논문 제목: GloVe: Global Vectors for Word Representation
저자 : Jeffrey Pennington, Richard Socher, Christopher D. Manning
Abstract
벡터 공간 표현을 학습하는 방법들은 벡터 산술을 통해 미세한 의미적, 구문적 규칙성을 포착하는 데 성공했지만, 이러한 규칙성의 기원은 여전히 불투명했습니다. 저자들은 단어 벡터에서 이러한 규칙성이 찾아내기 위해 필요한 모델 속성을 분석했습니다. 그 결과, 문헌에서 두 가지 주요 모델 계열인 global matrix factorization(글로벌 행렬 분해)와 local context window methods(로컬 문맥 창 방법)의 장점을 결합한 새로운 global logbilinear regression model(글로벌 로그-빌리니어 회귀 모델)을 제안합니다. 이 모델은 대규모 말뭉치에서 개별 문맥이나 희소 행렬 전체 대신 단어-단어 공출현 행렬에서 비제로 요소에 대해서만 학습하여 통계 정보를 효율적으로 활용합니다.
✏️GloVe 모델은 word-word co-occurerence를 통해 어떻게 의미(meaning)를 만들 것인지, 결과적으로 word vectors가 어떻게 의미를 표현할 것인지에 집중할 것
Introduction
단어를 실수 값 벡터로 표현하는 의미 벡터 공간 모델을 분석하고, 단어 유추와 유사성 작업에서 더 나은 성능을 내기 위한 방법을 제안합니다. 기존의 글로벌 행렬 분해 방법(LSA)과 로컬 문맥 창 방법(skip-gram)은 각각 통계 정보를 제대로 활용하지 못하거나, 벡터 공간 구조가 최적화되지 않는 단점이 있습니다. 이를 개선하기 위해, 전역 단어 공출현 수를 활용하는 글로벌 로그-빌리니어 회귀 모델을 제안하며, 이 모델은 단어 유추 작업에서 75%의 정확도를 기록하고, 여러 작업에서 최신 방법보다 우수한 성능을 보임
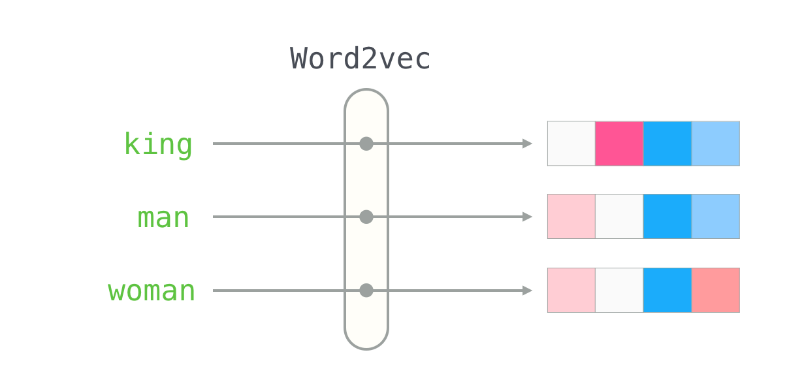
Word2Vec은 window를 사용해 문서 전체가 아니라 중심단어를 둘러싼 주변단어의 실제값과 예측값에 대한 오차를 손실 함수를 통해 줄여나가며 학습하는 예측 기반의 방법론
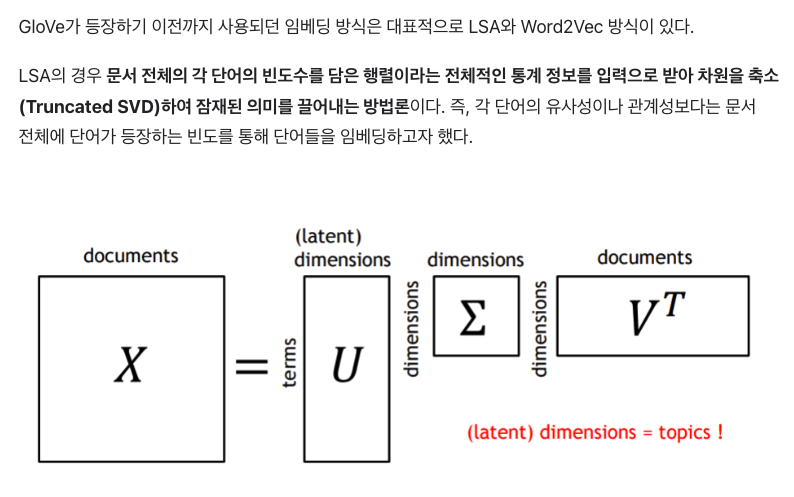
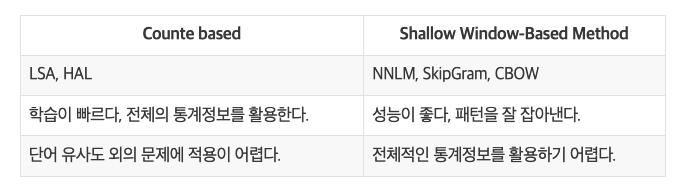
✏️LSA는 카운트 기반으로 코퍼스의 전체적인 통계 정보를 고려하기는 하지만 단어 의미의 유추 작업(Analogy task)에는 성능이 떨어진다. 즉, 임베딩된 단어의 선형대수적 연산 능력이 매우 떨어져 단어간의 관계성 부분을 고려하지 못함
✏️Word2Vec는 예측 기반으로 단어 간 유추 작업에는 LSA보다 뛰어나지만, 임베딩 벡터가 윈도우 크기 내에서만 주변 단어를 고려하기 때문에 코퍼스의 전체적인 통계 정보를 반영하지 못함
Related Work

The GloVe Model
GloVe라는 새로운 단어 표현 모델을 제안하며, 말뭉치에서 단어 간 공출현 통계를 기반으로 의미를 추출하는 방법
📍수학공식 설명
https://velog.io/@xuio/GloVe%EA%B8%80%EB%A1%9C%EB%B8%8C-%EA%B0%9C%EB%85%90%EC%A0%95%EB%A6%ACfeat.-GloVe-Global-Vectors-for-Word-Representation-%EB%85%BC%EB%AC%B8
https://wikidocs.net/22885
Relationship to Other Models
Complexity of the model
Experiments
