논문 제목: Sequence to Sequence Learning with Neural Networks
저자 : Ilya Sutskever, Oriol Vinyals, Quoc V. Le
Abstract
본 논문에서는 DNNs는 어려운 학습 과제에서 우수한 성능을 달성했으나, DNN은 시퀀스를 시퀀스로 매핑하는 데 사용할 수 없다는 문제를 발견했습니다. 이에 저자들은 시퀀스 구조에 최소한의 가정을 두고 시퀀스 학습을 위한 일반적인 엔드 투 엔드(end to end)접근 방식을 제안하였습니다. 저자들의 방법은 입력 시퀀스를 고정된 차원의 벡터로 매핑하기 위해 다층의 Long Short-Term Memory(LSTM)을 사용한 후, 또 다른 깊은 LSTM을 사용하여 그 벡터로부터 목표 시퀀스를 디코딩합니다.WMT'14 데이터셋에서 영어에서 프랑스어로의 번역 작업에서 LSTM이 생성한 번역은 전체 테스트 세트에서 BLEU 점수 34.8을 기록했습니다.또한,LSTM은 단어 순서에 민감하면서도 능동태와 수동태에 상대적으로 불변하는 합리적인 구문 및 문장 표현을 학습했습니다. 마지막으로, 모든 소스 문장의 단어 순서를 뒤집는 것이 LSTM의 성능을 현저히 향상시켰습니다.
Introduction
시퀀스 대 시퀀스(Sequence-to-Sequence, Seq2Seq) 문제에 대한 설명입니다. 시퀀스 문제는 음성 인식, 기계 번역, 질문 답변 등에서 중요하며, 이는 입력과 출력이 고정된 차원의 벡터로 표현되지 않는 경우가 많습니다. 일반적인 DNN(Deep Neural Networks)은 입력과 출력이 고정된 차원일 때만 효율적으로 작동하기 때문에, 이러한 시퀀스 문제에 대한 해결책이 필요합니다.LSTM(Long Short-Term Memory)을 사용하여 시퀀스 대 시퀀스 문제를 해결하는 방법을 제안했습니다. LSTM의 구조는 긴 범위의 시간적 의존성을 학습할 수 있는 능력이 있기 때문에 시퀀스 문제에 적합하며,이 방법은 두 개의 LSTM을 사용하여, 첫 번째 LSTM이 입력 시퀀스를 고정된 차원의 벡터로 인코딩하고, 두 번째 LSTM이 그 벡터로부터 출력 시퀀스를 디코딩하는 방식입니다.
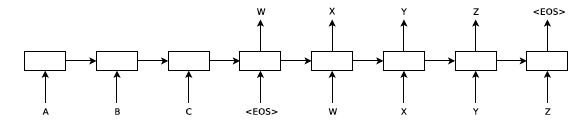
위 그림을 보면 입력으로 "ABC"가 첫 번째 LSTM에 입력되고, 해당 입력에 대한 결과(번역)인 "WXYZ" 가 두 번째 LSTM을 통해서 제공된다. 즉, 두가지의 모델이 순차적으로 실행이 되는 것이다. 그리고 각 문장의 끝은 EOS 라는 토큰으로 구분한다.
The model
RNN의 한계와 확장: RNN은 입력과 출력이 같은 길이일 때 쉽게 시퀀스를 매핑할 수 있지만, 서로 다른 길이를 갖거나 복잡한 관계가 있는 문제에서는 어려움이 있습니다. 이를 해결하기 위한 방법으로 입력 시퀀스를 고정된 크기의 벡터로 매핑한 후, 다른 RNN을 사용하여 목표 시퀀스로 변환하는 방식을 제안합니다.
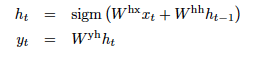
LSTM: LSTM은 장기 의존성을 처리할 수 있는 모델로, 장기 시간적 의존성이 있는 문제에서도 성능이 좋습니다. LSTM은 입력 시퀀스를 고정 차원의 벡터로 인코딩하고, 이를 바탕으로 출력 시퀀스의 확률을 계산합니다. LSTM을 사용하여 문장의 끝을 나타내는 "EOS" 토큰을 포함한 시퀀스를 학습합니다.2개의 LSTM을 이용하는 데 하나는 Encoder 용도, 또 다른 하나는 Decoder 용도(이것을 논문에서는 input과 output으로 각각 표현함)
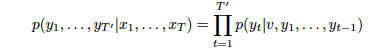
- 입력 시퀀스와 출력 시퀀스에 각각 다른 LSTM을 사용하여 성능을 높였으며, 이를 통해 다중 언어를 학습할 수 있습니다.
