다는 주장이 있지만, 비선형 모델들도 데이터 양이 많아질수록 성능이 개선되며 선형 구조의 단어 표현을 선호하는 경향이 있음을 확인했습니다.
Learning Phrases
많은 구문은 개별 단어들의 의미를 단순히 결합한 것으로는 설명할 수 없는 의미를 가지고 있습니다. 구문의 벡터 표현을 학습하기 위해, 우리는 먼저 자주 함께 등장하고 다른 문맥에서는 드물게 나타나는 단어들을 찾습니다. 예를 들어, "New York Times"나 "Toronto Maple Leafs"와 같은 구문은 학습 데이터에서 고유한 토큰으로 대체되지만, "this is"와 같은 이그램(bigram)은 그대로 유지됩니다.
이 방식으로 어휘 크기를 크게 늘리지 않으면서도 많은 적절한 구문을 형성할 수 있습니다.매우 빈번하지 않은 단어로 구성된 구는 너무 많습니다. 그렇기에 이 스코어에서 델타(할인 계수)로 너무 많은 구를 방지합니다.
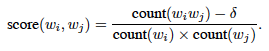
Phrase Skip-Gram Results
Negative Sampling은 𝑘=5로도 괜찮은 성능을 보였지만, 𝑘=15
에서 성능이 크게 향상되었습니다. 또한, 서브샘플링을 적용한 계층적 소프트맥스가 가장 좋은 성능을 보였으며, 서브샘플링이 학습 속도와 정확도를 모두 개선할 수 있음을 확인했습니다.

Additive Compositionality
Skip-gram 모델이 학습한 단어와 구문 벡터는 선형 구조를 가지며, 벡터 산술을 통해 정확한 유추 추론과 단어 결합이 가능합니다. 단어 벡터의 가법적 특성은 문맥 분포와 관련이 있으며, 두 단어 벡터의 합은 두 문맥 분포의 곱과 같아져, 함께 자주 등장하는 단어들의 벡터 합은 그 구문과 가까운 벡터를 생성합니다. 예를 들어, "Russian"과 "river" 벡터의 합은 "Volga River"와 유사한 벡터를 만들어냅니다.

Conclusion
Skip-gram 모델을 통해 단어와 구문의 분산 표현을 학습하는 방법을 보여주었고 , 이러한 표현이 선형 구조를 가져 정확한 유추 추론을 가능하게 함을 입증합니다. 자주 등장하는 단어의 서브샘플링을 통해 학습 속도와 드물게 등장하는 단어의 표현 정확도가 크게 개선되었습니다. 또한, Negative sampling을 이용하여, 자주 등장하는 단어의 표현을 정확하게 학습할 수 있음을 보여줍니다. 단어 벡터를 단순히 더함으로써 의미 있는 결합이 가능하며, 구문을 하나의 토큰으로 표현하는 방법도 제시되었습니다.
📗논문 정리
1.연구 목표
연구의 목표는 Skip-gram 모델을 사용하여 단어와 구문의 분산 표현을 학습하는 방법을 제시하고, 이 표현들이 선형 구조를 가짐으로써 정확한 유추 추론이 가능하다는 것을 입증하는 것
- 연구의 배경지식
분산 단어 표현은 자연어 처리 작업에서 유사한 단어를 그룹화함으로써 성능을 향상시키는 데 중요한 역할을 합니다. Skip-gram 모델을 도입하여 대량의 비정형 텍스트 데이터에서 고품질의 단어 벡터 표현을 학습할 수 있는 방법을 개발
3.중점적으로 볼 것
자주 등장하는 단어의 서브샘플링이 학습 속도를 높이고 드문 단어 표현의 정확성을 크게 개선합니다.
Negative Sampling 알고리즘은 간단하면서도 자주 등장하는 단어에 대한 정확한 표현을 학습할 수 있으며,단어 벡터의 가법적 성질을 통해 단어 벡터를 더하여 의미 있는 결합이 가능함
4.결론
이 연구는 Skip-gram 모델을 사용하여 단어 및 구문 표현의 학습이 가능하며, 특히 대규모 데이터셋에서 고품질의 표현을 학습할 수 있음을 보여주었으며, 자주 등장하는 단어의 서브샘플링과 Negative Sampling 기법은 학습 속도와 정확도를 향상시키는 중요한 요소로 작용함
참고:https://velog.io/@lee9843/Word2Vec-Distributed-Representations-of-Words-and-Phrases-and-their-Compositionality-%EB%85%BC%EB%AC%B8-%EB%A6%AC%EB%B7%B0
https://velog.io/@xuio/NLP%EB%85%BC%EB%AC%B8%EB%A6%AC%EB%B7%B0-Distributed-Representations-of-Words-and-Phrases-and-their-Compositionality