Evaluation methods
🖍️단어 유추 과제의 결과
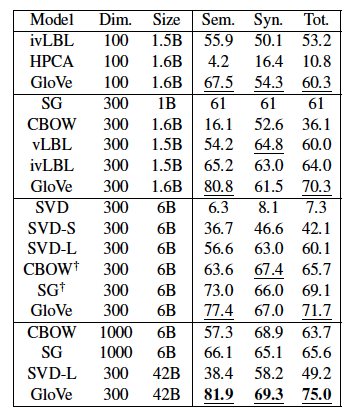
🖍️훈련시간
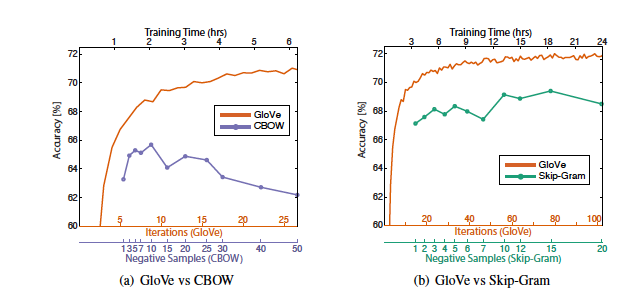
Corpora and training details
🖍️단어 유사성 과제에서의 Spearman 순위 상관 결과
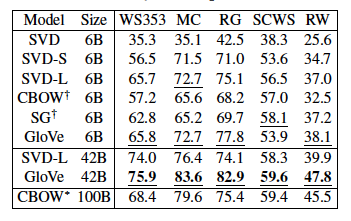
✏️Corpus의 크기가 커진다고 무조건 성능이 좋아진다고 할 수 없다.
Results
🖍️ 개체 인식 NER (Named Entity Recognition) task에 대한 결과
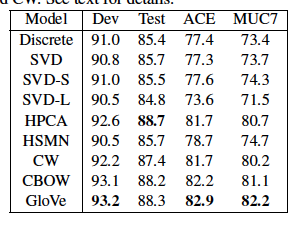
Conclusion
분포적 단어 표현 학습에서 카운트 기반 방법과 예측 기반 방법이 크게 다르지 않다고 주장합니다. 두 방법 모두 말뭉치의 공출현 통계를 사용하지만, 카운트 기반 방법이 전역 통계를 더 효율적으로 포착할 수 있다는 점에 주목합니다. 이를 바탕으로, 카운트 데이터의 이점과 예측 기반 방법의 선형 하위 구조를 결합한 GloVe라는 새로운 전역 로그-빌리니어 회귀 모델을 제안합니다. GloVe는 단어 유추, 단어 유사성, 명명된 개체 인식 작업에서 다른 모델들보다 뛰어난 성능을 보여줌
📗논문 정리
연구 목표:
이 연구의 목표는 단어 벡터 공간에서 미세한 의미적, 구문적 규칙성을 포착하는 새로운 모델인 GloVe(Global Vectors for Word Representation)를 제안하고, 이를 통해 다른 모델들과 비교해 우수한 성능을 입증하는 것
연구의 배경지식:
기존의 단어 벡터 학습 방법에는 글로벌 행렬 분해와 로컬 문맥 창 기반 방법이 있습니다. 그러나 이 두 가지 방법 모두 각각의 한계를 가지고 있습니다. 글로벌 행렬 분해는 통계 정보를 잘 활용하지만 단어 유추 작업에서 성능이 떨어지며, 로컬 문맥 창 방법은 유추 작업에서 더 나은 성능을 보이지만, 전역 공출현 통계를 제대로 활용하지 못함
중점적으로 볼 것:
이 연구에서 주목할 것은 GloVe 모델이 통계 정보를 효율적으로 활용하며, 단어 간의 선형적 의미 관계를 포착하는 능력입니다. GloVe 모델은 공출현 행렬의 비제로 요소만을 학습하여 희소한 데이터를 효율적으로 처리합니다. 또한, 단어 유추와 유사성 작업, 그리고 명명된 개체 인식(NER) 작업에서 뛰어난 성능을 보임
결론:
GloVe 모델은 기존의 예측 기반 및 카운트 기반 모델들이 가지는 한계를 극복하며, 단어 유추, 단어 유사성, NER 등의 다양한 자연어 처리 작업에서 다른 모델들보다 우수한 성능을 발휘합니다. 이를 통해 GloVe가 다운스트림 NLP 작업에서도 유용한 도구임을 입증
참고:https://data-science-hi.tistory.com/33
https://reniew.github.io/23/
https://velog.io/@xuio/GloVe%EA%B8%80%EB%A1%9C%EB%B8%8C-%EA%B0%9C%EB%85%90%EC%A0%95%EB%A6%ACfeat.-GloVe-Global-Vectors-for-Word-Representation-%EB%85%BC%EB%AC%B8
https://wikidocs.net/22885
https://sumim.tistory.com/entry/NLP-%EA%B7%BC%EB%B3%B8-%EB%85%BC%EB%AC%B8-1-GloVe-Global-Vectors-for-Word-Representation
https://misconstructed.tistory.com/40