- 깊은 LSTM(4층)을 사용하면 얕은 LSTM보다 성능이 더 뛰어납니다.
- 입력 시퀀스를 역순으로 처리하는 것이 성능을 크게 향상시키며, 이는 확률적 경사 하강법을 더 효율적으로 수행하게 해줍니다.
Experiments
번역방법
- SMT(Syntax-based Machine Translation) 시스템 없이 직접 입력 문장을 번역하는 방식
- SMT 시스템의 n-best 목록을 다시 평가하는 방식
데이터셋
- 12백만 문장의 영어-프랑스어 데이터셋을 사용하여 모델을 학습
- 3억 4800만 개의 프랑스어 단어와 3억 400만 개의 영어 단어로 구성됨
- 소스 언어(영어): 가장 빈도 높은 16만 개의 단어 사용
- 타겟 언어(프랑스어): 가장 빈도 높은 8만 개의 단어 사용
- 어휘 범위를 벗어난 단어들은 "UNK" 토큰으로 대체됨
Decoding and Rescoring
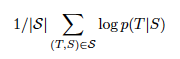
모델은 위와 같이 log 확률(log likelihood)를 최대하하는 방식으로 훈련된다. T는 번역된 정답 시퀀스이고, S는 입력 시퀀스(Source)이며, S'는 Training set이다. 또한 이러한 가능도들의 총합을 최대화시키는 것이 목표이기 때문에 이를 Training set 전체에 해당하는 1 / |S|로 나눈다. 이를 통해 일부 문장만을 너무 정확하게 맞추는 모델보다 평균화된 성능이 높은 거을 유도하고자 했음을 알 수 있다.
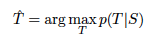
훈련이 완료되면, 모델은 가장 가능성 높은 번역(T)을 찾아서 출력합니다. 이를 위해 저자들은 left-to-right 빔 서치 디코더를 사용했습니다. 이 디코더는 "부분 가정"을 B개의 적은 수로 유지하며, 각 타임스텝에서 이 부분 가정을 확장해 나갑니다. 확장된 가정들이 많아지면, log likelihood에 따라 가장 가능성 높은 B개의 가정만 남기고 나머지는 버립니다. EOS토큰을 만나면 해당 가정을 완성된 번역으로 간주하고, 이를 최종 번역으로 처리하는 방식입니다.
Reversing the Source Sentences
소스 문장을 역순으로 배치하면 성능이 더 좋아졌습니다. 저자들은 이는 데이터셋에 많은 단기 의존성을 도입했기 때문이라고 추측되며, 소스 문장과 타겟 문장 간의 최소 시간 지연이 감소하게 됩니다.소스 문장을 역순으로 배치하면 소스 언어의 첫 몇 단어가 타겟 언어의 첫 몇 단어와 더 가까워지면서 학습이 더 쉬워집니다.이는 역전(backpropagation)가 소스와 타겟 간의 연결을 더 쉽게 확립하게 해줍니다.
Training detail
- 4층의 Deep LSTM 사용, 각 층에 1000개의 셀과 1000차원의 단어 임베딩
- 입력 어휘는 16만 단어, 출력 어휘는 8만 단어로 구성
- 모델은 총 3억 8400만 개의 파라미터를 가짐.
- 파라미터는 -0.08과 0.08 사이의 균등 분포로 초기화
- 확률적 경사 하강법(SGD) 사용, 학습률은 초기 0.7로 설정하고 에포크에 따라 학습률 감소
- 배치 크기는 128개의 시퀀스, 총 7.5번의 에포크 동안 훈련
Parallelization
- 너무 느려서 8개의 GPU로 병렬 처리
Conclusion
연구는 제한된 어휘를 사용한 대형 딥 LSTM 모델이 표준 SMT 기반 시스템을 능가할 수 있음을 보여줍니다. 제한된 어휘를 가진 LSTM이 대규모 기계 번역(MT) 작업에서 무제한 어휘를 가진 SMT 시스템보다 더 나은 성능을 발휘했으며, 특히 소스 문장의 단어를 역순으로 배치했을 때 성능이 크게 향상된 점이 주목할 만합니다. 이는 단기 의존성을 강조하는 문제 인코딩이 학습을 더 쉽게 만들기 때문으로 분석되었습니다. 또한, 표준 RNN은 역순이 아닌 번역 문제에서는 학습이 어렵지만, 소스 문장이 역순일 때는 RNN도 훈련할 수 있을 것으로 예상됩니다. LSTM은 긴 문장에서 제한된 메모리로 인한 성능 저하 없이 훌륭한 번역 능력을 보여주었습니다. 기존 연구에서는 긴 문장에서 LSTM의 성능이 저하된다고 보고되었지만, 이번 연구에서는 역순 데이터셋을 사용했을 때 LSTM이 긴 문장을 번역하는 데 어려움을 겪지 않았습니다. 단순한 LSTM 기반 접근 방식이 SMT 시스템을 능가한 만큼, 추가적인 연구를 통해 번역 정확도를 더 높일 가능성이 큽니다. 이러한 결과는 다른 시퀀스 대 시퀀스 문제에서도 LSTM이 매우 유망한 모델임을 시사합니다.
📗논문 정리
1.연구 목표
이 연구의 목표는 입력 시퀀스를 고정된 차원의 벡터로 인코딩한 후, 그 벡터에서 출력 시퀀스를 추출하는 새로운 end-to-end 방식의 시퀀스 학습 방법을 제시하는 것입니다. 이 방법은 시퀀스 구조에 대한 최소한의 가정을 사용하여, 다양한 시퀀스 문제를 해결할 수 있는 일반적인 솔루션을 제공하는 것을 목표로 합니다.
2.연구의 배경지식
DNNs는 음성 인식 및 이미지 인식과 같은 복잡한 문제에서 우수한 성능을 보여왔습니다. 그러나 DNN은 고정된 차원의 입력과 출력을 필요로 하기 때문에 시퀀스와 같은 가변 길이 데이터를 처리하는 데 한계가 있습니다. 이 논문은 이 문제를 해결하기 위해, 장기 의존성을 학습할 수 있는 LSTM(Long Short-Term Memory) 구조를 사용하여 시퀀스 문제를 처리할 수 있는 방법을 제안합니다.
3.중점적으로 볼 것
LSTM의 구조: 입력 시퀀스를 읽어 고정된 벡터 표현을 생성하고, 또 다른 LSTM을 사용해 그 벡터에서 출력 시퀀스를 예측합니다.
데이터 처리 방식: 소스 문장을 역순으로 처리하여, 짧은 시간 의존성을 증가시키고 최적화를 쉽게 만듭니다.
훈련 및 테스트 성능: WMT'14 영어-프랑스어 번역 작업에서 LSTM이 기존의 통계적 기계 번역(SMT) 시스템보다 높은 BLEU 점수를 기록했습니다.
4.결론
연구 결과, 제한된 어휘를 사용하는 대형 딥 LSTM이 거의 문제 구조를 가정하지 않음에도 불구하고, 대규모 기계 번역 작업에서 무제한 어휘를 사용하는 SMT 시스템을 능가하는 성과를 보였습니다. 이는 LSTM 기반의 접근 방식이 충분한 데이터가 있는 경우 다른 시퀀스 학습 문제에서도 효과적일 수 있음을 시사합니다. 특히 소스 문장을 역순으로 배치했을 때 성능이 크게 향상된다는 점은 이 접근 방식의 중요한 기술적 기여입니다.
참고:https://mountain96.tistory.com/41
https://miinkang.tistory.com/23
https://velog.io/@nawnoes/%EC%9E%90%EC%97%B0%EC%96%B4%EC%B2%98%EB%A6%AC-Beam-Search
https://velog.io/@xuio/NLP-%EB%85%BC%EB%AC%B8%EB%A6%AC%EB%B7%B0-Sequence-to-Sequence-Learning-with-Neural-Networks
https://velog.io/@robert_1106/%EB%85%BC%EB%AC%B8%EB%A6%AC%EB%B7%B0-Sequence-to-Sequence-Learning-with-Neural-Networks
https://m.blog.naver.com/kisooofficial/223040394090
논문링크:https://arxiv.org/abs/1409.3215
